Czym jest i jakie znaczenie ma średnie obciążenie systemu?
10 Jun 2020
bsd kernel linux load load-average performance processes system
Jedną z najważniejszych i najbardziej wartościowych miar ilości obliczeniowej, jaką jest w stanie wykonać jednostka centralna lub system, jest obciążenie (ang. load). Najprościej mówiąc, niskie jest pożądane, zaś wysokie niepożądane. Z tego powodu prawidłowe funkcjonowanie systemu oraz utrzymanie odpowiedniego obciążenia ma krytyczne znaczenie dla każdego serwera. Jeśli wymagania dotyczące działających programów powodują, że żądają one nadmiernych zasobów, może to prowadzić do niskiej wydajności i niestabilności całego systemu.
W tym wpisie chciałbym przedstawić, czym jest średnie obciążenie (ang. load average), jak należy je interpretować oraz jakie ma znaczenie podczas pracy. Te trzy tajemnicze (i bardzo często zwodnicze) liczby to tak naprawdę najczęstszy parametr, który ma różne definicje i różną interpretację, a co najważniejsze, od którego zaczyna się analizę i rozwiązywanie problemów z wydajnością. Głównie odniosę się do implementacji średniego obciążenia w systemach z jądrem Linux, jednak także pozwolę sobie na wstawki dotyczące systemów BSD (czy ogólnie systemów UNIX).
Jaki jest cel tych trzech ciekawych średnich obciążeń i co dokładnie próbują powiedzieć administratorowi? Czy warto brać je pod uwagę w przypadku diagnozy problemów i ich rozwiązania? Na te i na inne ważne pytania postaram się odpowiedzieć w tym artykule.
Obciążenie systemu #
Aby zrozumieć, co mówią nam wartości średniego obciążenia (i kiedy należy się niepokoić), najpierw musimy zrozumieć, co oznacza, że system jest obciążony.
W systemach typu UNIX, obciążenie systemu można określić jako sumę liczby zadań aktualnie uruchomionych na procesorach i długości kolejki uruchamiania, tj. długość kolejki procesów oczekujących na uruchomienie (ang. on run queue). Zasadniczo jest to liczba procesów aktywnych (co nie znaczy, że aktualnie wykorzystujących procesor) w danym momencie, które są przetwarzane tak wydajnie jak to tylko możliwe, np. bez strat spowodowanych przełączaniem kontekstu (ang. context switching). Im kolejka jest dłuższa, tym obciążenie większe, im krótsza, tym obciążenie mniejsze. Idąc za tym, każdy proces, który wykorzystuje lub oczekuje na zasoby jednostki centralnej, dodaje pewną wartość do ogólnej wartości obciążenia.
Przedstawię to na przykładzie (oczywiście w dużym uogólnieniu): w stanie bezczynności obciążenie wynosi 0, natomiast tuż po uruchomieniu danego procesu obciążenie jest zwiększane o 1. Analogicznie, w przypadku zakończenia procesu obciążenie zmniejsza się o 1. Poza uruchomionymi procesami liczony jest również każdy proces umieszczony w kolejce. Tak więc, gdy jeden proces aktywnie korzysta z procesora, a cztery czekają na swoją kolej, obciążenie wynosi 5. Ogólnie rzecz biorąc, jeśli jeden proces działa na 100% i tak po prostu trwa w nieskończoność, możemy oczekiwać, że wszystkie wartości obciążenia zbliżą się do wartości równej 1.
Obciążenie a polityka planowania #
Jeśli w systemie z jednym procesorem jest wiele procesów, działają one pozornie równolegle. Jądro jest na tyle inteligentne, że stara się współdzielić zasoby systemowe w celu uzyskania optymalnej wydajności. Dlatego gdy jądro przyznaje procesowi np. 10 milisekund (jądro może przydzielić mniejszą lub większą ilość czasu w zależności od wykorzystanej techniki planowania i może to zależeć także od bieżącego obciążenia), a następnie przerywa jego działanie, to w następnej kolejności daje kolejne 10 milisekund na inny proces.
Dla procesora o taktowaniu 2,6 GHz, 10 ms to wystarczający czas na wykonanie około 25 milionów instrukcji (przyjmując, że jeden cykl to jedna instrukcja, oczywiście chodzi mi bardziej o wyobrażenie sobie tej ogromnej ilości). To więcej niż wystarczający czas przetwarzania dla większości cykli aplikacji. Należy także wiedzieć, że proces ze szczeliną czasową np. 100 milisekund nie musi działać przez 100 milisekund za jednym razem. Zamiast tego proces może przebiegać w pięciu różnych harmonogramach po 20 milisekund, tak aby optymalnie wykorzystać dostępny czas — w przeciwnym razie grozi to utratą pozostałej szczeliny czasowej, która została mu przydzielona.
To, który proces otrzymuje czas procesora (czyli ustalony wycinek czasu) oraz jest wybierany z odpowiednich kolejek zadań, rozwiązywane jest za pomocą mechanizmu planowania (szeregowania) zadań i odpowiedniej polityki planowania odpowiedzialnej za zarządzanie większością obciążeń. W tym krótkim czasie procesowi przypisuje się na wyłączność procesor, na którym uruchamiane są instrukcje. W większości przypadków proces rezygnuje z kontroli, zanim upłynie określony dla niego wycinek czasu z powodu wywołań I/O lub komunikacji z jądrem.
Oczywiście nie jest to jedyna funkcja algorytmu szeregowania, którego rola sprowadza się także do innych bardzo istotnych czynności podczas pracy z procesami:
- maksymalizacja wykorzystania procesora
- uruchamianie jak największej liczby procesów w danym przedziale czasu
- utrzymywanie kolejek zadań dla każdego procesora
- odpowiednie szeregowanie procesów w architekturach wieloprocesorowych
- zapobieganie jakiejkolwiek dominacji czasu procesora przez dany proces
Planowanie w jądrze Linux opiera się na technice dzielenia czasu, ponieważ czas procesora jest podzielony na segmenty (tzw. kwanty czasu), po jednym dla każdego uruchomionego procesu. System operacyjny śledzi stan każdego procesu, i tak, pojedynczy procesor może uruchomić tylko jeden proces w danym momencie. Jeśli aktualnie uruchomiony proces nie zostanie zakończony, gdy upłynie jego przedział czasowy, może nastąpić zmiana procesu, najczęściej na podstawie ich priorytetów. Ponadto, jądro pozwala procesom o wyższym priorytecie działać zarówno wcześniej, jak i dłużej, na przykład, jeśli proces nie jest zablokowany i znajduje się w kolejce czasu rzeczywistego (ang. real time queue).
W systemie Linux priorytet procesu jest dynamiczny. Program planujący śledzi przebieg procesów i okresowo dostosowuje ich priorytety. W ten sposób procesy, którym odmówiono użycia procesora przez długi czas, są przyspieszane poprzez dynamiczne zwiększanie ich priorytetu. Odpowiednio procesy działające przez długi czas są karane przez zmniejszenie ich priorytetu.
Zasadniczo jądro powinno zużywać jak najmniej czasu procesora — jądro nie jest dostępne dla aplikacji, które użytkownik chce uruchomić. W rezultacie niewiele myśli poświęcono optymalizacji pracy po stronie jądra wymagającej dużej ilości procesora. Jednak jądro czasami musi podejmować zadania intensywnie wykorzystujące procesor, takie jak inicjowanie dużej ilości pamięci znajdującej się w obecnych systemach. Pewną próbą ulepszenia sposobu, w jaki jądro obsługuje takie zadania, jest podsystem ktask opublikowany przez Daniela Jordana.
Domyślny program planujący, zaimplementowany w jądrze Linux, o nazwie Completely Fair Scheduler (CFS), dokłada wszelkich starań, aby podzielić dostępny czas procesora między rywalizujące procesy, utrzymując wykorzystanie procesora w każdym z nich w takim samym przybliżeniu. Co ciekawe, nie będzie on jednak nalegał na równe wykorzystanie zasobów, gdy dostępny jest wolny czas procesora — zamiast pozwolić procesorowi na bezczynność, rozdzieli on dostępny czas procesom, które mogą z niego skorzystać, nawet jeśli tego nie chcą.
Wracając do czasu, który przydzielany jest procesom, to domyślny przedział jest ważny, ponieważ jeśli będzie zbyt długi, system będzie wydawał się nie reagować, jeśli będzie zbyt krótki, system stanie się mniej wydajny, ponieważ procesor spędzi więcej czasu na wykonywaniu przełączania kontekstu między procesami — czyli przekazania kontroli nad procesorem od jednego procesu do drugiego, co samo w sobie jest dosyć czasochłonnym zadaniem. Każdy taki wycinek czasu pozwala procesowi na wykonanie całkiem sporej ilości obliczeń i rzeczywiście większość procesów może zakończyć swoje aktualne prace w ramach pojedynczego wycinka.
Natomiast przełączanie zadań ma tutaj istotne znaczenie i jest potrzebne w wielu przypadkach, jednymi z nich są:
- kiedy skończy się przedział czasu przypisany procesowi, jądro musi wtedy dać dostęp do jakiegoś innego zadania
- kiedy proces decyduje się na dostęp do zasobu, przechodzi w stan uśpienia, więc jądro musi wybrać inne zadanie
Oczywiście jądro przypisuje część procesora do procesu, a nie do ustalonego przedziału czasu. Oznacza to, że przedział czasu dla każdego procesu jest proporcjonalny do bieżącego obciążenia i ważony wartością priorytetu procesu. Tak działa domyślny program planujący dla jądra Linux (o którym już delikatnie wspomniałem). Więcej na ten temat możesz przeczytać w artykule CFS: Completely fair process scheduling in Linux. W celu pogłębienia wiedzy o tej technice planowania, jak i o pozostałych tajnikach jądra, zerknij do dokumentu CS Notes - Process scheduling, który wyjaśnia wszystko w bardzo przystępny sposób.
I tutaj dochodzimy do pewnej ciekawej kwestii. Co z procesami, które są zablokowane lub czekają na jakieś dane? Oczywiście są one w pewnym sensie zwolnione z harmonogramu zadań zarządzanego przez systemowego planistę, ponieważ nie potrzebują czasu procesora (na pewno nie tyle ile procesy wykorzystujące aktualnie czas procesora). Nie oznacza to jednak, że program planujący kompletnie zapomina o takich procesach, np. oznacza je jako procesy przechodzące w stan uśpienia, tak samo, jeśli cykl snu się kończy, program planujący przenosi proces do stanu gotowości do uruchomienia. Sytuacja w systemie z wieloma procesorami jest bardziej złożona. Istnieje wiele procesorów, których ramy czasowe można przypisać do wielu procesów. To sprawia, że planowanie zadań jest nieco — ale nie za bardzo — skomplikowane.
Biorąc to wszystko pod uwagę, możemy powiedzieć, że obciążenie określa, ile procesów oczekuje obecnie na następny czas, jaki jest przydzielany procesom przez mechanizm planowania zadań w systemie.
Stany procesów #
Zatrzymajmy się na chwilę i pomówmy o stanach procesów. Aby zarządzać procesami, jądro musi mieć jasny obraz tego, co robi każdy proces (czyli to, w jakim jest stanie). Musi też wiedzieć, jaki jest priorytet procesu, czy proces jest uruchamiany na procesorze, czy blokowany na jakimś zdarzeniu lub jaka przestrzeń adresowa została mu przypisana. Odpowiedzialny za to jest deskryptor procesu lub inaczej blok kontrolny procesu (ang. PCB - Process Control Block), który opisuje bieżący stan procesu i definiuje pola zawierające wszystkie informacje związane z danym procesem (jest magazynem informacji o danym procesie).
Stan procesu opisuje, co dzieje się w danej chwili z procesem i jest oznaczony za pomocą flag. Jak wiemy, tylko jeden proces może działać jednocześnie na jednym procesorze. Wszystkie inne procesy muszą jednak czekać lub zostać przeniesione w inny stan. Oczywiście, program planujący umożliwia uruchamianie wielu aplikacji, wchodząc i wychodząc z procesów, przydzielając im trochę czasu i w tym sensie mówimy, że wiele procesów jest uruchomionych lub wykonywanych jednocześnie.
Proces uruchomiony (aktualnie wykorzystujący zasoby procesora) przechodzi w stan uruchomienia:
- Running (R) - są to uruchomione procesy w przestrzeni użytkownika lub w przestrzeni jądra, które korzystają obecnie z rdzenia procesora
Natomiast proces, który nie jest uruchomiony (ang. a not-running process), czyli pozbawiony procesora, ma ustawiony jeden z poniższych stanów:
-
Runnable (R) - są to procesy, które mają wszystko, co jest potrzebne do ich uruchomienia, z wyjątkiem procesora, na który muszą czekać
-
Interruptible sleep (S) - są to procesy oczekujące na dostępność jakiegoś zasobu (np. I/O), proces w tym stanie „wybudzi” się, aby obsłużyć jakiś sygnał (np. SIGKILL)
-
Uninterruptible sleep (D) - podobnie jak wyżej, są to procesy oczekujące na dostępność jakiegoś zasobu, jednak w przeciwieństwie do procesów w stanie D, nie „wybudzą” się one w celu obsłużenia sygnału (procesy takie najczęściej oczekują na zakończenie operacji I/O) aż do momentu, zanim nie zaczną działać
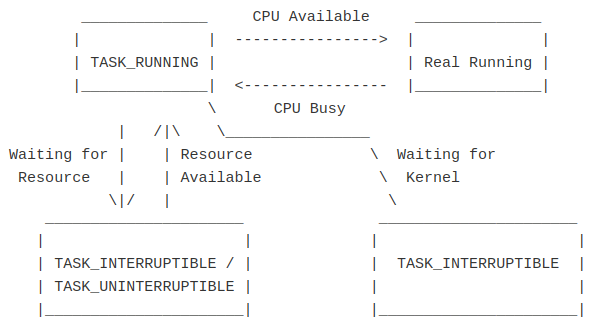
Są to cztery najbardziej istotne flagi, zdefiniowane dla jądra Linux. Ponadto spójrz na poniższy opis przepływu obsługi procesów i odpowiadających im stanom:

Pole stanu deskryptora procesu opisuje aktualny stan procesu i zaraz po uruchomieniu, przypisuje procesowi stan TASK_RUNNING co oznacza nie mniej, nie więcej, że proces jest obecnie uruchomiony, czyli najczęściej w stanie Running (R), lub gotowy do uruchomienia, czyli w stanie Runnable (R). Tak naprawdę TASK_RUNNING nie oznacza jeszcze, że proces jest ustawiony na wykonanie, ale oznacza raczej, że proces jest gotowy do uruchomienia, jednak my także przyjmiemy interpretację, która za pomocą TASK_RUNNING definiuje te dwa stany. Ogólnie rzecz biorąc, jądro szukając nowego procesu do uruchomienia na procesorze, musi brać pod uwagę tylko procesy możliwe do uruchomienia.
Ilość procesów w stanie TASK_RUNNING przechowywana jest w zmiennej procs_running w pliku /proc/stat i jej wartość możesz podejrzeć za pomocą polecenia:
awk '/procs_running/ { print $2 }' /proc/stat
Bardzo często procesami, które są w takim stanie, są procesy ograniczone przez dostęp do procesora (częściej niż inne wykonują jakieś obliczenia). Spędzają one znacznie więcej czasu na obliczeniach wykonywanych przez jednostkę centralną i nie potrzebują zbyt wielu operacji I/O.
Ważne jest, aby zdawać sobie sprawę z tego, że w danej chwili na dowolnym procesorze tylko jeden proces może być aktywny, a wiele procesów może być gotowych do działania lub po prostu czekać. Istotne jest też, że proces wędruje między różnymi kolejkami przez cały czas swego istnienia.
Wspomnę jeszcze o jednej ważnej rzeczy. Moim zdaniem, dyskutując o średnich obciążeniach, należy interpretować termin Running (R) w najwęższym sensie — to znaczy, że jest to stan, w którym proces faktycznie wykorzystuje czas procesora w danym momencie. Pamiętaj, że wielozadaniowy system operacyjny zapewnia pewną iluzję dedykowanego procesora. W rzeczywistości wiele procesów jest ciągle zamienianych i wyłączanych z wykonania na pojedynczym rdzeniu procesora. Zauważ, że procesy, które są uruchomione, a procesy gotowe do uruchomienia (które po prostu aktualnie nie działają) są w jądrze Linux (zerknij na diagramy w rozdziale Średnie obciążenie w systemach BSD) połączone do tego samego stanu.
To, w jakim proces jest stanie, zależy głównie od dostępności zasobów oraz od zdarzeń, które mogą wystąpić po uruchomieniu lub w trakcie pracy procesu. Proces może utworzyć nowy podproces i oczekiwać na jego zakończenie, może też wywołać przerwanie i w konsekwencji zostać przeniesionym do kolejki oczekiwania a może też oczekiwać na zakończenie operacji I/O, na które złożył zamówienie.
Proces może mieć dostęp do wszystkich zasobów, których potrzebuje do uruchomienia z wyjątkiem procesora, który aktualnie jest niedostępny np. z powodu obsługi innych procesów. Proces taki może wcale nie potrzebować procesora, ponieważ zajmuje się czym innym, np. operacjami I/O. Oczywiście w tym czasie procesor może skutecznie wykonywać inne czynności lub wykorzystywać do tego pozostałe dostępne rdzenie. Jednak gdy proces zakończy operację I/O, generuje i wysyła sygnał, a program planujący utrzymuje ten proces w kolejce uruchamiania, przenosząc go w stan Runnable (R). Gdy procesor stanie się dostępny i zostaną spełnione dodatkowe warunki (takie jak odpowiedni priorytet), proces ten przejdzie w stan Running (R).
Podczas działania, proces może przejść w tryb uśpienia (albo za pomocą jądra, albo samemu, np. za pomocą funkcji schedule(), która może być wykorzystana przez proces do dobrowolnego wskazania programowi planującemu, że może on zaplanować inny proces na procesorze), zwłaszcza gdy potrzebuje zasobów, które są dla niego obecnie niedostępne.
Podczas zmiany stanu aktualnie wykonywanego procesu ze TASK_RUNNING na stan TASK_INTERRUPTABLE z wykorzystaniem funkcji schedule(), powinna ona po prostu zaplanować inny proces. Ale dzieje się tak tylko wtedy, gdy stan zadania to TASK_RUNNING. Gdy powyższa funkcja jest wywoływana ze statusem TASK_INTERRUPTABLE lub TASK_UNINTERRUPTABLE, wykonywany jest dodatkowy krok: aktualnie wykonywany proces jest przenoszony z kolejki uruchomień przed zaplanowaniem innego procesu. Efektem tego jest to, że proces wykonawczy przechodzi w tryb uśpienia, ponieważ nie znajduje się już w kolejce uruchamiania. Stąd prosty wniosek, że harmonogram dla takiego procesu nie jest nigdy (przeważnie) planowany, o czym wspomniałem zresztą wcześniej.
Przejście w stan uśpienia mówi o jednej ważnej rzeczy, że proces rezygnuje lub zostaje pozbawiony dostępu do procesora. Powoduje to, że CPU zawiesza proces i kontynuuje wykonywanie innych procesów, aż do zakończenia cyklu uśpienia. Po zakończeniu cyklu uśpienia program planujący przesuwa proces do stanu gotowości do uruchomienia.
Jak już wspomniałem wyżej, mamy dwa rodzaje stanów uśpienia. Przerywany stan uśpienia, nazwany TASK_INTERRUPTABLE (S), oznacza, że proces czeka najprawdopodobniej na wystąpienie określonego zdarzenia, np. kiedy jądro wykonuje coś (głównie operacje I/O), o które prosi proces. Podczas gdy sam proces jest faktycznie bezczynny (śpi), jądro jest zajęte w imieniu procesu (oczywiście może być tak, że proces jak i jądro oczekują na pewne operacje, zaś inne procesy i fragmenty jądra mogą być w tym czasie wykonywane). Gdy to nastąpi, proces wyjdzie z tego stanu i przejdzie w stan gotowości do uruchomienia. Ten stan jest preferowanym sposobem uśpienia, chyba że występuje sytuacja, w której sygnały nie są w ogóle obsługiwane tak jak w przypadku operacji dyskowych lub sieciowych.
Proces może także przejść w stan nieprzerwanego uśpienia, określony jako TASK_UNINTERRUPTABLE (D), podczas którego wybudzi się najczęściej wtedy, kiedy zasób, na który czeka, stanie się dla niego dostępny (lub niekiedy po przekroczeniu limitu czasu oczekiwania). Stan ten jest zazwyczaj używany podczas nietypowej aktywności powodującej oczekiwanie na operacje I/O. Przykład sytuacji z życia: kiedy odłączysz serwer NFS, podczas gdy inne maszyny mają otwarte połączenia do niego.
Proces jest wprowadzany w nieprzerwany sen, gdy musi na coś czekać i nie powinien obsługiwać sygnałów podczas oczekiwania. Oznacza to, że procesy w tym stanie generalnie nie mogą zostać zabite przez odpowiedni sygnał, ponieważ ich nie obsługują. Spotkałem się jednak z różnymi definicjami na ten temat, dlatego myślę, że nie mogą zostać zabite natychmiast lub w niektórych przypadkach w ogóle (potwierdzeniem tej drugiej tezy będzie przykład, w którym sami wygenerujemy takie procesy, których nie będzie można zakończyć za pomocą polecenia kill i dostępnych sygnałów).
Procesy będące w jednym z tych dwóch stanów częściej niż pozostałe zgłaszają zapotrzebowanie na operacje I/O i znacznie częściej je wykonują. Nie zgłaszają one zazwyczaj zbyt często zapotrzebowania na procesor i nie są ograniczone czekaniem, aż zwolnią się jego zasoby. Należy jednak wyłapać różnice: stan przerywany dotyczy zadań, które „śpią” (faktycznie nic nie robią), natomiast nieprzerwane zadania zwykle czekają na zasobie systemowym — takim jak dysk lub inny podsystem I/O.
Co istotne, w trybie przerywanym proces może zostać obudzony w celu przetworzenia sygnałów. W nieprzerwanym trybie uśpienia proces nie może zostać obudzony inaczej niż poprzez wydanie jawnego trybu wznowienia, który jest najczęsciej po za kontrolą administratora.
Relację między tymi stanami można przedstawić za pomocą poniższego diagramu:
Stan nieprzerwanego uśpienia, w jakim znajduje się proces, jest jedną z ciekawszych cech systemów Unix. Stan ten jest szczególny, ponieważ jądro może ustawić go na danym procesie podczas wykonywania przez niego niektórych wywołań systemowych, przez co jest on blokowany i nie może zostać przerwany za pomocą sygnału, dopóki operacje, na które czeka, nie zostaną zakończone (musi zostać jawnie wznowiony). Jedną z wad takiego zachowania jest to, że proces może utknąć w tym stanie na wieczność. Rozwiązaniem jest zazwyczaj ponowne uruchomienie systemu (spotkałeś się zapewne nie raz z zawieszonym procesem serwera NFS, który potrafi się zablokować, więc wiesz, o czym mówię), ponieważ jak wspomniałem, procesy takie są odporne na wysyłane sygnały przez jądro.
Istnieje jednak pewien kompromis, który rozwiązany został przez dodanie do jądra Linux nowego stanu: TASK_KILLABLE. Zachowuje się on podbnie jak TASK_UNINTERRUPTIBLE z wyjątkiem tego, że może zostać przerwany przez jeden z sygnałów krytycznych, powodujących zabicie procesu. Na temat tego oraz pozostałych stanów w jakim mogą znajdować się procesy poczytasz w artykule TASK_KILLABLE: New process state in Linux.
Porozmawialiśmy o stanach procesów nie bez powodu, ponieważ pojawia się tutaj pewna istotna kwestia związana ze stanami procesów oraz średnim obciążeniem. Mianowicie, chodzi o stan nieprzerwanego uśpienia, który w niektórych implementacjach wliczany jest do ogólnego średniego obciążenia. Na przykład systemy z jądrem Linux prezentują takie podejście w przeciwieństwie do systemów BSD, które tego nie robią. Niestety, informacji, dlaczego tak się dzieje, można znaleźć niewiele, większość artykułów w ogóle nie porusza tego wątku. Dlatego wróćmy może do początku i spójrzmy, co napisał o stanie nieprzerwanego uśpienia Matthias Urlichs (źródło: Linux Load Averages: Solving the Mystery - The origin of uninterruptible), autor tej koncepcji, tj. poprawki do (nieintuicyjnego według autora) mechanizmu, który zliczał wartości średniego obciążenia:
The kernel only counts "runnable" processes when computing the load average. I don't like that; the problem is that processes which are swapping or waiting on "fast", i.e. noninterruptible, I/O, also consume resources. It seems somewhat nonintuitive that the load average goes down when you replace your fast swap disk with a slow swap disk... Anyway, the following patch seems to make the load average much more consistent WRT the subjective speed of the system. And, most important, the load is still zero when nobody is doing anything.
Według autora stan TASK_UNINTERRUPTABLE (D) ma nadal sens, ponieważ nie określa on tylko zapotrzebowania na system pod kątem wątków, tylko po prostu mierzy zapotrzebowanie na zasoby fizyczne — dlatego też wyliczanie średniego obciążenia zostało celowo zmienione (przed zmianą brano pod uwagę tylko uruchomione procesy), aby odzwierciedlić zapotrzebowanie na inne zasoby systemowe, a nie tylko procesory.
Wspomniałem, że procesy w tym stanie są faktycznie uśpione i nie robią nic. Z drugiej strony, takie wątki są w trakcie wykonywania pracy i to, że są zablokowane, często nie oznacza, że są bezczynne. Są pewnym popytem na system. Nie można się z tym nie zgodzić, zwłaszcza biorąc pod uwagę to, że obniżając wydajność systemu, powinno wzrosnąć zapotrzebowanie na jego zasoby (mierzone jako aktualnie wykonywana praca + praca oczekująca w kolejce). Często w takiej sytuacji średnie obciążenie zmniejsza się, ponieważ śledzi tylko stan pracy procesora, a nie stan zadań, które oczekują na podsystem I/O. Przykładem wywołania, które może zostać przeniesione w stan nieprzerwanego uśpienia, może być wywołanie związane z obsługą dysku, tj. może zająć ono dużo czasu (sekund), ponieważ wymagany będzie rozruch dysku twardego lub poruszenie głowicami. Przez większość czasu taki proces będzie „bezczynny”, blokując pamięć masową.
W celu pogłębienia swojej wiedzy na omawiany temat polecam przeczytać świetny artykuł pod tytułem Sleeping in the Kernel, z którego zresztą pozwoliłem sobie zaczerpnąć część informacji pisząc ten rozdział.
Średnie obciążenie systemu #
Rozmawiając o obciążeniu, jedną z najistotniejszych kwestii jest to, że zmienia się ono w czasie, najczęściej bardzo szybko. Ze względu na tę zmienność bardziej przydatne jest spojrzenie na średnie obciążenie, co daje lepszy przegląd wydajności oraz samego obciążenia, pod jakim znajdował się system. Średnie obciążenie ma jeszcze jedną ważną właściwość, mianowicie niweluje (wygładza) szybkie oscylacje, które mogłyby sprawić, że ludzka kontrola wartości obciążenia będzie prawie niemożliwa, a jeśli możliwa, to niemiarodajna.
Globalne średnie obciążenie próbuje zmierzyć liczbę aktywnych procesów i reprezentuje średni stopień obciążenia systemu przez dany okres czasu (uśredniana wartości chwilowego obciążenia i wszystkich poprzednich). Parametr ten jest miarą wykorzystania systemu w odpowiednim okresie czasu i odzwierciedla on ogólne obciążenie systemowe, które natomiast uwzględnia zapotrzebowanie na procesor i, w zależności od implementacji, zakończenie operacji I/O. Ponadto zależy także od ilości procesów oczekujących w kolejce uruchamiania (procesów gotowych do wykonania przez jądro) i jest tak naprawdę parametrem, który sumuje długość kolejki roboczej i liczby zadań aktualnie uruchomionych na procesorach oraz zadań oczekujących na koniec operacji I/O. Mówiąc ogólnie, parametr ten daje przybliżone wrażenie wielkości obciążenia systemu lub procesora w systemie. Nie oznacza natomiast, że wydajność spada (przynajmniej nie zawsze).
Można też powiedzieć, że średnie obciążenie to wartość, która daje pewne wyobrażenie o liczbie procesorów potrzebnych jądru do wykonania wszystkich zadań bez czekania. Jeżeli liczba tych zadań jest mniejsza niż liczba procesorów, które masz, oznacza to, że procesory są w pobliżu pewnej granicy, przy której są w stanie wykonać wszystkie zadania bez opóźnień. Jeżeli liczba tych zadań jest równa liczbie procesorów, oznacza to, że każdy z nich jest aktualnie zaangażowany w pracę. Wartości większe oznaczają, że istnieją procesy, które mogą być uruchomione, ale utknęły w kolejce i muszą czekać na czas procesora, który wykonuje obecnie inne zadania.
Tak naprawdę nie ma formalnej definicji średniego obciążenia i parametr ten może być różny od implementacji, jednak najczęściej obliczany jest poprzez zsumowanie liczby uruchomionych wątków (ich wykorzystanie) i liczby wątków w kolejce do uruchomienia (ich nasycenie). Niezależnie od rodzaju systemu oznacza, że coś się ładuje, lub mówiąc inaczej, jest zaplanowane do załadowania.
Średnia obciążenia reprezentuje liczbę procesów gotowych do przejęcia przez procesor (czyli takich, które nie zostały zablokowane dla operacji I/O) jednak może obejmować również procesy czekające na aktywność podsystemu I/O (np. dysku). Jest to tak naprawdę suma obu przypadków — więc przy wysokich wartościach średniego obciążenie problem może leżeć w jednym jak i w drugim.
Jeśli chodzi o średnie obciążenie systemu Linux, to jest ono chyba najbardziej niejednoznaczne, biorąc pod uwagę inne implementacje, ponieważ obejmuje różne typy zasobów. W związku z tym ciężko jest po prostu podzielić je przez liczbę procesorów, chociaż i tak jest to moim zdaniem w miarę logiczne rozwiązanie (o tym będzie jednak później). Generalnie wartości średniego obciążenia traktuję zawsze jako coś, co może oznaczać i wskazywać na pewne problemy w systemie, jednak bez głębszej diagnozy ciężko jest stwierdzić, co jest powodem tych problemów. Dlatego wartości te są bardziej przydatne do porównań z innymi parametrami, np. jeśli wiesz, że 8 procesorowy system działa dobrze przy obciążeniu 16, a w danym przedziale czasowym obciążenie wzrosło do 32, to czas zagłębić się w inne wskaźniki, aby zobaczyć, co się dzieje.
Jak już wspomniałem, w systemach z jądrem Linux oznacza to, że średniej obciążenia nie można interpretować jako oznaczającej tylko obciążenie procesora lub nasycenie, ponieważ z samej wartości nie wiadomo, w jakim stopniu odzwierciedla ona obciążenie procesora czy podsystemu I/O. Porównywanie wartości obciążenia jest również trudne, ponieważ może się ono zmieniać w zależności od obciążenia obu zasobów. Moim zdaniem, kod źródłowy jest zdecydowanie jednym z najważniejszych miejsc dokumentujących średnie obciążenie (niżej będzie informacja, który z plików źródłowych definiuje średnie obciążenie w systemach Linux). Jednak jedną z najlepszych i najprostszych definicji, z jaką się spotkałem, jest ta autorstwa Brendana Gregga, chyba guru do spraw optymalizacji i wydajności:
Linux load averages are "system load averages" that show the running thread (task) demand on the system as an average number of running plus waiting threads. This measures demand, which can be greater than what the system is currently processing.
Ten sam autor przedstawia je także w trochę bardziej szczegółowy sposób (wszystko dokładnie zostało opisane w świetnym artykule Linux Load Averages: Solving the Mystery), tym razem na przykładzie dwóch głównych implementacji:
On Linux, load averages are (or try to be) "system load averages", for the system as a whole, measuring the number of threads that are working and waiting to work (CPU, disk, uninterruptible locks). Put differently, it measures the number of threads that aren't completely idle. Advantage: includes demand for different resources.
On other OSes, load averages are "CPU load averages", measuring the number of CPU running + CPU runnable threads. Advantage: can be easier to understand and reason about (for CPUs only).
Zacytuję też fragment manuala dla podsystemu proc(5), który także powinien być pomocny w zrozumieniu średniego obciążenia i wartości umieszczonych w pliku /proc/loadavg:
The first three fields in this file are load average figures giving the number of jobs in the run queue (state R) or waiting for disk I/O (state D) averaged over 1, 5, and 15 minutes. They are the same as the load average numbers given by uptime(1) and other programs.
The fourth field consists of two numbers separated by a slash (/). The first of these is the number of currently executing kernel scheduling entities (processes, threads); this will be less than or equal to the number of CPUs. The value after the slash is the number of kernel scheduling entities that currently exist on the system.
The fifth field is the PID of the process that was most recently created on the system.
Dobrze, wiemy już, czym jest i o czym informuje średnie obciążenie, jednak z czego tak naprawdę składa się ten wskaźnik? Parametr średniego obciążenia przedstawiany jest zwykle w postaci trzech liczb określających obciążenie systemu z ostatnich 1, 5 i 15-minutowych okresów, jednak co chcę wyraźnie zaznaczyć, nie jest to czas średni, tylko wykładniczo ważona średnia czasowa ze stałą czasową z podanych okresów, co zostało opisane w źródłach jądra Linux:
The global load average is an exponentially decaying average of nr_running + nr_uninterruptible.
Te trzy liczby mają na celu dostarczenie pewnego rodzaju informacji o tym, ile pracy wykonano w systemie w niedalekiej przeszłości (1 minuta), odległej przeszłości (5 minut) i bardzo odległej przeszłości (15 minut) i zasadniczo oznaczają średnie wykorzystanie kolejki uruchomieniowej, czyli takiej specjalnej listy procesów, które oczekują na udostępnienie jakiegoś zasobu w systemie operacyjnym. W systemach BSD tym zasobem jest najczęściej procesor, jednak w przypadku systemów Linux, oprócz procesora może to być podsystem I/O, tj. dyski czy sieć. Widzimy więc, że istnieją trzy czynniki (rodzaje procesów) wpływające na średnie obciążenie:
- procesy, które mogą być (są) uruchomione na procesorze lub oczekują na uruchomienie (Linux/BSD)
- procesy, które wykonują dyskowe operacje I/O (Linux)
- procesy, które wykonują sieciowe operacje I/O (Linux)
Dobrze, a jak 1, 5 i 15-minutowe wartości najprościej interpretować? Jeśli średnia z 15-minutowego obciążenia jest wysoka, ale średnia z 1-minutowego jest niska, nastąpił znaczny wzrost aktywności, który od tego czasu spadł. Z drugiej strony, jeśli wartość 15-minutowa jest niska, ale średnia 1-minutowa jest wysoka, coś wydarzyło się w ciągu ostatnich 60 sekund i może nadal trwać (ale co ważne podkreślenia, wcale nie musi). Jeśli wszystkie średnie obciążenia są wysokie, oznacza to, że stan ten utrzymuje się przez co najmniej 15 minut. Myślę, że w każdym z tych trzech przypadków należy przyjrzeć się, co było lub ew. jest powodem zwiększonego zapotrzebowania na zasoby systemu.
Jakiś czas temu znalazłem bardzo ciekawe spostrzeżenie związane z kolejnością wartości średniego obciążenia. Temat dotyczył tego, że byłoby lepiej, gdyby były one zgłaszane w odwrotnej kolejności, tj. 15 minut, 5 minut i 1 minuty. W ten sposób łatwiej byłoby odczytać średnie obciążenie jako trend, zaś obecna konwencja ma najprawdopodobniej związek z porządkiem przepływu czasu (od lewej do prawej). Wydaje mi się, że jest to ciekawy pogląd warty uwagi.
Posłużę się też dwoma przykładami, które zostały zaczerpnięte z książki Systems Performance: Enterprise and the Cloud:
-
średnia godzinna wartość obciążenia wynosząca 10 oznaczałaby, że (dla systemu z jednym procesorem) w dowolnym momencie w tej godzinie można oczekiwać, że istnieje 1 uruchomiony proces i 9 innych procesów gotowych do uruchomienia (tj. niezablokowanych na operacjach I/O) dla procesora
-
jako nowoczesny przykład, system z 64 procesorami ma średnie obciążenie 128. Oznacza to, że średnio na każdym procesorze zawsze działa jeden wątek i jeden wątek czeka na każdy procesor. Ten sam system ze średnim obciążeniem wynoszącym 10 wskazywałby na znaczny zapas mocy, ponieważ mógłby uruchomić kolejne 54 wątki związane z procesorem, zanim wszystkie procesory stałyby się zajęte
Te trzy wartości ukazują, czytając od lewej do prawej, trend starzenia i/lub czas trwania określonego stanu systemu. Oznaczają one, że w danym przedziale czasowym średnio N procesów czekało na zasoby (interpretacja BSD i Linux), i nie chodzi tutaj o zasoby procesora tylko ogólnie zasoby systemu takie jak procesor, dyski czy sieć (interpretacja specyficzna dla Linuksa). Wartości te, niezależnie od implementacji, mówią tak naprawdę o jednej rzeczy, ile procesów w twoim systemie jest w stanie (R)unning/(R)unnable (co oznacza, że proces można uruchomić i albo jest on aktualnie uruchomiony, albo w kolejce wykonawczej oczekującej na uruchomienie). Biorąc to wszystko pod uwagę, możemy stwierdzić, że średnia obciążeń jest miernikiem średniej liczby procesów, jednocześnie wymagając uwagi procesora.
Wiemy już, że stwierdzenie, że obciążenie w systemie z jądrem Linux składa się głównie z zadań związanych z procesorem, jest nadmiernym uogólnieniem (przypomnij sobie wątpliwości i komentarz Matthiasa Urlichsa). Jeśli mamy dużo operacji I/O (dysk, sieć, użytkownik lub cokolwiek innego), całkowicie uzasadnione jest, aby średnia wartość obciążenia była znacznie wyższa niż liczba procesorów/rdzeni, a mimo to rzeczywiste wykorzystanie procesora było bliskie zeru. Pamiętajmy jednak, że w wielu przypadkach wszystko, co wpada do kolejki uruchamiania, musi przejść przez procesor, stąd często kładzie się mocny nacisk na średnią wartość obciążenia w stosunku do liczby procesorów, co również jest bardzo racjonalną interpretacją.
Technicznie, o czym zresztą wspomniałem wcześniej, przy każdej aktualizacji czasu (funkcja
update_times()) wywoływana jest dodatkowo funkcjacalc_load(), która zlicza liczbę procesów w stanie TASK_RUNNING lub TASK_UNINTERRUPTIBLE (czyli obliczenia te oparte są na procesach umieszczonych w odpowiednich kolejkach, a nie na rzeczywistym wykorzystaniu procesora) i używa tej liczby do aktualizacji średniego obciążenia systemu (patrz: loadavg.c jądra Linux oraz implementację funkcji getloadavg w systemie FreeBSD).
Podsumujmy zatem, co system operacyjny bierze pod uwagę podczas wyliczania średnich wartości:
- procesy, które aktywnie wykorzystują procesor, tj. (R) running
- procesy, określone jako działające, jednak czekające na dostępność procesora, tj. (R) runnable
- procesy, będące w stanie uśpienia, czyli czekające na dostęp do pewnego zasobu (zwykle są to operacje I/O), tj. (D) uninterruptible sleep
Widzimy, że większość systemów uniksowych podczas obliczania średniego obciążenia bierze pod uwagę procesy aktualnie uruchomione oraz te, które znajdują się w kolejce uruchamiania (czekające na procesor). W Linuksie jednak te procesy, które znajdują się w kolejce oczekiwania (czekają na aktywność dysku, sieci) są również uwzględnione w średniej obciążenia. Wspomniałem już, dlaczego tak się dzieje, jednak jest jeszcze jedna rzecz warta uwagi, mianowicie, zadania takie wliczane są do średniej z uwagi na to, że zadania nieprzerwane zwykle są planowane bardzo szybko, są więc liczone jako znajdujące się w kolejce do uruchomienia. Tak więc procesy, które wykonują dużo operacji I/O, będą wliczać się do średniej. Takie procesy pokazują stan (D) uninterruptible sleep w większości narzędzi do monitorowania stanu procesów i systemu. Ten stan jest zwykle używany przez sterowniki urządzeń czekające na dyskowe lub sieciowe operacje I/O. To wyjaśnienie dotyczy jądra Linux, dlatego należy mieć świadomość, że nie każdy system podobnie oblicza średnie obciążenie.
Podczas wykonywania operacji I/O proces jest blokowany jako nieprzerwany, tak aby dane nie zostały uszkodzone. Na przykład gdy proces oczekuje na zwrot wywołania funkcji
read()lubwrite()do/z deskryptora pliku zostanie przełączony w specjalny tryb uśpienia. Jest to wyjątkowe, ponieważ proces nie może zostać zabity ani przerwany w takim stanie (zwłaszcza gdy operacja nie mogła zostać zakończona lub jest zawieszona, wtedy może „utknąć” w tym stanie, o czym już wspominałem). Procesy w tym stanie nadal zajmują pewne zasoby procesora więc jeśli jest ich zbyt wiele, może on być zajęty m.in. ich ponownym szeregowaniem (co też jest jednym z powodów dlaczego widzimy duże obciążenie systemu). W celu dokładniejszego wyjaśnienia polecam przeczytać ten świetny komentarz.
Spójrz zatem na poniższą grafikę. Widać na niej, że w danym przedziale czasu, wykorzystanie procesora wyniosło 50% (tym samym procesor był bezczynny przez 50% czasu) a średnie obciążenie wyniosło 8.00 (dwa uruchomione procesy + sześć znajdujących się w kolejce zadań dla procesów w stanie nieprzerwanego uśpienia):
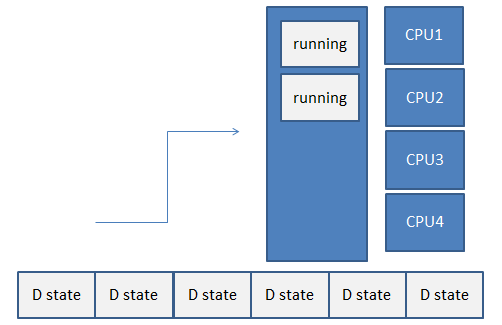
Z jednej strony, takie zachowanie jest bardzo rozsądne i zwykle lepsze niż całkowite ignorowanie takich procesów, z drugiej, nie wiemy, na które zasoby (procesor, dyski czy sieć) wzrasta zapotrzebowanie, czyli jak mocno każdy z procesów tych zasobów potrzebuje.
O wyświetlaniu i monitorowaniu średnich obciążeń będzie za chwilę, jednak już teraz o tym wspomnę. Polecenie vmstat jest jednym z tych poleceń, które pozwalają na podgląd kolejki uruchamiania. I tak kolumna r pokazuje działające lub gotowe do działania procesy, których systemy używają do wyliczenia średniego obciążenia. Kolumna b natomiast wskazuje procesy, które są zablokowane w oczekiwaniu np. na operacje dyskowe (będące w stanie D).
Wspomnieliśmy już kilkukrotnie o jednym z najczęstszych powodów zwiększonych wartości parametru load average — wysokiego parametru IOWait (oznaczony jako %wa w zrzucie polecenia
top), czyli czasu spędzonego przez procesor na oczekiwaniu na zakończenie operacji I/O. Parametr ten jest tak naprawdę miarą bezczynności, np. w oczekiwaniu na jakieś operacje. Jest on jedną z najbardziej kluczowych miar, która pozwala stwierdzić, czy system napotkał jakieś trudności związane z operacjami wejścia/wyjścia (np. związanymi z powolnymi lub zbytnio wykorzystanymi urządzeniami blokowymi).
Kończąc ten rozdział, oto krótkie podsumowanie:
- obciążenie nie jest wykorzystaniem procesora, ale całkowitą długością kolejki, w tym zadań oczekujących w kolejce do wykonania, lub inaczej mówiąc, średnim rozmiarem kolejki uruchomień
- obliczanie średniego obciążenia oparte jest na procesach umieszczonych w odpowiednich kolejkach, a nie na rzeczywistym wykorzystaniu procesora
- nie określa ono tylko zapotrzebowania na system pod kątem wątków (procesorów), tylko po prostu mierzy zapotrzebowanie na zasoby fizyczne takie jak procesor, oraz w zależności od implementacji, dyski czy sieć
- zapotrzebowanie na zasoby systemu może zostać zmierzone jako aktualnie wykonywana praca + praca oczekująca w kolejce
- średnia obciążenia to próbki punktowe z trzech różnych szeregów czasowych, które są wykładniczo ruchomymi średnimi
- średnia obciążenia dostarcza informację o tym, ile pracy wykonano w systemie w niedalekiej przeszłości (1 minuta), odległej przeszłości (5 minut) i bardzo odległej przeszłości (15 minut)
- średnia obciążenia nie jest procentem, ale średnią sumy następujących elementów:
- liczby procesów uruchomionych i oczekujących na przetworzenie TASK_RUNNING (Linux oraz BSD)
- liczby procesów oczekujących na zakończenie nieprzerwanego zadania TASK_UNINTERRUPTIBLE (Linux)
- jeśli istnieje wiele procesów w kolejce TASK_RUNNING, spowodują one zwiększenie średniego obciążenia, jednak procesy zatrzymane w TASK_UNINTERRUPTIBLE również to zrobią
- jeśli procesy żądające czasu procesora zostaną zablokowane (co oznacza, że procesor nie ma czasu na ich przetworzenie), średnia obciążenie wzrośnie
- takie wątki są w trakcie wykonywania pracy i to, że są zablokowane, często nie oznacza, że są bezczynne — są pewnym popytem na system
- jeśli każdy (zwłaszcza oczekujący) proces uzyska natychmiastowy dostęp do czasu procesora i nie zostaną utracone jego cykle, obciążenie zmniejszy się
Wyświetlanie średniego obciążenia #
Średnia obciążenia jest zwykle obliczana przez jądro (domyślnie co 5 sekund), a ściślej program planujący, przy użyciu liczby procesów w kolejce uruchomień w danym momencie. Jest to dokładnie zdefiniowane w pliku loadavg.h dla jądra Linux:
#define LOAD_FREQ (5*HZ+1) /* 5 sec intervals */
Oznacza to, że co 5 sekund + jedno tyknięcie (ang. a timer tick) zegara, które jest zależne od platformy, jądro oblicza średnią obciążenia. Czyli, jak już wiemy, sprawdza, ile procesów jest aktywnie uruchomionych, oraz ile procesów znajduje się w stanie nieprzerwanego oczekiwania i wykorzystuje to do obliczenia średniej obciążenia, wygładzając go wykładniczo w czasie. Czas zegara można podejrzeć poleceniem grep "CONFIG_HZ=" /boot/config-$(uname -r) dla jądra Linux, natomiast w przypadku systemów BSD za pomocą sysctl kern.clockrate. Dlaczego jest to 5 sekund + coś? Celowo nieznacznie odbiega od 5 sekund, zerknij do artykułu Understanding why the Linux loadavg rises every 7 hours oraz zapoznaj się z jeszcze innym podejściem opisanym w dokumencie LOAD_FREQ (4*HZ+61) avoids loadavg Moire.
Oczywiście, różne systemy operacyjne mogą obliczać wartości średniego obciążenia na różne sposoby. W systemach opartych na jądrze Linux zazwyczaj powoduje to wywołanie funkcji print_uptime(), która natomiast wywołuje funkcję loadavg() odpowiedzialną za odczyt wartości z pliku /proc/loadavg (koniecznie zajrzyj do źródeł procps). Jeśli chodzi o FreeBSD, to jest to po prostu wywołanie systemowe. Aplikacje takie jak top i uptime mogą korzystać z wywołania biblioteki getloadavg(3), aby uzyskać dostęp do wartości obciążeń. Polecenie uptime jest chyba najczęstszym sposobem wyświetlania wartości średniego obciążenia, a jego wynik przedstawiany jest w następującej postaci:
uptime
3:00PM up 20 days, 4 mins, 1 user, load averages: 0.29, 0.35, 0.39
Przypomnę tylko, że zadania chętne do uruchomienia są w stanie R lub D. Oznacza to, że faktycznie działają lub są zablokowane na niektórych zasobach (CPU, I/O) i czekają na możliwość uruchomienia. Chwilową liczbę takich zadań można określić za pomocą polecenia vmstat:
vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
29 0 8385220 1282012 253692 26318108 0 0 524 69 0 0 18 5 77 0 0
Oraz wykorzystując narzędzie ps w celu dokładniejszego określenie tych procesów:
ps -A -l | grep -e R -e D
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
1 D 0 661 2 0 9 - - 0 - ? 00:13:49 /usr/bin/python ...
1 R 0 9 2 0 80 0 - 0 - ? 01:02:04 rcu_sched
4 R 0 5339 5338 98 80 0 - 27000 - pts/1 00:00:20 dd
Do sprawdzania procesów będących w tych stanach lepsze wydaje się użycie polecenia ps z jednym z dwóch parametrów:
ps -l- aby zobaczyć tylko procesy danego użytkownikaps -el- aby zobaczyć wszystkie procesy w systemie
Jeśli proces jest w trybie uśpienia, pole WCHAN wskazuje na wywołanie systemowe, na które proces czeka. W niektórych przypadkach zastanów się nad wykorzystaniem poniższego jednolinijkowca (jednak tylko dla procesów w stanie D):
while : ; do date ; ps auxf | awk '{if($8=="D") print $0;}' ; sleep 0.5 ; done
Aby zobaczyć inne możliwości monitorowania takich procesów przejdź do rozdziału Monitorowanie obciążenia.
Średnie obciążenie w systemach BSD #
Muszę jeszcze raz wspomnieć o systemach BSD, ponieważ tutaj jest troszeczkę inaczej (tak naprawdę już powinieneś znać różnicę). W tym typie systemów, średnie obciążenie to średnia liczba wątków oczekujących na czas procesora i jest pewną miarą wielkości kolejki uruchamiania — czyli liczby zadań „możliwych do uruchomienia” (tj. procesów, które chcą mieć czas procesora) — i tak naprawdę oznacza, że istnieje wiele procesów, które czasem się uruchamiają oraz określa liczbę zadań w kolejce uśrednionych w ciągu 1, 5 i 15 minut.
Obecnie interwał próbkowania we FreeBSD wynosi 5 sekund, z losową „fluktuacją”, aby uniknąć synchronizacji z procesami działającymi w regularnych odstępach czasu (czyli przedział czasowy jest podobny jak w systemach z jądrem Linux).
Ponadto, idąc za wyjaśnieniem opisanym w artykule BSD load demystified, w systemach BSD średnie obciążenie jest liczbą procesów, które zostały (chciały zostać) uruchomione co najmniej raz w najnowszym 5-sekundowym oknie. Tak więc według tej interpretacji, jeśli masz proces, który budzi się co 5 sekund i coś wykonuje, masz średnie obciążenie 1.
W systemach BSD, aby podejrzeć, co się dzieje w systemie i jaki wpływ na ogólną wydajność może mieć średnie obciążenie, można skorzystać z jednego z dwóch poleceń:
# 1)
top -C -s 5
# 2)
vmstat -w 5
Jeżeli chodzi o różnice między implementacjami w jądrze Linux i BSD, to w tej drugiej, do wartości średniego obciążenia nie są wliczane zadania będące w stanie nieprzerwanego uśpienia, czyli procesy oczekujące na I/O (często procesy zablokowane na dysku). Na przykład, jeśli proces próbuje odczytać coś z pliku znajdującego się na innym komputerze w sieci, a drugi komputer jest niedostępny, proces ten jest uważany za „nieprzerwany”. Proces taki powinien zostać automatycznie zabity, gdy tylko upłynie limit czasu. W przeciwieństwie do systemów BSD, systemy z jądrem Linux intensywnie korzystające z dysku wykazują znacznie wyższe średnie obciążenie, nawet w przypadku gdy procesor jest bezczynny.
Spójrz na poniższy diagram, który prezentuje stany w jakich znajdują się procesy i porównuje ze sobą obie implementacje:
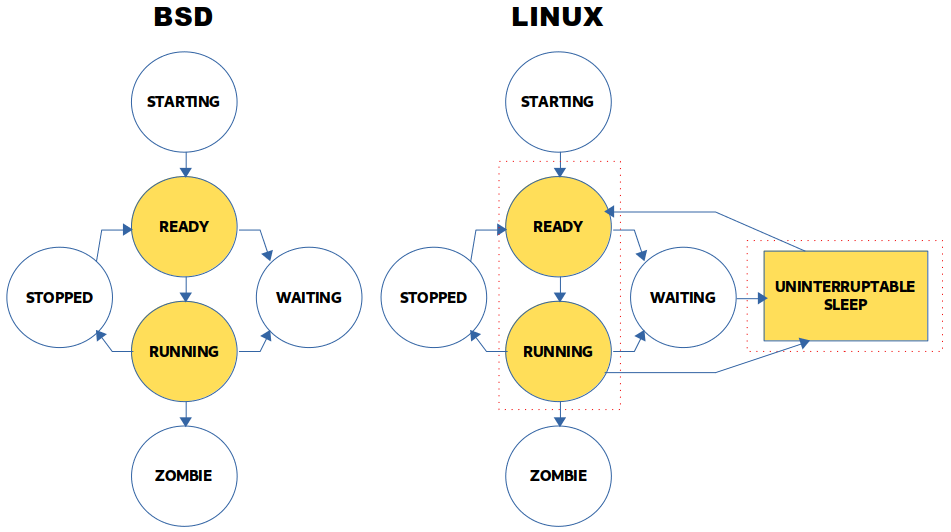
Nie jestem w stanie jednoznacznie odpowiedzieć na pytanie, które rozwiązanie jest lepsze (bardziej miarodajne). Możliwe, że wliczanie procesów oczekujących do średniego obciążenia ma spowodować, że metryka dla Linuksa jest „dokładniejsza”. Z drugiej strony nie zawsze wiadomo (jak już wspomniałem), czy określa ona lokalne podsystemu I/O, zdalne, czy może oba.
Jeżeli chcesz uzyskać jeszcze więcej informacji, polecam analizę pliku źródłowego kern_synch.c (zerknij szczególnie na wywołanie nrun = sched_load();, które de facto oblicza średnią obciążenia).
Średnie obciążenie a procent wykorzystania procesora #
Powiedzieliśmy sobie już trochę na temat średniego obciążenia w systemie, jednak bardzo często zdarza się, że dochodzi do połączenia tych wartości z rzeczywistą utylizacją procesora.
Procent obciążenia procesora to ilość przedziału czasu (interwału próbkowania), w którym stwierdzono, że procesy systemowe były aktywne na procesorze. Jeśli procesor był wykorzystany w 85%, oznacza to, że 85% pobranych próbek wykazało, że proces jest aktywny na procesorze, zaś reszta aplikacji czekała.
Tak naprawdę nie ma czegoś takiego jak wykorzystanie procesora, np. w 50%. Procesor może być tylko wykorzystany w 100%, wykonując jakieś instrukcje lub w 0%, czekając na coś do zrobienia. Wynika to z tego, że procesor jest urządzeniem logicznym opierającym swoją pracę na wartościach logicznych, tj. 0 oraz 1. Stąd albo coś robi na maksa swoich możliwości albo nie robi nic. Nie ma tutaj półśrodków. Mówiąc jednak o wykorzystaniu procesora musimy pamiętać, że miara ta jest wyliczana na podstawie danego okresu czasu, stąd przedstawia się ją w postaci procentowej.
Średnie obciążenie różni się od rzeczywistego wykorzystania procesora na dwa sposoby:
- średnie obciążenie mierzy trend wykorzystania systemu (w tym procesora) nie tylko w danej chwili
- średnie obciążenie obejmuje całe zapotrzebowanie na system (w tym procesor), a nie tylko to, ile było faktycznego zapotrzebowania w czasie pomiaru, jak ma to miejsce w przypadku procentowego określenia
Często te dwa zagadnienia są ze sobą połączone, jednak nie należy traktować ich tak samo. Średnia wartość obciążenia jest miarą liczby zadań oczekujących w kolejce uruchamiania (nie tylko zajmujących czas procesora, ale także aktywność innych zasobów) w danym okresie czasu. Natomiast wykorzystanie procesora jest miarą tego, jak bardzo obciążony jest procesor.
Stąd duże średnie obciążenie przy prawie 5% wykorzystaniu procesora (na przykład, gdy wiele danych I/O oczekuje na wykonanie) jest czymś normalnym. Nie raz systemy, którymi administrowałem, przedstawiały bardzo wysokie obciążenie przy niezwykle niskim wykorzystaniu CPU. Zdarzało się też średnie obciążenie powyżej 100, kiedy procesor wykorzystany był w ledwie 20%. Tak samo średnie obciążenie z ostatnich 5 minut równe 1 i 100% wykorzystania procesora jest czymś normalny, gdy uruchomiony jest bardzo wymagający proces jednowątkowy.
Przykład przez analogię (chyba najczęściej stosowaną dlatego podtrzymam tę tradycję). Serwer z czterema procesorami może być traktowany jako czteropasmowa autostrada. Każdy pas zawiera ścieżkę, na której można wykonać instrukcje (pojazdy na autostradzie). Na pasach wjazdowych znajdują się pojazdy gotowe do przejechania autostradą, a cztery pasy albo są gotowe do przejechania, albo nie. Jeśli wszystkie pasy autostrady są zablokowane, wjeżdżające samochody muszą czekać na otwarcie. Wartość procentowa bada względny czas, w którym każdy pojazd znalazł się na pasie autostrady, zaś średnie obciążenie określa zapotrzebowanie na autostradę, czyli ilość samochodów w kolejce oraz ilość samochodów aktywnie wykorzystujących pasy autostrady. Jest jeszcze jeden ciekawy parametr — szybkość z jaką pojazdy mogą poruszać się po autostradzie, która może odpowiadać częstotliwości procesora.
Często powtarzające się wysokie obciążenia bez odpowiadającej równie wysokiej aktywności procesora mogą być oznaką problemów z pamięcią. Przykładem mogą być tutaj systemy wirtualizacji, na których maszyny wirtualne mocno konkurują o zasoby serwera takie jak pamięć masowa.
Różnica między tymi dwoma parametrami jest dosyć znacząca, zwłaszcza jeśli chodzi o ogólny obraz wydajności i obciążenia. Procent wykorzystania procesora pokazuje nam, ile samochodów korzysta z autostrady, ale to średnie obciążenie pokazuje nam najważniejszą rzecz, czyli cały obraz zapotrzebowania na autostradę, tj. aktualne wykorzystanie autostrady oraz pojazdy, które oczekują na możliwość wjazdu na nią. Co ciekawe, im nowszy (w czasie) jest stan kolejki, tym bardziej odzwierciedla go średnia wartość obciążenia.
Kolejka jest podstawową strukturą danych w harmonogramie i zawiera listę uruchomionych procesów dla jednostki centralnej lub dla jednego procesora w systemie wieloprocesorowym. Program planujący jest częścią jądra, która alokuje czas pracy procesora pomiędzy różne uruchamialne procesy w systemie.
Ostatecznie średnie obciążenia dają płynny trend od 15 minut do bieżącej minuty i pokazują nie tylko wykorzystanie procesora, ale również średnie zapotrzebowanie na procesor (lub procesory). Gdy średnia obciążenia przekracza liczbę dostępnych rdzeni, im więcej każdy z nich jest używany, tym większe jest zapotrzebowanie na nie. I, w miarę cofania się, im mniej procesor jest używany, tym zapotrzebowanie maleje. Dzięki takiemu zrozumieniu można użyć średniej obciążenia z procentem procesora, aby uzyskać dokładniejszy obraz jego aktywności.
Spójrz na poniższy schemat (traktuj go jednak jako mocne uogólnienie!), który może okazać się także pomocny w rozumieniu obu parametrów (dla ułatwienia rozbiłem wszystko na osobne procesory oraz pojedyncze procesy):
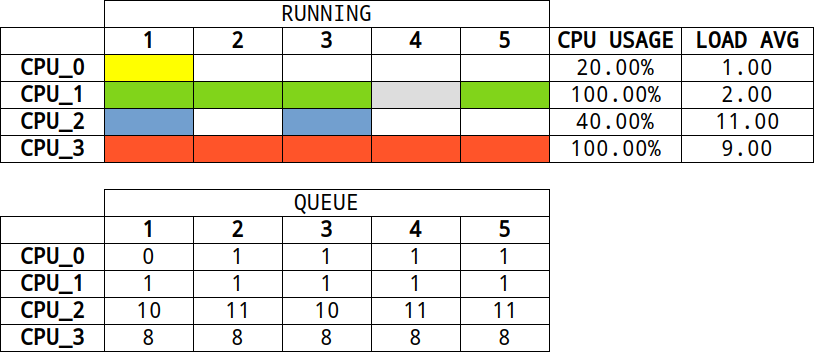
W przypadku pierwszego procesora widzimy, że aktualnie (w danej jednostce czasu) przetwarzany jest jeden proces (kolor żółty). W kolejnej jednostce czasu ten proces przechodzi w inny stan, ponieważ oczekuje na jakieś operacje (np. I/O). Oczywiście w tym samym czasie procesor może zająć się nowym procesem, który jest np. w kolejce. W kolejce nie ma jednak żadnego procesu (z wyjątkiem przed chwilą przesuniętego procesu), stąd procesor przechodzi w stan bezczynności. W tym scenariuszu widać, że dany proces wykorzystał procesor tylko w 20% (czyli tak jak pojazd na autostradzie, proces był na niej tylko przez 20% czasu) zaś średnie obciążenie wyniosło 1.00 (proces przetwarzany przez procesor oraz przesunięty jako zadanie oczekujące już do końca mierzonego czasu).
W drugim przypadku procesor obsługuje dany proces (kolor zielony) przez 80% swojego czasu. W tym czasie, w pewnym momencie proces zmienia swój stan, jednak procesor nie przechodzi w stan bezczynności, ponieważ zajmuje się obsługą procesu (kolor siwy), który był w kolejce. Przez cały czas trwania przetwarzania kolejka jest zapełniona przez jeden proces. Proces, który wchodzi w miejsce „starego”, zajmuje 20% czasu procesora (czyli łącznie procesor był wykorzystany w 100%). Średnie obciążenie dla tego procesora wynosi 2.00, ponieważ przez cały czas obecne były dwa procesy (jeden proces na procesorze oraz jeden procesów w kolejce do uruchomienia).
W trzecim przypadku widzimy, że dany proces zajął tylko 40% czasu procesora, zaś przez pozostały czas procesor był bezczynny. W kolejce zadań było jednak 10 procesów oczekujących na operacje I/O. Stąd obciążenie systemu wyniosło 11.00. Natomiast w ostatnim przypadku widać wyraźnie, że przez cały okres czasu procesor się nie nudził i proces, który aktualnie był wykonywany, zajął go w 100%. W kolejce było jednak osiem procesów oczekujących na swój czas, stąd średnie obciążenie wyniosło 9.00. Gdyby w tym przykładzie kolejka była pusta, system pracowałby optymalnie, ponieważ do zliczania średniego obciążenia pod uwagę brany byłby tylko jeden proces (i to aktualnie przetwarzany przez jednostkę centralną).
Moim zdaniem, w przypadku systemów działających poniżej swoich limitów wartości procentowego użycia procesora, rzeczywiste wykorzystanie jest znacznie bardziej przydatne niż średnie wartości obciążenia, ponieważ ich interpretacja numeryczna jest uniwersalna. Jednak po przekroczeniu tych limitów średnie wartości obciążenia pozwalają nam zobaczyć, o ile poza limitami działał system, oczywiście względem średniej obciążenia dla tego systemu.
Dlaczego obciążenie maleje lub rośnie? #
Niektóre z aplikacji mogą wygenerować naprawdę spore obciążenie. Krótkoterminowe wzrosty zwykle nie stanowią problemu, ponieważ każdy wysoki pik, jeśli się pojawi, jest prawdopodobnie wybuchem aktywności, a nie stałym poziomem. Na przykład wraz z uruchamianiem systemu rozpoczyna się wiele procesów, a następnie aktywność się uspokaja. Jeśli wzrost jest widoczny i utrzymuje się w 5 i 15 minutach średnich obciążeń, wtedy może to być powodem do niepokoju.
W rzeczywistości obciążenie jak i liczba zadań gotowych do uruchomienia w danym systemie zależy od:
- architektury działającego oprogramowania
- przepustowości oraz wydajności procesora
- przepustowości oraz wydajności podsystemu I/O
- liczba dostępnych rdzeni
Przy okazji raz jeszcze polecam zapoznać się z bardzo ciekawym artykułem: Understanding why the Linux loadavg rises every 7 hours.
Jaka wartość jest optymalna? #
Nie ma jednoznacznej odpowiedzi na to pytanie, zresztą jak zawsze w przypadku pytań związanych z optymalizacją. Wartość optymalna, to tak naprawdę wartość odkryta empirycznie lub taka, przy której wiemy, że dany system działa stabilnie — czyli kiedy obciążenie nie wzrasta znacznie, co oznacza, że sprzęt i charakter zadań do przetworzenia zapewniają dobrą ogólną przepustowość, unikając gromadzenie się procesów w kolejce przez pewien (dłuższy, a nawet bardzo długi) czas. Oczywiście różne systemy/implementacje będą zachowywać się inaczej przy tej samej wartości średniego obciążenia.
Podstawowa zasada: jeśli średnie obciążenia przekraczają ilość dostępnych rdzeni, a system jest responsywny, reaguje, nie widzisz opóźnień (lub są one do zaakceptowania) i zadania, które ma do wykonania kończone są w odpowiednim czasie, możesz uznać, że wszystko jest w porządku (lub zacząć powoli analizować ew. wąskie gardła nie popadając w nadmierną panikę). Skoncentruj się bardziej na monitorowaniu dodatkowych parametrów, na których Ci zależy, takich jak głębokość kolejki dostarczania w przypadku serwerów poczty, żądań na sekundę w przypadku serwerów HTTP czy ilości procesów NFS na serwerze kopii zapasowych.
W przypadku określania optymalnych wartości średnich obciążeń można je podzielić przez liczbę procesorów, a następnie powiedzieć, że jeśli współczynnik ten przekracza 1.00, pracujesz na nasyceniu (czyli kolejka uruchamiania jest zapełniona), co może powodować problemy z wydajnością. Jeden system ze współczynnikiem 1.50 może działać dobrze, podczas gdy inny może działać źle. Na przykład, jedna z wartości średniego obciążenia może być równa 8 dla systemu, na którym działa mało wymagająca web aplikacja a równie dobrze może wynosić 64 dla serwera, który wykonuje jakieś skomplikowane symulacje (oczywiście w obu przypadkach przy zapewnieniu odpowiedniej liczby rdzeni). Tak naprawdę każde stwierdzenie typu „średnie obciążenie jest za wysokie” jest prawdziwe jedynie, kiedy znamy optymalną wartość obciążenia naszego systemu jako punkt odniesienia do wartości wysokiej.
W przypadku serwera HTTP, który zajmuje się głównie odbieraniem i przetwarzaniem żądań, przekazywaniem żądań do innych usług czy zapisywaniem zdarzeń do dzienników większe znaczenie niż średnie obciążenie ma czas odpowiedzi na żądanie klienta. Oczywiście, często jest ono związane z obciążeniem, ponieważ czas odpowiedzi będzie się wydłużał przy mocno obciążonym serwerze, tj. gdy wiele połączeń czeka na przetworzenie. Jeśli tego rodzaju żądania docierają zbyt szybko, średnia wartość obciążenia serwera może gwałtownie wzrosnąć, powodując brak reakcji serwera. W przypadku serwera poczty, ilość czasu potrzebna procesorowi na wysłanie wiadomości jest bardzo niska. Jednak gdy tysiące przesyłek przemieszczają się po systemie, kolejka uruchamiania może stać się bardzo, ale to bardzo długa. W przypadku bardzo wrażliwych czasowo rzeczy, takich jak serwery VoIP lub systemy buforowania pamięci podręcznej, powinno zależeć nam, aby średnie obciążenie było znacznie mniejsze niż liczba rdzeni. Natomiast w przypadku zadań asynchronicznych, które mogą poczekać lub zostać przechowane przez pewien czas w pamięci, średnie obciążenie powyżej (nawet znacznie) ilości dostępnych rdzeni jest czymś całkowicie normalnym.
Przytoczę tutaj wypowiedź Blaira Zajaca, autora narzędzia ORCA, który bardzo przystępnie opisuje kwestie związane m.in. z obciążeniem:
If long term trends indicate increasing figures, more or faster CPUs will eventually be necessary unless load can be displaced. For ideal utilization of your CPU, the maximum value here should be equal to the number of CPUs in the box.
Należy też pamiętać, że w nowoczesnych wielozadaniowych systemach operacyjnych istnieje więcej niż jedna rzecz, która wymaga uwagi procesora, więc przy umiarkowanym obciążeniu optymalna średnia wartość może wynosić od 0.8 do 2 (może to być wartość optymalna, ale wcale nie musi). Z drugiej strony może to być w pewnym sensie spore nadużycie, ponieważ rzadko się zdarza, aby jeden proces zablokował wszystkie zasoby procesora. Dlatego jak widzisz, wiele zależy od ilości dostępnych rdzeni, specyfiki systemu oraz rodzaju zadań, jakie są wykonywane na serwerze.
Choć bardzo ciężko jest określić odpowiednie wartości oraz progi, to moim zdaniem, średnia optymalnego (bezpiecznego) obciążenia powinna zależeć od liczby rdzeni dostępnych na serwerze i powinna być równa ich liczbie. Jeśli średnia jest większa niż ilość rdzeni, zasoby serwera są najprawdopodobniej nadmiernie wykorzystywane, a jeśli mniejsza, serwer nie działa z pełnym potencjałem.
Gdybyśmy mieli więcej niż jeden procesor, powiedzmy ośmioprocesorowy, podzielilibyśmy średnie wartości obciążenia przez liczbę procesorów. W tym wypadku obserwowanie 1-minutowej średniej obciążenia wynoszącej 8.00 oznacza, że system jako całość był w 100% (8.00/8) wykorzystany w ciągu ostatniej minuty.
Pozwolę sobie zacytować i przetłumaczyć fragment bardzo dobrego i ciekawego spojrzenia na wartości średniego obciążenia, które zaprezentował Andre Lewis w artykule Understanding Linux CPU Load - when should you be worried?:
-
0.70 oznacza „Trzeba się temu przyjrzeć”: jeśli średnie obciążenie utrzymuje się w pobliżu lub powyżej 0.70, czas to zbadać, zanim sytuacja się pogorszy
-
1.00 oznacza „Napraw to teraz”: jeśli średnie obciążenie utrzymuje się powyżej 1.00, znajdź problem i napraw go teraz. W przeciwnym razie obudzisz się w środku nocy i nie będzie to zabawne
-
5.00 oznacza „Arrgh, jest 3 nad ranem WTF?”: jeśli średnie obciążenie przekracza 5.00, możesz mieć poważne kłopoty, twój system albo wisi lub zwalnia, a to (w niewytłumaczalny sposób) stanie się w najgorszym możliwym czasie, np. w środku nocy lub podczas prezentacji na konferencji
Wysoka wartość obciążenia oznacza, że kolejka uruchamiania jest długa. Niska wartość oznacza, że jest krótka. Dlatego jeżeli obciążenie naszego systemu jest równe 16, to oznacza, że w rzeczywistości 16 procesów czeka na swój następny wycinek czasu. Jeśli mamy 16 procesorów, możemy nadać tym przedziałom czasowym jeden procesor (jeden procesor na proces), dzięki czemu nasz system będzie optymalnie wykorzystywany. Jednak jeśli zdecydujesz się zrobić coś szalonego, na przykład zbudować program wykorzystując make -j 96 (nigdy tego nie robiłem), pomimo posiadania tylko jednego logicznego procesora, średnie obciążenie podskoczyłoby najprawdopodobniej do 96, co poskutkowałoby, że system stałby się nieresponsywny — głównie przez ilość zmian kontekstu procesora naprzemiennie między procesami systemu operacyjnego.
Średnia długość kolejki uruchomieniowej L i średni czas, jaki proces spędza w kolejce uruchomieniowej T, są powiązane z prawem Little’a, które można wyrazić wzorem
L = λT, gdzie λ jest średnim tempem przybywania zadań (intensywność napływu zgłoszeń). Więcej na ten temat poczytasz w artykule Little’s Law (explained with tacos).
Poziom, który jest akceptowalny, zależy od sprzętu, liczby rdzeni, rodzaju używanego harmonogramu zadań jądra i zadań, których się spodziewamy. Przedstawię to na przykładzie, który znalazłem kiedyś w poszukiwaniu artykułów na temat obciążenia systemów. Wyobraźmy sobie, że mamy 4 kasjerów w sklepie. Każdy kasjer to jeden procesor z jedną linią klientów (obciążenie) oczekujących na rozliczenie swoich produktów. Kasjerzy mają tę cudowną umiejętność przełączania się między klientami a zadania, które mają do wykonania (obsługa klientów), mogą robić tylko w pewnej określonej (maksymalnej) szybkości.
Jak wiemy, w godzinach szczytu kolejka jest zazwyczaj bardzo długa a czas oczekiwania dla każdej osoby wysoki. Tak samo, jeśli nie ma żadnych klientów, czas oczekiwania jest bardzo, bardzo niski, kasjerzy się nudzą i nie są w żaden sposób przeciążeni. Wydajność każdego kasjera (procesora) oraz ich ilość są kluczowe jeśli obsługa klientów ma przebiegać sprawnie (bez opóźnień). Dlatego im więcej klientów w kolejce, tym wyższe zapotrzebowanie na kasjera.
Długość kolejki w sklepie w świecie Uniksa nazywa się długością kolejki uruchomieniowej, czyli sumą liczby aktualnie uruchomionych procesów oraz liczby oczekujących (w kolejce) na uruchomienie. Istotne jest to, że każdy procesor ma własną kolejkę uruchomionych procesów.
Stosując tę analogię do średniej obciążenia, możemy powiedzieć, że:
-
1.0 - oznacza minimalny czas oczekiwania przy kasie, każdy kasjer obciążony jest na 25% swoich możliwości i pracuje bardzo wydajnie, klienci są zadowoleni, ponieważ przechodzą dalej a ich produkty są rozliczane bez opóźnień
-
3.5 - oznacza, że kolejka się zapełnia, a każdy kasjer ma dużo pracy i pracuje prawie na 100% swoich możliwości. Taka sytuacja jest jednak w pełni akceptowalna, ponieważ kasjerzy nadal pracują wydajnie. Jeśli średnia wzrośnie i przekroczy bezpieczny próg, wszystko zacznie zwalniać i zwiększy się oczekiwanie. Kasjerzy nadal będą obsługiwać klientów z maksymalną prędkością, jednak będzie ich więcej, stąd każdy kasjer będzie musiał przełączać się częściej między nimi i w konsekwencji przepływ obsługi klientów zwolni
-
12.0 - oznacza, że kolejka się bardzo wydłużyła, kasjerzy są bardzo mocno obciążeni, ponieważ mają dużo więcej pracy, niż mogą wykonać, klienci są rozliczani z tą samą prędkością, jednak jest ich znacznie więcej, dlatego też kasjerzy z powodu zwiększonej ilości przełączania między klientami nie nadążają z ich obsługą. Do szybszego wyczyszczenia kolejki wymagani są dodatkowi kasjerzy (procesory)
Jeśli spojrzysz na powyższy przykład, możesz stwierdzić, że idealną wartością obciążenia jest 1.0 dla jednego procesora (kasjera). Przypomnij sobie, jak na początku tego rozdziału stwierdziłem, że optymalna wartość powinna wahać się od 0.8 do 2. Moim zdaniem nie do końca tak jest, ponieważ aby system działał bez żadnych problemów, wartość średniego obciążenia nie powinna przekraczać 0.7/0.8 (oznacza to, że dobrze jest utrzymywać zapas mocy na niespodziewany wzrost zapotrzebowania na procesor). Gdy wartość tego parametru jest większa, powinniśmy zacząć analizę i szukać przyczyny potencjalnego przeciążenia systemu. Wartość równa 1.0, jest tak naprawdę wartością graniczną, przy której system pracuje w miarę wydajnie, jednak jest na cienkiej granicy możliwego spowolnienia a w konsekwencji nawet zawieszenia. Przy czym pamiętajmy, że tymczasowe skoki powyżej 1.0 nie są żadną tragedią i zdarzają się od czasu do czasu, a problem pojawia się zazwyczaj jeśli konsekwentnie jesteśmy powyżej wartości granicznej.
Na koniec, także jako podsumowanie tego rozdziału oraz pewną sugestię do dalszej analizy, przytoczę bardzo ciekawe (wręcz niezwykle istotne) wnioski Neila Gunthera poruszone w artykule How Long Should My Queue Be?. Przedstawia on kilka kwestii dotyczących wartości średniego obciążenia:
- średnie obciążenie nie mierzy wykorzystania procesora, chociaż słowo load może to sugerować
- średnie obciążenie nie jest średnią arytmetyczną, tylko średnią ruchomą (ważoną)
- średnie obciążenie mierzy uśrednioną w czasie długość kolejki uruchomieniowej
- długość kolejki oznacza liczbę uruchomionych procesów oraz liczbę procesów oczekujących na pewne zasoby (oczywiście w zależności od implementacji)
- jest to raczej sama w sobie nieistotna miara, ponieważ ciężko stwierdzić, czy średnie obciążenie równe 30 jest dobre czy złe
- była to jedna z najwcześniejszych miar wydajności pierwotnie wprowadzona dla projektu Multics pod koniec lat 60. XX wieku
- zalecane jest poleganie na własny testach dla wszystkich wskaźników wydajności, na których się opierasz, w tym średniej obciążenia
Ponadto autor porusza temat długości kolejki uruchamiania, tj. ile powinna wynosić oraz jaka wartość (długość) jest optymalna. Pozwolę sobie zacytować jeden z fragmentów:
Long queues correspond to long response times and it's really this latter metric that should get your attention. So, one consequence might be that a long queue causes "poor response times", but that depends on what poor means. There is usually an empirical disconnect between measured queue lengths and user-perceived response times. Another problem is that queue length is an absolute measure, whereas what is really needed is a relative performance measure. Even the words, poor and good are relative terms. Such a relative measure is called the Stretch Factor, which measures the mean queue length relative to the mean number of requests already in service. It is expressed in terms of service units.
Polecam zapoznać się z jeszcze innym dokumentem Neila Gunthera, tj. Understanding Load Averages and Stretch Factors [PDF].
Dlaczego parametr load average nie jest miarodajny? #
No właśnie. Pamiętajmy, że np. jądro Linux w swoich wyliczeniach obciążenia uwzględnia procesy z przerywanym oczekiwaniem. W przeciwieństwie do procesów do uruchomienia, które znajdują się w kolejce, te nie biorą udziału w obciążeniu procesora i można powiedzieć, że procesor je przetwarza bezczynnie (co też moim zdaniem do końca nie jest prawdą), więc wartości obciążenia obserwowane w systemie Linux mogą być mylące i nie koniecznie wskazywać, że procesor jest bardzo zajęty. Co ważne, średnia obciążenia bardzo często nie odzwierciedla faktycznego wzrostu wykorzystania procesora jednak nadal daje wyobrażenie o tym, jak długo trzeba czekać na wykonanie zadań.
Aby jeszcze skomplikować sprawę, musisz mieć świadomość, że to, co napisałem w poprzednim rozdziale, to trochę nadmierna generalizacja i ma zastosowanie tak naprawdę tylko wtedy, gdy obciążenie składa się głównie z zadań związanych z procesorem. Jeśli w twoim systemie jest dużo operacji I/O (dysk, sieć, użytkownik lub cokolwiek innego), całkiem rozsądne jest, aby średnie obciążenie było wyższe niż liczba procesorów/rdzeni, a rzeczywiste wykorzystanie procesora było bliskie zeru. Sam miałem okazję administrować systemem, który był jednym z najważniejszych do zapewnienia ciągłości działania firmy, którego obciążenie z ostatnich 15 minut utrzymywało się na poziomie 12, przy 4 rdzeniach — system działał stabilnie, nie wykrywaliśmy opóźnień ani innych problemów z wydajnością.
Średni wskaźnik obciążenia może być początkowo trudny do zrozumienia. Myślę, że wiele osób uważa, że wskazuje on na to, jak ciężko działa procesor. Nie jest to prawdą. W interpretacji miara średniej obciążenia nie wskazuje, jak ciężko pracuje procesor, ale ile pracy należy wykonać, a mówiąc jeszcze dokładniej, ile pracy wykonano.
Przy dyskusjach o tym jak ważny jest parametr load average, zawsze odsyłam do kodu kernela, który go definiuje:
/*
* kernel/sched/loadavg.c
*
* This file contains the magic bits required to compute the global loadavg
* figure. Its a silly number but people think its important. We go through
* great pains to make it work on big machines and tickless kernels.
*/
Powtórzmy raz jeszcze: mówiąc ogólnie, średnie obciążenie to ilość procesów oczekujących na czas procesora lub zużywających czas procesora. Tak jak wspomniałem w jednym z powyższych paragrafów, są to procesy aktualnie wykorzystujące czas procesora, procesy oczekujące na czas procesora i procesy, które nie generują obciążenia procesora jednak mogące mieć wpływ na zwiększenie (niekiedy znaczne!) średniego obciążenie systemu.
Tak naprawdę największym paradoksem tego parametru jest to, że procesy oczekujące na odczyt z dysku, który na przykład jest niedostępny lub bardzo zajęty, mogą wygenerować bardzo duże obciążenie pomimo tego, że procesor może być całkowicie bezczynny. I tak jeśli mamy serwer z 16 rdzeniowym procesorem, posiadanie 16 procesów oczekujących na czas procesora nie musi być wcale złe, ponieważ średnia wartość obciążenia może wynosić 16, ale tak naprawdę bez obciążenia (przeciążenia) serwera. To samo, jeśli mamy wiele wywołań, które tworzą i niszczą dużą liczbę procesów, co może doprowadzić do wysokiego średniego obciążenia, jednak bez znaczącego wpływu na całkowitą wydajność serwera. Wniosek z tego taki, że wysoka średnia obciążenia niekoniecznie oznacza przeciążony serwer.
Na początku tego artykułu wspomniałem, że średnie obciążenie jest jedną z pierwszych rzeczy do sprawdzenia, w przypadku problemów z wydajnością. Sam posiłkuję się tymi wartościami, jednak nie są one dla mnie kluczowe i wskazują jedynie pewien problem, który muszę zdiagnozować za pomocą dodatkowych narzędzi, takich jak top, sar, mpstat, vmstat czy iostat.
Wynika z tego fakt, że parametr load average musi zostać powiązany z innymi parametrami takimi jak wykorzystanie samego procesora czy zwiększone wykorzystanie podsystemu I/O. Wysokie wartości średniego obciążenia przy równie wysokim wykorzystaniu procesora mogą wskazywać na ogólne przeciążenie serwera. Z drugiej strony, zwiększone średnie obciążenie wraz z niskim wykorzystaniem procesora jest najprawdopodobniej spowodowane problemami dyskowymi czy sieciowymi (np. przez wysoki czas odpowiedzi lub słabej jakości urządzenia). Problemy dyskowe czasami spowodowane są niepoprawnie napisanymi aplikacjami, które intensywnie (w sposób nieprzemyślany) korzystają z operacji wejścia/wyjścia, powodując ogromny nacisk na dysk. Inne powiązane z tym magazynem danych aplikacje będą również miały problemy z wydajnością z powodu rywalizacji o zasoby. Podobne problemy mogą być także spowodowane nadmiernym zapisem danych do pliku wymiany z powodu nadmiernego wykorzystania pamięci operacyjnej. Zrzut stron na dysk także potrafi doprowadzić do zwiększonej ilości IOPs systemu pamięci masowej.
Spójrzmy na przykład, który także będzie odpowiedzią na pytanie, w jaki sposób samodzielnie wygenerować procesy, które przejdą w stan nieprzerwanego uśpienia. W pierwszej kolejności musimy przygotować sobie jakąś partycję, zrobimy to w ten sposób:
pvcreate /dev/sdb2
vgcreate vg-unint /dev/sdb2
lvcreate -n lv-unint -L 64M vg-unint
mkfs.ext3 -m0 /dev/vg-unint/lv-unint
Następnie należy ją podmontować:
mount /dev/vg-unint/lv-unint /mnt/
Oraz specjalnie zawiesić, czyli wygenerujemy częsty problem podobny do utraty połączenia ze zdalnym udziałem NFS, jednak w tym przypadku lokalnie:
dmsetup suspend /dev/vg-unint/lv-unint
Dobrze, teraz spróbujmy coś zapisać do /mnt:
for i in $(seq 1 10) ; do bash -c "dd if=/dev/zero of=/mnt/unint.dump.${i} bs=1M count=2 &" ; done
Po chwili możemy sprawdzić wartości średniego obciążenia systemu oraz czy, a jeśli tak to ile, jakieś procesy przeszły w stan nieprzerwanego uśpienia:
nproc
2
uptime
08:38:47 up 9 days, 20:16, 1 user, load average: 12.00, 12.01, 12.05
ps auxf | awk '{if($8=="D") print $0;}'
root 876 0.0 0.0 0 0 ? D Jun25 0:00 \_ [ext4lazyinit]
root 883 0.0 0.0 108100 616 ? D Jun25 0:00 dd if=/dev/zero of=/mnt/unint.dump.1 bs=1M count=2
root 885 0.0 0.0 108100 616 ? D Jun25 0:00 dd if=/dev/zero of=/mnt/unint.dump.2 bs=1M count=2
root 887 0.0 0.0 108100 612 ? D Jun25 0:00 dd if=/dev/zero of=/mnt/unint.dump.3 bs=1M count=2
root 889 0.0 0.0 108100 612 ? D Jun25 0:00 dd if=/dev/zero of=/mnt/unint.dump.4 bs=1M count=2
root 892 0.0 0.0 108100 616 ? D Jun25 0:00 dd if=/dev/zero of=/mnt/unint.dump.5 bs=1M count=2
root 894 0.0 0.0 108100 616 ? D Jun25 0:00 dd if=/dev/zero of=/mnt/unint.dump.6 bs=1M count=2
root 897 0.0 0.0 108100 612 ? D Jun25 0:00 dd if=/dev/zero of=/mnt/unint.dump.7 bs=1M count=2
root 899 0.0 0.0 108100 612 ? D Jun25 0:00 dd if=/dev/zero of=/mnt/unint.dump.8 bs=1M count=2
root 902 0.0 0.0 108100 608 ? D Jun25 0:00 dd if=/dev/zero of=/mnt/unint.dump.9 bs=1M count=2
root 904 0.0 0.0 108100 612 ? D Jun25 0:00 dd if=/dev/zero of=/mnt/unint.dump.10 bs=1M count=2
root 1430 0.0 0.0 116624 1800 ? D Jun25 0:00 bash
Podczas wygenerowania takich procesów na jednym z serwerów, system był nadal responsywny, nie dochodziło do żadnego „dławienia” ani nie wykazywał nadmiernych opóźnień. Jest to potwierdzenie tego, że parametr średniego obciążenia prawdopodobnie nie jest miarą, którą chcesz obserwować i na której zamierzasz mocno polegać, ponieważ potrafi być niejednoznaczny. Pamiętajmy jednak, że nie zawsze monitorujemy wszystkie parametry (I/O dysku czy sieci), a nawet jeśli to robimy, to częste fluktuacje tych parametrów mogą powodować nieodpowiednie dostrojenie ich wartości. Parametr load average, mimo swojej niedoskonałości, pozwala w pewien sposób wskazać potencjalny problem i przestrzec przed sytuacją, w której w systemie zacznie dziać się coś niedobrego. Dla mnie parametr średniego obciążenia (oczywiście jeśli jego wartości są w miarę możliwości dobrze wyregulowane) jest zawsze powodem do zalogowania się do systemu i dokładnej analizy tego, co system aktualnie robi i jaki ma to wpływ na jego kluczowe komponenty oraz działanie usług, które są na nim uruchomione.
Monitorowanie obciążenia #
Monitorowanie obciążenia jest moim zdaniem jednym z ważniejszych zadań administracyjnych, i to niezależnie od zdania, że parametr ten jest raczej niemiarodajny. Pamiętajmy, że niekiedy ciężko monitorować inne wskaźniki takie jak wykorzystanie procesora, który jest również kluczowym parametrem, czy wykorzystanie dysku/sieci, ponieważ ulegają one częstym zmianom. Dlatego średnie obciążenie jest parametrem, którego nie należy ignorować, jednak w celu dokładnej analizy należy wspomóc się dodatkowymi narzędziami. Jeśli średnie obciążenia wskazują, że obciążenie rośnie i przekracza liczbę dostępnych procesorów, powinieneś przyjrzeć się przyczynie takiego stanu, tj. użyć dodatkowych narzędzi do zdiagnozowania problemów. Pamiętaj, że obciążenie powyżej liczby procesorów oznacza, że system musi ustawiać je w kolejce, co może prowadzić do zmniejszenia wydajności.
W takim przypadku top staje się de facto jednym z pierwszych narzędzi do pomiaru stanu twojego serwera. Jest on bardzo bogaty w informacje i pozwala podejrzeć wykorzystanie procesora, pamięci, stany jądra, priorytety procesu, właściciela procesu itd. Jeśli informacje zwracane przez to narzędzie wyglądają dobrze, to przeważnie nie może być żadnych problemów systemowych.
Ponadto, jednym z lepszych zestawów narzędzi do zbierania statystyk jest sysstat. W jego skład wchodzi kilka przydatnych poleceń:
sar- zbieranie i raportowanie informacji o aktywności systemumpstat- raportowanie statystyk globalnych i w podziale na poszczególne procesoryiostat- raportowanie użycia CPU oraz statystyk podsystemu wejścia/wyjścia dysków
Innym świetnym narzędziem do badania stanu obciążenia systemu, w tym kolejek uruchamiania oraz oczekiwania, jest vmstat.
Musisz jednak pamiętać, że lokalne narzędzia czasu rzeczywistego przydają się wtedy, gdy obciążenie nie przekracza możliwości obliczeniowych serwera i nie powoduje zatrzymania jego działania. Dlatego istotne jest zbieranie statystyk do kolektora (np. Zabbix) znajdującego się poza systemem tak, aby mieć wgląd, co się działo przed faktycznym wzrostem zapotrzebowania na zasoby systemu. Jeżeli obciążenie jest odpowiednio wysokie, system przestanie poprawnie działać i się zawiesi, a wtedy żadne narzędzie nie zbierze danych po tym zdarzeniu, co w konsekwencji doprowadzi do tego, że w panelu monitoringu zobaczysz przerwy.
Natomiast jednym z najczęstszych sposobów monitorowania średniego obciążenia jest wykorzystanie narzędzi Nagios/Icinga. Udostępniają one prosty plugin o nazwie check_load, który przyjmuje dwa główne parametry odpowiedzialne za wysyłanie powiadomień:
-w, --warning=WLOAD1,WLOAD5,WLOAD15
Exit with WARNING status if load average exceeds WLOADn
-c, --critical=CLOAD1,CLOAD5,CLOAD15
Exit with CRITICAL status if load average exceed CLOADn
the load average format is the same used by "uptime" and "w"
Po przekroczeniu jednej z trzech wartości parametru -w lub -c zostanie wysłane powiadomienie. Tylko jak ustawić odpowiednie wartości, aby powiadomienia były miarodajne i dały dobry obraz tego, co dzieje się w systemie? Zapoznaj się z odpowiedziami na pytanie What Warning and Critical values to use for check_load? jednak przede wszystkim musimy wiedzieć czym jest i w jaki sposób jest liczone średnie obciążenie — to już jednak wiemy. Przydałby się jeszcze jakiś miarodajny przelicznik (współczynnik), dlatego spójrz na poniższą tabelę:
Przeliczniki są przykładowe (tutaj akurat dla wagi A), jednak brałem pod uwagę zalecenia, tj. bezpieczne/dopuszczalne progi od 0.7/0.8 do 2.0. Oczywiście pamiętaj o dostosowaniu progów do swoich potrzeb. Na przykład, mając serwer z 16 rdzeniami, dostaniemy ostrzeżenie jeżeli średnie obciążenie przekroczy jedną z trzech wartości: 24, 16 lub 11.2.
Pamiętajmy, że powiadomienia typu CRITICAL powinny mieć ustawione większe progi, zgodnie z założeniem, że najpierw przychodzi WARNING, a następnie CRITICAL. Tak samo, średnie obciążenie z ostatnich 15 minut ma większą wagę niż średnie obciążenie z ostatniej minuty, ponieważ wskazuje, że przez dłuższy czas kolejka uruchamiania może być zapełniona, natomiast wartość z ostatniej minuty może wskazywać na coś niepokojącego, jednak najczęściej jest to krótki wzrost obciążenia lub początek długiego wzrostu, który może ulec znacznemu wygładzeniu w czasie. Dlatego krótkie czasy wskazują (mogą wskazywać) najczęściej na jednorazowe skoki, co jak już wiemy, jest sytuacją normalną.
Ponadto, co bardzo istotne, musimy brać pod uwagę ilość dostępnych rdzeni. Zgodnie z tym, wywołanie skryptu może być następujące (do jego poprawnego działania potrzebne są narzędzia nproc oraz bc):
# GNU/Linux
/usr/lib/nagios/plugins/check_load \
-w `bc <<< $(nproc)*1.5`,`bc <<< $(nproc)*1.0`,`bc <<< $(nproc)*0.7` \
-c `bc <<< $(nproc)*2.0`,`bc <<< $(nproc)*1.4`,`bc <<< $(nproc)*1.0`
# FreeBSD
alias nproc='sysctl -n hw.ncpu' ; /usr/local/libexec/nagios/check_load \
-w `bc <<< $(nproc)*1.5`,`bc <<< $(nproc)*1.0`,`bc <<< $(nproc)*0.7` \
-c `bc <<< $(nproc)*2.0`,`bc <<< $(nproc)*1.4`,`bc <<< $(nproc)*1.0`
Taki zapis pozwoli zachować przenośność między serwerami niezależnie od tego, ile posiadają dostępnych rdzeni procesora, jednak nie zostanie on poprawnie przetworzony i zwróci błąd, ponieważ należy wskazać wartości liczbowe, a nie komendy. Inną sprawą natomiast jest to, że sam plugin nie zwraca informacji, jaka dokładnie wartość została przekroczona. Na przykład po przekroczeniu progu CLOAD5, zostanie przysłany krytyczny alert bez jasnego wskazania, że chodzi o wartość z ostatnich pięciu minut.
Dlatego napisałem prosty skrypt shell’owy, który rozwiązuje następujące problemy:
- automatycznie wylicza odpowiednie wartości na podstawie ilości rdzeni
- jako parametry wywołania przyjmuje nie sztywno ustawione wartości, tylko przeliczniki, na podstawie których dopiero wylicza odpowiednie wartości
- przysyła szczegółową informację wskazującą na konkretny parametr, który został przekroczony
- jest kompatybilny z systemami GNU/Linux oraz BSD (nie wymaga instalacji dodatkowych paczek, nie wykorzystuje narzędzia
bc)
Narzędzie można pobrać stąd. Oto przykład wywołania:
./check_load.sh -w 1.5,1.0,0.7 -c 1.8,1.2,0.9
OK - loadavg: 5.27 5.47 5.54|vcpu: 16, load1=5.27,24.00,28.80 load5=5.47,16.00,19.20 load15=5.54,11.20,14.40
Podsumowując ten rozdział, aby uzyskać lepsze wskaźniki wskazujące bardziej na konkretne zasoby, tj. procesor, dyski lub sieć niż to, co przedstawia średnie obciążenie, głównie w celu zweryfikowania co się dokładnie dzieje w systemie, możesz użyć następujących narzędzi:
- wykorzystanie procesora, np. przy użyciu
top -1(lubtopa następnie wybrać1),mpstat -P ALL 1lubsar -u ALL 1- aby wyświetlić historię wykorzystania, np.
sar -u ALL
- aby wyświetlić historię wykorzystania, np.
- wykorzystanie procesora z rozbiciem na procesy, np.
pidstat 1lubpidstat -t 1- 10 procesów, które najbardziej wykorzystują CPU:
ps -eo pid,user,cmd,pri,pcpu,pmem --sort=-%cpu | head -n 10 - informacje o konkretnym procesie:
top -p <pid>
- 10 procesów, które najbardziej wykorzystują CPU:
- wyświetlenie kolejki uruchamiania i średniego obciążenia, np.
sar -q 1 - opóźnienie kolejki uruchamiania (harmonogramu) dla wątku, np.
/proc/<PID>/schedstats,delaystats,perf sched,runqlat - opóźnienie kolejki uruchamiania procesora, np.
/proc/schedstat,perf sched - długość kolejki uruchamiania, np.
vmstat 1(kolumna r),runqlen - wyświetlenie procesów, które coś robią (z pominięciem tych w stanie bezczynności), np.
top -i - całkowita liczba procesów tworzonych na sekundę i przełączeń kontekstu na sekundę, np.
sar -w 1 - ilość procesów w stanie nieprzerwanego uśpienia, np.
vmstat 1(kolumna b),ps auxf | awk '{if($8=="D") print $0;}'- można to sobie wrzucić do pętli, np.
while : ; do ps auxf | awk '{if($8=="D") print $0;}' ; sleep 1 ; done
- można to sobie wrzucić do pętli, np.
- wykorzystanie podsystemu I/O (dyski), np.
sar -b 1,iostat -x 1- aby zidentyfikować wykorzystanie poszczególnych urządzeń blokowych, np.
sar -d 1
- aby zidentyfikować wykorzystanie poszczególnych urządzeń blokowych, np.
- wykorzystanie podsystemu I/O (sieć), np.
sar -n DEV 1lubsar -n DEV,EDEV,TCP,IP,SOCK 1
Więcej informacji na ten temat znajdziesz w trzech genialnych prezentacjach:
- Linux Systems Performance
- Linux Performance Tools
- Linux Performance Analysis: New Tools and Old Secrets
Rozwiązywanie problemów ze zbyt wysokim obciążeniem #
Najprostszą (w pewnym sensie) reakcją i ukazującą natychmiastową poprawę jest dodanie większej liczby procesorów (rdzeni). W większości przypadków poprawi to wydajność serwera, jednak wiążę się ze zwiększonymi wydatkami na infrastrukturę. Nie zawsze jest to możliwe, dlatego przed podjęciem decyzji musimy dokładnie zdiagnozować, co nadmiernie obciąża serwer. Moim zdaniem, najważniejsze jest lepsze zrozumienie zachowania systemu. Zebranie większej ilości danych, monitorowanie, badanie i obserwacje mogą pomóc w znalezieniu słabych punktów systemu oraz głównego prowodyra większego obciążenia.
Powodów zwiększonego obciążenia może być jednak wiele. Z doświadczenia wiem, że jeśli widzimy duże obciążenie bez dużego obciążenia procesora, winowajcą może być podsystem I/O. Na przykład, może to być hypervisor, który ma pewne problemy z wydajnością, mogą to być użytkownicy zalogowani na serwerze i wykonujący jakieś „dziwne” operacje, może to być też cron, który odpala się cyklicznie i wykonuje jakieś operacje na danych, których akurat teraz może być bardzo dużo.
Problemy mogą być także spowodowane systemami/aplikacjami zewnętrznymi, które nadmiernie wykorzystują usługi uruchomione na serwerze, przez co problem z wydajnością wynikają głównie z dużej liczby połączeń sieciowych między dwoma systemami (warto wtedy zbadać nietypowy ruch sieciowy). Problemem mogą być także aplikacje na samym serwerze, które np. nie mają dostępu do jakiegoś zewnętrznego zasobu lub są napisane nieoptymalnie. Nie zapominajmy o sprzęcie, który może po prostu nie wyrabia ze względu na wiek (np. stare dyski z bardzo wysokim czasem reakcji lub niskiej jakości kontroler RAID).
W rzeczywistości nawet duża liczba średniego obciążenia niekoniecznie oznacza, że maszyna jest przeciążona lub przestaje reagować. Stany procesora (użytkownik, system czy bezczynność) są zwykle bardziej pomocne. Jeśli wystąpią prawdziwe problemy, dobrym początkiem jest uruchomienie np. vmstat -w 5 w terminalu na minutę lub dwie i obserwowanie wartości parametrów, które zwraca.
Na koniec, polecam tę niezwykle ciekawą dyskusję: Tracking load average issues.
Dodatkowe zasoby #
- Understanding the Linux Kernel, Third Edition
- Systems Performance: Enterprise and the Cloud
- Analyzing Computer System Performance with Perl::PDQ
- Linux Journal: Examining Load Average
- Linux Load Averages: Solving the Mystery
- System Load Average and cpu cores, Run Queue Part 1
- System Load Average and cpu cores, Run Queue Part 2
- Linux Magazine: Understanding load averages and stretch factors [PDF]
- The Linux Kernel, Chapter 4: Processes
- Red Hat Enterprise Linux 7 Performance Tuning Guide [PDF]