Redis: 3x Master i Source IP Load-Balancing
07 Oct 2020
database haproxy ip-hash nosql performance redis stick-table
W poprzednich artykułach dotyczących Redisa opisałem sytuacje, w których wykorzystujemy replikację asynchroniczną Master-Slave złożoną z kilku węzłów. Może się jednak zdarzyć, że nie będziesz potrzebował replikacji danych, instancje nie będą komunikować się ze sobą oraz nie będzie potrzeby zapewnienia mechanizmu przełączania awaryjnego.
W tym krótkim wpisie zaprezentuję właśnie taką sytuację, która może być niezwykle pomocna w przypadku danych tymczasowych takich jak sesje czy cache lub takich, które nie wymagają replikacji i odpowiedniego dbania.
Przed przystąpieniem do dalszego czytania, przypomnij sobie, jak we wpisie Redis: 3 instancje i replikacja Master-Slave cz. 3 przedstawiłem konfigurację HAProxy dostosowaną do wykrywania mistrza na podstawie odpytywania wszystkich instancji lub Sentineli i kierowania na tej podstawie ruchu tylko do instancji głównej.
Trzy instancje nadrzędne #
W prezentowanej konfiguracji każda z instancji będzie miała ustawione poniższe parametry:
### R1 ###
bind 192.168.10.10 127.0.0.1
port 6379
requirepass meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
### R2 ###
bind 192.168.10.20 127.0.0.1
port 6379
requirepass meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
### R3 ###
bind 192.168.10.30 127.0.0.1
port 6379
requirepass meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
Oczywiście pozostałe parametry tj. zapisy na dysk czy limity pamięci możesz dostosować do potrzeb aplikacji i środowiska. Ustawienie hasła nie jest wymagane, jednak w celu zachowania podstawowego poziomu bezpieczeństwa zostawimy je włączone (ponieważ wystawiamy instancje na interfejsach widocznych w sieci).
Konfigurację Redisa zaprezentowaną w tym wpisie przedstawia poniższy zrzut:

HAProxy i algorytmy równoważenia obciążenia #
Aby zaprezentowane rozwiązanie zadziałało, musimy zmodyfikować konfigurację HAProxy. Jedną z technik, którą możemy wykorzystać, jest zastosowanie algorytmu, który przypisuje klienta zawsze do tej samej instancji, na podstawie skrótu obliczanego ze źródłowego adresu IP. Druga technika jest niezwykle podobna, jednak polega na tymczasowym „przyklejeniu” klienta do aktualnie działającej instancji.
W obu przypadkach dobrym pomysłem jest zapewnienie odpowiedniego i regularnego czyszczenia danych (cache, sesji) na instancjach, do których ruch był kierowany, a już nie nie jest, tak, aby po ewentualnym ponownym przepięciu, nie doszło do czytania danych, które są nieaktualne. Rozwiązać to można za pomocą wygasania kluczy i odpowiedniej polityki eksmisji.
Pamiętajmy także o odpowiednim przetestowaniu wykorzystanego rozwiązania, po to, aby zrozumieć zachowanie obu mechanizmów i tego, jakie mogą mieć wpływ na działanie aplikacji.
Source IP Hash #
Technika ta wykorzystuje algorytm, który na podstawie adresu IP klienta tworzy unikatowy klucz, kojarzy go z jednym z serwerów docelowych i zapewnia podstawowy rodzaj trwałości sesji. Użytkownik jest kierowany do tego samego serwera w tej i kolejnych sesjach. Wyjątkiem jest sytuacja, gdy serwer jest niedostępny. Dlatego źródło o tym samym adresie IP będzie zawsze kierowane na ten sam serwer, natomiast jeśli adres IP jest dynamiczny, algorytm nie będzie w stanie połączyć swojej sesji z tym samym serwerem.
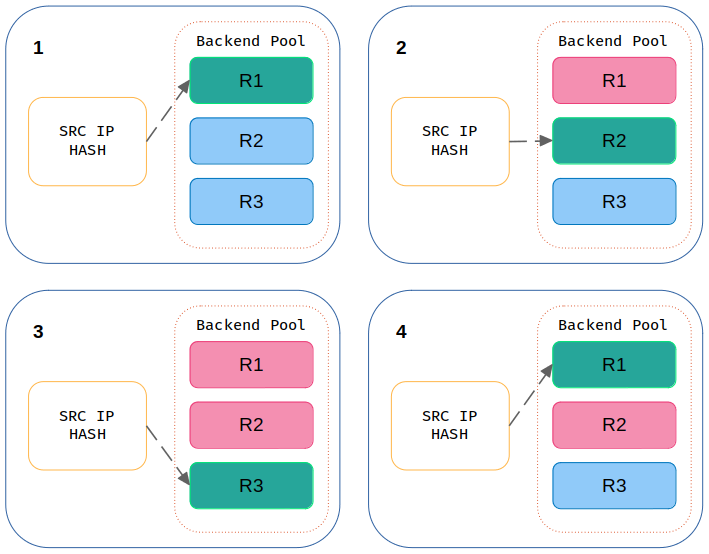
Oficjalna dokumentacja opisuje ten algorytm w ten oto sposób:
The source IP address is hashed and divided by the total weight of the running servers to designate which server will receive the request. This ensures that the same client IP address will always reach the same server as long as no server goes down or up. If the hash result changes due to the number of running servers changing, many clients will be directed to a different server. This algorithm is generally used in TCP mode where no cookie may be inserted.
Ponieważ skrót można ponownie wygenerować w przypadku zerwania sesji, ta metoda równoważenia obciążenia może zapewnić, że klient zostanie zawsze skierowany na ten sam serwer, z którego korzystał wcześniej. Oznacza to, że gdy HAProxy zobaczy nowe połączenia wykorzystujące tę samą informację (skrót), przekaże żądania do serwera skojarzonego z danym serwerem. Jest to przydatne, jeśli ważne jest, aby klient połączył się z sesją, która jest nadal aktywna po rozłączeniu i ponownym połączeniu.
Ta metoda równoważenia obciążenia zapewnia pewną trwałość, ponieważ wszystkie sesje z tego samego adresu źródłowego zawsze trafiają do tego samego rzeczywistego serwera. Dystrybucja jest jednak bezstanowa, więc jeśli dodamy nowy serwer lub usuniemy jeden z działających, dystrybucja zostanie zmieniona, a trwałość może zostać utracona. Tak samo w przypadku awarii, ponieważ przez pewien czas dane będą pobierane lub umieszczane na innym serwerze docelowym. Stąd należy pamiętać o odpowiednim ich czyszczeniu (wygasaniu).
Hashowanie na podstawie adresu IP działa w celu dystrybucji obciążenia na podstawie przychodzącego adresu IP żądania, dzięki czemu jest znacznie bardziej wyrafinowane. W tym trybie obciążenie ruchu rozkłada się równomiernie na wszystkie rzeczywiste backendy, jednak sesje nie są przypisywane w zależności od tego, jak zajęte są każde z nich.
Głównym problemem związanym z tym algorytmem jest to, że każda zmiana serwerów może przekierować żądanie na inny węzeł. Zwróć uwagę, że gdy serwer, który uległ awarii, stanie się ponownie dostępny, przypisani do niego klienci (określeni przez skrót) zostaną do niego ponownie przekierowani.
Poniżej znajduje się zmodyfikowana konfiguracja:
global
pidfile /var/run/haproxy.pid
log 127.0.0.1 local0 info
user haproxy
group haproxy
maxconn 512
nbproc 2
nbthread 2
defaults redis
mode tcp
timeout connect 4s
timeout server 10s
timeout client 10s
log global
option tcplog
frontend http
bind *:8080
default_backend stats
backend stats
mode http
stats enable
stats uri /
stats refresh 5s
stats show-legends
stats auth ha-admin:piph1NeiceHe
frontend ft_redis
bind :16379 name redis
default_backend bk_redis
backend bk_redis
log global
balance source
hash-type consistent
server R1 192.168.10.10:6379 check inter 1s
server R2 192.168.10.20:6379 check inter 1s
server R3 192.168.10.30:6379 check inter 1s
Source IP Stick-Table #
Niektóre aplikacje wymagają „lepkości” między klientem a serwerem. Oznacza to, że wszystkie żądania od klienta muszą być wysyłane do tego samego serwera także w sytuacjach, w których dojdzie do awarii aktualnej instancji. W przeciwnym razie sesja aplikacji może zostać zerwana, co może mieć negatywny wpływ na klienta.
W tym trybie HAProxy tworzy w pamięci specjalną tabelę do przechowywania stanu związanego z przychodzącymi połączeniami, indeksowaną przez klucz, taki jak adres IP klienta. Gdy klient jest przypisany do danego serwera, pozostaje on przypisany do momentu wygaśnięcia wpisu w tabeli lub jego awarii.
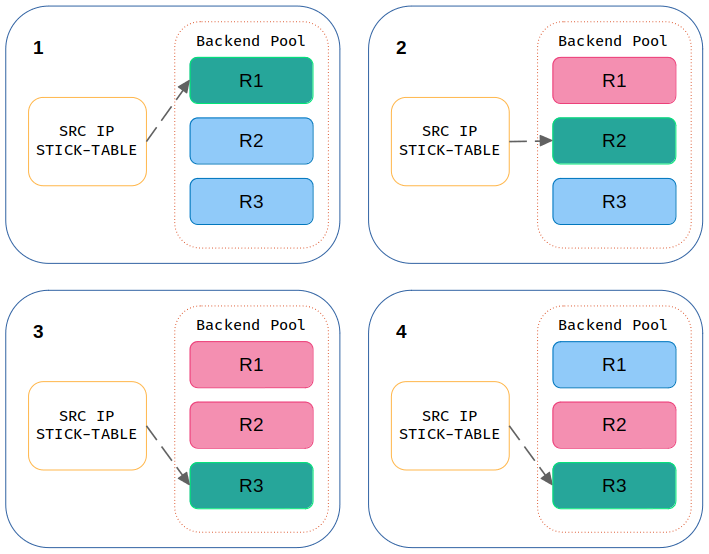
Jedną z głównych cech stosowania algorytmu Stick-Table jest to, że po powrocie serwera, który uległ awarii, żadne istniejące sesje nie zostaną do niego przekierowane. Stąd wynika właśnie jego lepkość, która trzyma się aktualnie działającego i przypisanego serwera do żądania, ale tylko przez określony czas lub do momentu awarii instancji, do której był kierowany ruch. Nie wynika z niej natomiast, że HAProxy będzie zawsze kierować ruch do już raz przypisanego serwera (ten problem rozwiązuje algorytm Source IP Hash).
HAProxy umożliwia synchronizowanie tabel w pamięci między wieloma instancjami, dzięki czemu przełączanie awaryjne może być przezroczyste.
Konfiguracja tego algorytmu w HAProxy nie jest tak oczywista jak w przypadku skrótów. Pojawia się tutaj kilka parametrów:
- type - decyduje o klasyfikacji danych, które będziemy przechwytywać (np. źródłowy adres IP)
- size - określa liczbę wpisów, które będziemy przechowywać (1k = 100000; 1 wpis ~ 50B, 1k wpisów ~ 5MB)
- expire - określa, jak długo (TTL) ma być przechowywany wpis w tabeli (jest to czas kiedy należy usunąć dane od ostatniego dopasowania, utworzenia lub odświeżenia rekordu w tabeli)
Pozwolę sobie przytoczyć ciekawe wyjaśnienie tych parametrów, które zostało opisane w artykule Better Rate Limiting For All with HAProxy:
stick-table type ip size 200k expire 3m - This declares a table to store the source IP addresses that is up to 200,000 entries long. Each IP entry is about 50 bytes and the connection rate and bytes out rate are 12 bytes each which are stored with each source IP address. So at 74 Bytes an entry we are looking at a possible 14 MBytes of usage for this table. The expire argument is how long to keep an entry in the table (In this case it just needs to be twice the length of the longest rate argument for a smoothed average).
Dzięki powyższym opcjom jesteśmy w stanie utworzyć pamięć typu Stick-Table i śledzić za jej pomocą dane. Poniżej znajduje się zmodyfikowana konfiguracja:
global
pidfile /var/run/haproxy.pid
log 127.0.0.1 local0 info
user haproxy
group haproxy
maxconn 512
nbproc 2
nbthread 2
defaults redis
mode tcp
timeout connect 4s
timeout server 10s
timeout client 10s
log global
option tcplog
frontend http
bind *:8080
default_backend stats
backend stats
mode http
stats enable
stats uri /
stats refresh 5s
stats show-legends
stats auth ha-admin:piph1NeiceHe
frontend ft_redis
bind :16379 name redis
default_backend bk_redis
backend bk_redis
log global
stick-table type ip size 3 expire 30m
stick on src
server R1 192.168.10.10:6379 check inter 1s
server R2 192.168.10.20:6379 check inter 1s
server R3 192.168.10.30:6379 check inter 1s
Priorytety backendów #
HAProxy pozwala na nadanie odpowiedniego priorytetu serwerom, które widzi w warstwie backendu. Służy do tego parametr weight, który dostosowuje wagę serwera w stosunku do innych serwerów. Wszystkie serwery otrzymają obciążenie proporcjonalne do ich wagi w stosunku do sumy wszystkich wag, więc im wyższa waga, tym do serwera zostanie dostarczona większa ilość żądań.. Domyślna waga to 1, a maksymalna to 256, przy czym wartość 0 pomija serwer z listy.
Waga każdego serwera to stosunek zadeklarowanej wagi tego serwera do sumy wszystkich zadeklarowanych wag. Tak więc przy 2 serwerach możesz po prostu użyć wartości 30 i 70, a dystrybucja będzie następująca: 30 ÷ (30 + 70 ) = 0,3 i 70 ÷ (30 + 70) = 0,7. W normalnym trybie rozkładania obciążenia tj. roundrobin, serwer, który „waży więcej”, otrzymuje proporcjonalnie więcej żądań. Oczywiście nic nie stoi na przeszkodzie, abyś używał wartości 3 i 7, 33 i 77 lub innych kombinacji w zakresie od 1 do 256. Zaleca się jednak, aby suma wszystkich wag była równa 100, ponieważ taki zapis jest bardziej przyjazny w zrozumieniu.
Wspominam o tym, ponieważ obie opisane wyżej techniki mają pewną wadę, która powoduje, że gdy klient puka do HAProxy na jednym z nich, to nie ma nigdy pewności, że żądania trafią do lokalnej instancji Redis. Nie jest to oczywiście wielką tragedią, jednak moim zdaniem, warto, aby żądania były kierowane zawsze do najbliższej instancji Redis jeśli każda z nich aktualnie działa. Jeśli ta będąca najbliżej ulegnie awarii, to oczywiście zrozumiałe jest, że proces HAProxy uruchomiony na tej samej maszynie będzie komunikował się z Redisem, który działa na innym węźle.
Taką priorytetyzację możemy zastosować dla obu opisanych technik. Na przykład dla algorytmu obliczającego skrót, ustawienie wag może wyglądać jak poniżej:
### H1 ###
[...]
server R1 192.168.10.10:6379 weight 50 check inter 1s
server R2 192.168.10.20:6379 weight 35 check inter 1s
server R3 192.168.10.30:6379 weight 15 check inter 1s
### H2 ###
[...]
server R1 192.168.10.10:6379 weight 35 check inter 1s
server R2 192.168.10.20:6379 weight 50 check inter 1s
server R3 192.168.10.30:6379 weight 15 check inter 1s
### H3 ###
[...]
server R1 192.168.10.10:6379 weight 15 check inter 1s
server R2 192.168.10.20:6379 weight 50 check inter 1s
server R3 192.168.10.30:6379 weight 35 check inter 1s
Co oznacza, że na węźle, na którym działa HAProxy (H1) i do którego łączy się klient, ruch będzie kierowany zawsze do lokalnej instancji R1 (która działa tam, gdzie HAProxy). To samo dla pozostałych węzłów, tj. ruch kierowany do H2 będzie zawsze kierowany do instancji nadrzędnej R2. W przypadku H3 będzie podobnie, ruch będzie zawsze kierowany do instancji R3. Jeżeli taka lokalna instancja Redis przestanie działać, ruch od klienta przechodzący przez HAProxy będzie kierowany do instancji w zależności od wagi, czyli w powyższym przykładzie do procesu o wadze 5.
Widzimy, że parametr wagi zaburza w pewien sposób działanie obu algorytmów i w obu przypadkach nie należy go traktować jako wskaźnika, który określa ile żądań (obciążenia) zostanie skierowanych do danego serwera w warstwie backendu. Określa on raczej priorytet, na podstawie którego dana instancja będzie otrzymywała żądania a jeśli ulegnie awarii, jej rolę przejmie kolejny serwer z ustawionym wyższym priorytetem niż pozostałe. Trwałość czy lepkość zostaje nadal zachowana, ponieważ żądania będą nadal kierowane do danej instancji.