Rozwiązywanie nazw i DNS Sinkhole
03 Oct 2020
W tym wpisie chciałbym poruszyć niezwykle ciekawy temat związany z bezpieczeństwem najbardziej znanego i wykorzystywanego systemu rozwiązywania nazw, jakim jest DNS. Z racji tego, że protokół DNS ma krytyczne znaczenie dla wszelkich operacji w sieci, administratorzy powinni wzmocnić swoje serwery i wykorzystać dostępne mechanizmy, aby zapobiec potencjalnym atakom. Istnieje wiele technik, które można wykorzystać do zapobiegania takim nadużyciom, natomiast dzisiaj opiszę jedną z nich, która niekoniecznie poprawia bezpieczeństwo samego serwera, a bardziej pozwala na ochronę pozostałych systemów oraz użytkowników.
Technika DNS Sinkholing (ang. sinkhole — lej) lub DNS Blackholing (ang. blackhole — czarna dziura), o której będziemy rozmawiać, jest używana do świadomego fałszowania wyników zwracanych z kontrolowanych przez administratora serwerów DNS. Dzięki temu jesteśmy w stanie ograniczyć lub odmówić dostępu do określonej domeny czy strony internetowej zwracając dla niej wskazany przez nas, zamiast oryginalnego, adres IP.
Gdy użytkownik próbuje uzyskać dostęp do sinkholowanej domeny może zostać mu zwrócony zasób z informacjami opisującymi ograniczenia lub może być skierowany do specjalnego miejsca w sieci lokalnej tak, aby zapobiec wejścia na zainfekowaną domenę/stronę. Widzisz, że sinkhole jest takim specjalnym miejscem, do którego kierowany jest, w sposób kontrolowany, ruch, który w normalnych warunkach byłby skierowany np. do złośliwej domeny.

Oczywiście technika ta może zostać użyta do niecnych celów, ponieważ każdy może mieć taki rodzaj serwera, jednak kluczowe jest to, że ma on wpływ najczęściej tylko na systemy, które używają tego konkretnego serwera DNS do rozpoznawania nazw (czyli np. wewnątrz sieci firmowej). Oczywiście główne serwery DNS lub serwery DNS kontrolowane przez dostawców usług internetowych będą miały wpływ na większą liczbę maszyn.
To tyle tytułem wstępu. Przejdźmy do dalszej części artykułu, w której przypomnimy sobie, jak działa DNS oraz cały proces leżący u podstaw tego systemu w typowej dystrybucji GNU/Linux. Następnie omówię trochę dokładniej technikę sinkholingu i zaprezentuję kilka możliwości zbudowania własnego serwera wykorzystującego ten mechanizm.
DNS i mechanizm rozwiązywania nazw #
DNS (ang. Domain Name System) jest jedną z kluczowych części komunikacji, która pozwala na konwertowanie nazw alfabetycznych na numeryczne adresy. Dzięki temu, mając odpowiednio skonfigurowany serwer DNS, jesteśmy w stanie odpytywać go np. o adresy IP szukanych domen, które przechowuje.
Protokół DNS został dokładnie opisany w kilku dokumentach RFC. Dwoma głównymi są RFC 1034 - Domain Names - Concepts And Facilities oraz RFC 1035 - Domain Names - Implementation And Specification. Warto także zajrzeć do RFC 2671 - Extension Mechanisms for DNS, a także RFC 8499 - DNS Terminology Przeglądając je, znajdziesz w nich odnośniki to starszych wersji.
Jak dobrze wiemy, każdemu urządzeniu podłączonemu do sieci nadawany jest adres IP, który jest niezbędny do zlokalizowania go w sieci oraz wymiany komunikacji. Na przykład, gdy chcemy załadować stronę internetową znajdującą się na zdalnym serwerze, musi nastąpić tłumaczenie między tym, co wpisujemy w swojej przeglądarce (np. example.com), a zrozumiałym dla urządzeń i protokołów adresem IP (np. 192.168.10.25) niezbędnym do zlokalizowania danego zasobu. Ten proces tłumaczenia ma kluczowe znaczenie dla ładowania każdej strony internetowej i jest ściśle związany z mechanizmem rozwiązywania nazw za pomocą protokołu DNS.
DNS może korzystać z obu protokołów warstwy transportu i domyślnie używa portu docelowego o numerze 53. Gdy wykorzystywany jest UDP, mamy możliwość obsługi retransmisji i sekwencjonowania UDP. Natomiast protokół TCP jest najczęściej wykorzystywany, gdy rozmiar żądania lub odpowiedzi jest większy niż pojedynczy pakiet, na przykład w przypadku odpowiedzi, które mają wiele rekordów, w przypadku odpowiedzi IPv6 lub większości odpowiedzi DNSSEC.
To, co wpisujemy w przeglądarce, nazywamy nazwą domenową (lub po prostu domeną). Każda taka nazwa składa się z co najmniej jednej etykiety. Etykiety są oddzielone znakiem . tworząc w pełni kwalifikowaną nazwę (ang. FQDN - Fully Qualified Domain Name) — czyli pełną nazwę domeny dla określonego komputera lub hosta. Etykiety są konstruowane od prawej strony do lewej, gdzie etykieta po prawej stronie jest domeną najwyższego poziomu (ang. TLD - Top Level Domain). Na przykład mając domenę foo.bar.example.com etykieta znajdująca się najbardziej po prawej stronie, tj. .com będzie etykietą TLD.
Główną elementem, na którym operują klienci i serwery DNS są rekordy zasobów (ang. RR - Resource Records). Są to wpisy w bazie danych DNS, które zawierają informacje o hostach. Rekordy są fizycznie przechowywane w plikach stref na serwerze DNS. Na przykład rekordy mapowania adresów oznaczany jest za pomocą litery A i odpowiadają za przechowywanie nazwy hosta wraz z przypisanym do niego adresem IPv4. Innym typem rekordu jest rekord serwera nazw oznaczana za pomocą ciągu NS, który identyfikuje serwery nazw odpowiedzialne za twoją strefę DNS dla konkretnej domeny. Aby mieć prawidłową konfigurację DNS, rekordy NS skonfigurowane w strefie muszą być dokładnie takie same, jak te skonfigurowane jako serwery nazw u dostawcy nazwy domeny.
W jaki sposób jednak operujemy na rekordach? Wszystko odbywa się za pomocą zapytań (ang. queries). Pierwszym typem zapytań są zapytania rekurencyjne (ang. recursive). Szukając wartości danego rekordu, klient zazwyczaj kontaktuje się z lokalnym serwerem DNS w celu uzyskania odpowiedzi. Serwer musi udzielić odpowiedzi — dlatego odpowiada albo odpowiednim rekordem, albo komunikatem o błędzie, jeśli nie można go znaleźć.
Jednak przed zwróceniem błędu serwer wysyła zapytania do innego serwera DNS w imieniu oryginalnego klienta. Zapytanie rekurencyjne to rodzaj zapytania, w którym serwer DNS, który otrzymał Twoje zapytanie, wykona całą pracę polegającą na pobraniu odpowiedzi i zwróceniu jej, ponieważ podczas tego procesu serwer DNS może, również w Twoim imieniu, wysyłać zapytania do innych serwerów DNS, aby uzyskać odpowiedź. Widzimy, że klient prosi lokalny serwer DNS o wykonanie wszystkich potrzebnych żądań w jego imieniu.
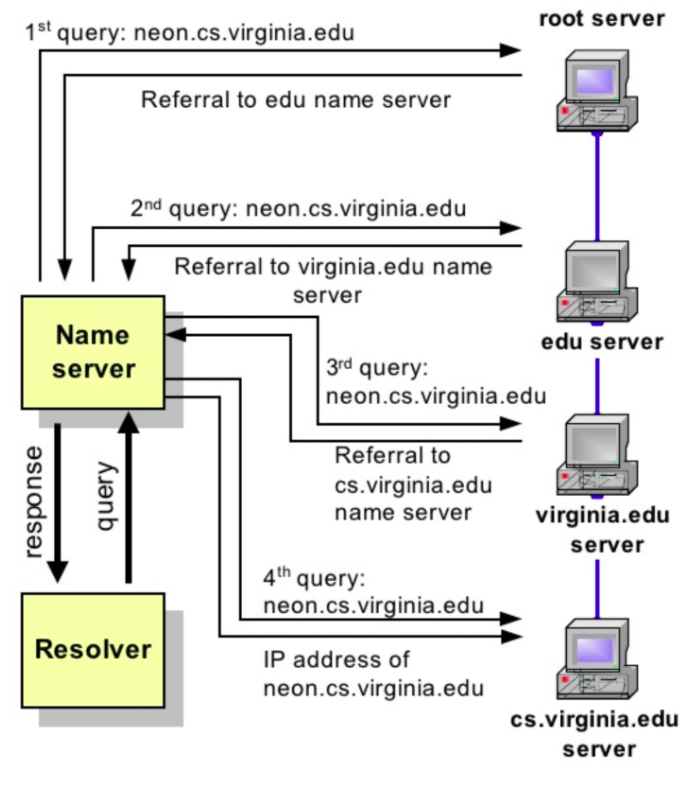
Drugim typem zapytań są zapytania iteracyjne (ang. iterative). W tym typie zapytań zachowanie jest podobne, jednak jeśli serwer nie ma w swojej pamięci odpowiedniego rekordu, kieruje klienta DNS bezpośrednio do serwera głównego. Ten typ serwera prześle następnie lokalizację serwerów TLD, z którymi skontaktuje się klient. Następnie klient kontaktuje się z następnym serwerem nazw w łańcuchu, aż do znalezienia i osiągnięcia serwera zawierającego pełną nazwę FQDN. Widzimy, że klient musi powtórzyć zapytanie bezpośrednio na serwerach DNS i to on wykonuje całą pracę samodzielnie, aż do ostatecznego rozstrzygnięcia szukanej nazwy. Co istotne, dowolny klient DNS może wykonywać zapytania iteracyjne, jednak nie jest to zalecane.
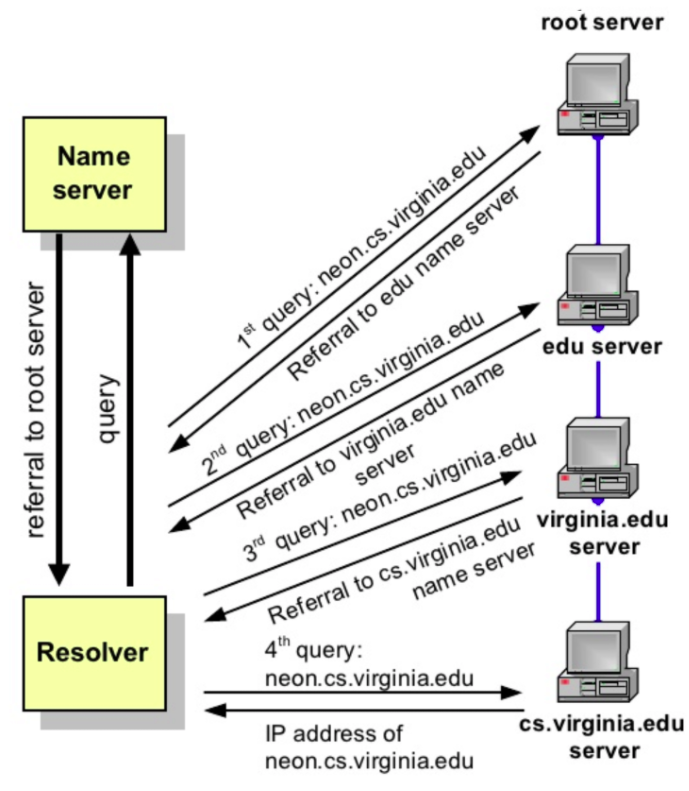
Ostatnim typem zapytań są zapytania nierekurencyjne (ang. non-recursive). W tym typie zapytań klient otrzymuje odpowiedź od razu, ponieważ serwer DNS przechowuje ją w lokalnej pamięci podręcznej, albo wysyła zapytanie do serwera nazw DNS, który jest autorytatywny dla rekordu, co oznacza, że na pewno ma poprawny adres IP dla tej nazwy hosta. W obu przypadkach nie ma potrzeby wykonywania dodatkowych rund zapytań (jak w przypadku zapytań rekurencyjnych). Zamiast tego odpowiedź jest natychmiast zwracana klientowi.
Dobrze, omówmy w takim razie cały proces, jaki odbywa się podczas rozwiązywania nazwy domenowej, ponieważ jego zrozumienie jest kluczowe. Wygląda on podobnie do poniższego diagramu w typowym systemie GNU/Linux:
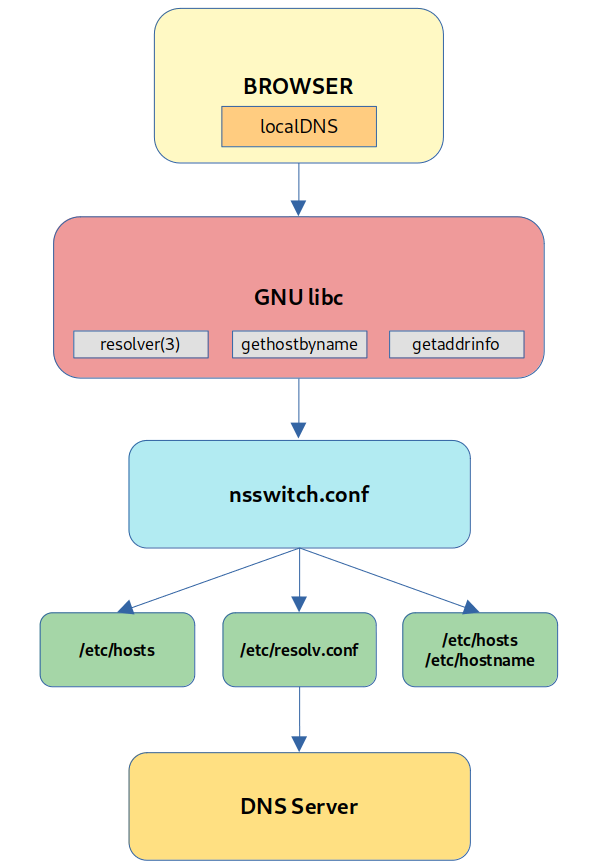
Sam mechanizm i wszystkie kroki od wpisania w przeglądarce nazwy do uzyskania adresu IP a w konsekwencji wyświetlenia danego zasoby jest niezwykle fascynujący.
Klient (przeglądarka) #
Wpisując np. w przeglądarce adres example.com, w pierwszej kolejności przeglądarka sprawdza, czy domena znajduje się w jej lokalnej pamięci podręcznej. Jeśli odwiedzałeś jakiś czas temu tę domenę, przeglądarka może już wiedzieć, jaki jest jej adres IP i mieć tę wartość w swoim lokalnym buforze.
Pamięć podręczna przeglądarki zwykle przechowuje obiekty dosyć krótko, a nie dłużej niż poprzez parametr czasu życiu (ang. Time to Live) — czyli adres jest przechowywany tak długo, jak został określony za pomocą tego parametru. Z drugiej strony, przeglądarki komunikują się z lokalnym resolverem więc TTL nie powinien mieć większego znaczenia. Po trzecie, przeglądarki posiadają wbudowane opcje, które sterują czasem życia rekordów, np. Firefox posiada parametry konfiguracyjne: network.dnsCacheExpiration i network.dnsCacheExpirationGracePeriod z domyślną wartością 60 sekund. Google Chrome i wbudowany wewnętrzny mechanizm rozpoznawania nazw DNS ignoruje TTL rekordów DNS i buforuje żądania DNS także przez 60 sekund.
Przy okazji wspomnę, że rekordy DNS mają parametr TTL, który jest ustawiany na autorytatywnych serwerach przez właściciela domeny.
GNU libc #
Przejdźmy dalej. Jeśli przeglądarka nie znajdzie odpowiedniego wpisu w swojej pamięci podręcznej, zacznie szukać dalej, aby przeprowadzić wyszukiwanie. I tutaj pojawia się kilka ciekawych kwestii.
Po pierwsze, istnieje kilka sposobów rozwiązywania nazw na tym poziomie i tak naprawdę nie ma jednej metody uzyskania wyszukiwania DNS. W systemie GNU/Linux istnieje biblioteka GNU libc, która dostarcza trzy różne interfejsy rozpoznawania nazw. Istnieje niskopoziomowa implementacja BSD resolver(3), jest także funkcja gethostbyname i powiązane z nią dodatkowe funkcje, które implementują przestarzałą specyfikację POSIX, a także nowoczesna implementacja rozwiązywania nazw getaddrinfo zgodne ze standardem POSIX.
Zajmijmy się tymi dwoma ostatnimi. W oficjalnej dokumentacji biblioteki libc zostały opisane tak:
You can use gethostbyname, gethostbyname2 or gethostbyaddr to search the hosts database for information about a particular host. The information is returned in a statically-allocated structure; you must copy the information if you need to save it across calls. You can also use getaddrinfo and getnameinfo to obtain this information.
O ile nie określono inaczej, funkcja gethostbyname używa domyślnej kolejności, tj. próbuje uzyskać wynik z lokalnego pliku /etc/hosts lub używa pliku /etc/resolv.conf w celu określenia (rozpoznaje serwery nazw domen zgodnie z opisem w dokumencie RFC 883) serwera DNS i wysłania do niego zapytania w celu uzyskania nazwy.
gethostbynamesprawdza, czy nazwa hosta może być rozwiązana przez odniesienie w lokalnym pliku (którego lokalizacja różni się w zależności od systemu operacyjnego) przed podjęciem próby odpytania serwera DNS. Jeśligethostbynamenie ma rekordu w pamięci podręcznej ani nie może go znaleźć w plikuhosts, wysyła żądanie do serwera DNS skonfigurowanego w stosie sieciowym najczęściej właśnie przez plik lokalnego resolwera. Zazwyczaj jest to router lokalny lub buforujący serwer DNS usługodawcy internetowego.
Druga z funkcji, tj. getaddrinfo także służy do wyszukiwania DNS. Jest jednak znacznie bardziej zaawansowana (i bardziej przeładowana), ponieważ po drodze wywołuje znacznie więcej wywołań systemowych, tj. odczyt plików systemowych, ładowanie bibliotek czy otwieranie dodatkowych gniazd. Spójrz poniżej na statystyki ilości wywołań:
strace -c ./gethostbyname.out
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
0.00 0.000000 0 10 read
0.00 0.000000 0 1 write
0.00 0.000000 0 10 close
0.00 0.000000 0 1 stat
0.00 0.000000 0 9 fstat
0.00 0.000000 0 2 lseek
0.00 0.000000 0 13 mmap
0.00 0.000000 0 5 mprotect
0.00 0.000000 0 2 munmap
0.00 0.000000 0 3 brk
0.00 0.000000 0 1 1 access
0.00 0.000000 0 2 socket
0.00 0.000000 0 2 2 connect
0.00 0.000000 0 1 execve
0.00 0.000000 0 1 arch_prctl
0.00 0.000000 0 8 openat
------ ----------- ----------- --------- --------- ----------------
100.00 0.000000 0 71 3 total
strace -c ./getaddrinfo.out
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
0.00 0.000000 0 12 read
0.00 0.000000 0 1 write
0.00 0.000000 0 14 close
0.00 0.000000 0 1 stat
0.00 0.000000 0 11 fstat
0.00 0.000000 0 2 lseek
0.00 0.000000 0 13 mmap
0.00 0.000000 0 5 mprotect
0.00 0.000000 0 2 munmap
0.00 0.000000 0 3 brk
0.00 0.000000 0 1 1 access
0.00 0.000000 0 5 socket
0.00 0.000000 0 4 2 connect
0.00 0.000000 0 1 sendto
0.00 0.000000 0 3 recvmsg
0.00 0.000000 0 1 bind
0.00 0.000000 0 3 getsockname
0.00 0.000000 0 1 execve
0.00 0.000000 0 1 arch_prctl
0.00 0.000000 0 9 openat
------ ----------- ----------- --------- --------- ----------------
100.00 0.000000 0 93 3 total
Oczywiście jest to przykład prostych programów napisanych w C odpytujących lokalnego hosta.
Generalnie tuż przed żądaniem DNS proces wykonuje wywołania systemowe i, jeśli trzeba rozwiązań nazwę z serwera DNS, pobiera adres IP serwera z pliku /etc/resolv.conf (niezależnie od używanej aplikacji, system operacyjny wyśle zapytania DNS do serwerów DNS określonych w tym pliku). getaddrinfo pobiera informacje z /etc/hosts, czytając ten plik w całości za każdym razem, gdy wywołasz klienta.
Co niezwykle ciekawe, po uzyskaniu adresów IP przez tę funkcję, nie zwraca ona od razu odpowiedzi do klienta, tylko przeprowadza dodatkowo testy tych adresów, otwierając do nich gniazda i łącząc się z nimi:
socket(AF_INET, SOCK_DGRAM|SOCK_CLOEXEC, IPPROTO_IP) = 3
connect(3, {sa_family=AF_INET, sin_port=htons(0), sin_addr=inet_addr("172.217.20.206")}, 16) = 0
getsockname(3, {sa_family=AF_INET, sin_port=htons(48043), sin_addr=inet_addr("192.168.43.56")}, [28->16]) = 0
close(3) = 0
socket(AF_INET6, SOCK_DGRAM|SOCK_CLOEXEC, IPPROTO_IP) = 3
connect(3, {sa_family=AF_INET6, sin6_port=htons(0), sin6_flowinfo=htonl(0), inet_pton(AF_INET6, "2a00:1450:401b:805::200e", &sin6_addr), sin6_scope_id=0}, 28) = -1 ENETUNREACH (Network is unreachable)
close(3)
Oraz nie buforuje odpowiedzi (ogólnie obie nie buforują, aby zapewnić taką funkcję można użyć demona nscd), więc kolejne połączenia także są dosyć kosztowne przy jej wykorzystaniu.
Interesujące jest także to, że żaden z wymienionych wyżej plików nie jest znany procesom tak po prostu. Taką wiedzę uzyskują one dopiero po załadowaniu specjalnych współdzielonych bibliotek w czasie swojego wykonywania. Na przykład wywołując obie funkcje w dystrybucji Debiano podobnej:
/etc/hostsjest znany z poziomulibnss_files.so.2/etc/resolv.confjest znany z poziomulibnss_dns.so.2
nsswitch.conf #
Aby jeszcze bardziej skomplikować sprawę, musimy mieć świadomość, że proces pobiera listę takich źródeł w czasie wykonywania z innego pliku, tj. /etc/nsswitch.conf. Tak naprawdę GNU libc umożliwia skonfigurowanie kolejności, w jakiej funkcja czy proces, który z niej korzysta, próbuje uzyskać dostęp do usługi. Jest to kontrolowane właśnie przez plik nsswitch.conf. W przypadku dowolnej funkcji wyszukiwania obsługiwanej przez GNU libc plik ten zawiera wiersz z nazwami usług, które mają być używane.
Jeżeli chodzi o mechanizm rozwiązywania nazw, plik ten oczywiście przyjmuje różne wartości w zależności od systemu. Na przykład, w systemie FreeBSD 12.1 wygląda on tak:
hosts: files dns
Co oznacza taki wpis? Mówi on, że aby znaleźć hosta, najpierw należy odpytać bibliotekę libnss_files.so. Jeśli to się nie powiedzie, należy odpytać bibliotekę libnss_dns.so. W dystrybucji CentOS 7.7 wpis hosts w tym pliku wygląda następująco:
hosts: files dns myhostname
Jest on niezwykle podobny, jednak posiada dodatkową wartość. W tym wypadku mówi on, że aby znaleźć hosta, najpierw należy odpytać bibliotekę libnss_files.so. Jeśli to się nie powiedzie, należy odpytać bibliotekę libnss_dns.so. Jeżeli obie próby zakończą się niepowodzeniem, odpytaj bibliotekę libnss_myhostname.so. Oczywiście w zależności od systemu czy dystrybucji wartości mogą znajdować się na innym miejscu.
Widzimy, że z poziomu pliku nsswitch.conf możemy zmuszać funkcje gethostbyname i getaddrinfo do wypróbowywania każdej z wymienionych usług, np. do przeszukiwania serwera DNS przed plikiem /etc/hosts. Jeśli wyszukiwanie powiedzie się, zwracany jest wynik, w przeciwnym razie sprawdzona zostanie następna usługa z listy.
Praktycznie w każdym systemie i dystrybucji plik hosts ma pierwszeństwo przed pozostałymi usługami. Informacje o nazwie hosta, mogą się jednak zmieniać bardzo często, więc w niektórych sytuacjach serwer DNS powinien zawsze mieć najdokładniejsze dane, podczas gdy lokalny plik hostów traktowany jest jako kopia zapasowa tylko na wypadek awarii.
We wpisie hosts pliku
nsswitch.confmoże pojawić się jeszcze coś takiego jak mDNS. Jeżeli chcesz uzyskać więcej informacji na ten temat zerknij na odpowiedź mDNS or Multicast DNS service.
Wróćmy na chwilę do klientów i programów wykorzystujących omawiane funkcje. Mógłbyś pomyśleć: skoro każde z tych narzędzi uzyskuje ten sam wynik, więc na pewno wykorzystują te same mechanizmy. Tak naprawdę, różne programy uzyskują adres IP adresu na różne sposoby. Na przykład polecenie ping wykorzystuje mechanizm nsswitch, który z kolei może wykorzystać plik /etc/hosts, /etc/resolv.conf lub własnej nazwy hosta, aby uzyskać wynik.
Nie wszystkie narzędzia wykorzystują taki oto sposób. Na przykład komenda host jest typowym poleceniem służącym do odpytywania serwerów DNS. Wykorzystuje ona plik /etc/resolv.conf do ustalenia, które serwery DNS odpytać w celu uzyskania nazwy szukanego hosta. Tak naprawdę większość programów odwołuje się do tego pliku (jeśli zajdzie taka potrzeba) przy określaniu, który serwer DNS należy wykorzystać.
Podobnie sytuacja wygląda z narzędziem nslookup czy poleceniem ping. Pierwsze z nich wymusi wyszukiwanie DNS, podczas gdy ping będzie używać normalnej kolejności wyszukiwania nazw.
Zewnętrzne serwery DNS #
Jeżeli procesom działającym w Twoim systemie nie udało się uzyskać adresu IP szukanej nazwy — pozostaje ostatni krok — czyli odpytanie zewnętrznych serwerów DNS. Jeśli wpiszesz w przeglądarce host1.b.example.com mechanizmy systemu operacyjnego w pierwszej kolejności spróbują przeszukać pamięć podręczną DNS i wszelkie dostępne źródła zewnętrzne. W tym celu wyślą zapytanie do skonfigurowanego serwera DNS z pytaniem właśnie o tę domenę.
Rozwiązywanie nazwy nigdy nie opiera się na jednym serwerze DNS (chyba że buforuje on odpowiednie rekordy i jest w stanie zwrócić odpowiedź do klienta natychmiast) i jest to proces, w którym zaangażowanych jest kilka różnych typów serwerów, tj. serwer główny, serwer TLD i serwer autorytatywny, które muszą dostarczyć informacji, aby zakończyć wyszukiwanie. W przypadku buforowania serwery mogą zapisać odpowiedź na zapytanie podczas poprzedniego wyszukiwania, a następnie dostarczyć ją bezpośrednio z pamięci. Ostatecznie cały ten łańcuch serwerów DNS pozwala znaleźć adres IP domeny i zwrócić wynik go do klienta, aby mógł uzyskać dostęp do właściwej witryny internetowej.
Jak już wiesz, w pierwszej kolejności odpytane zostaną serwery DNS ustawione w pliku /etc/resolv.conf. Mogą to być rekursywne serwery DNS, tj. Google (8.8.8.8, 8.8.4.4), lub CloudFlare (1.1.1.1, 1.0.0.1). Pełną listę publicznych serwerów DNS znajdziesz na przykład w Public DNS Server List. Najczęściej jednak „najbliższym” serwerem jest serwer w sieci lokalnej, który jeśli nie posiada informacji o szukanej domenie, przekaże zapytanie do rekursywnego serwera DNS, często udostępnianego przez dostawcę usług internetowych (ISP). Tak naprawdę, kiedy twój system zapyta najbliższy z serwerów nazw o to, gdzie jest host1.b.example.com, taki serwer przekaże żądanie do dowolnego miejsca, w którym może uzyskać odpowiedź. Jeśli jeden z serwerów posiada rekordy w pamięci podręcznej, natychmiast odpowie klientowi, nie przeszkadzając wszystkim pozostałym serwerom pośredniczącym, zaczynając od serwerów głównych.
Rekursywny serwer DNS, ma własną pamięć podręczną i jeśli zna adres IP szukanej domeny, zwróci go do Ciebie. Jeśli nie, poprosi inny serwer DNS o pomoc w znalezieniu serwera głównego dla domeny, z którą chcesz nawiązać połączenie i której adresu IP szukasz. Ponieważ pamięć podręczna serwera DNS zawiera tymczasowy magazyn rekordów DNS, będzie on bardzo szybko odpowiadał na żądania, co jest jedną z kluczowych funkcji tego typu serwerów DNS. Tego typu serwery są nazywane nieautorytatywnymi serwerami DNS, ponieważ zapewniają rozwiązywanie żądań na podstawie wartości buforowanej uzyskanej z autorytatywnych serwerów DNS.
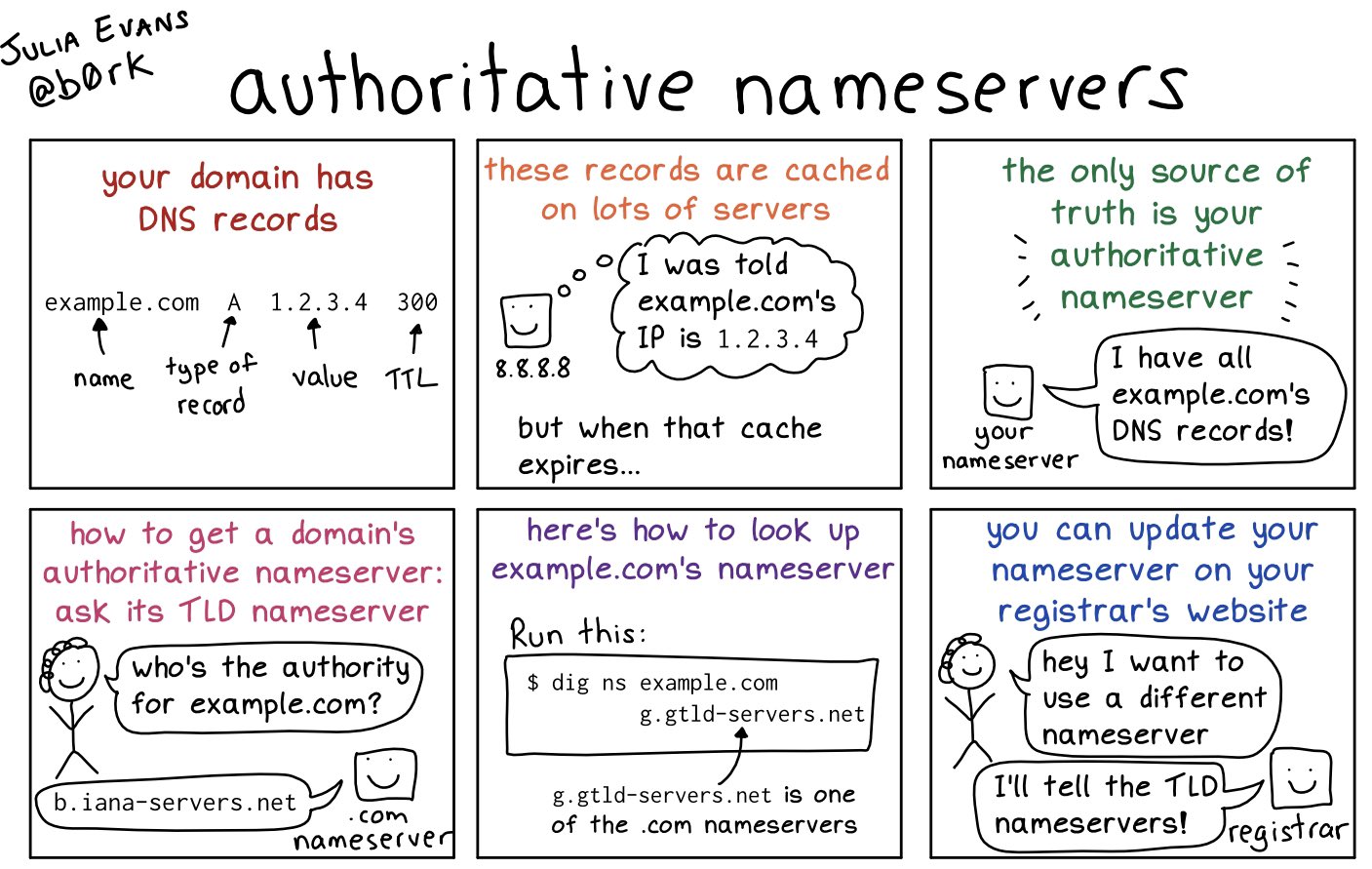
Wspomniałem o typach serwerów jednak bardzo często możesz się spotkać z terminem resolwer (ang. resolver). Co to takiego jest? Termin ten oznacza ogólny podsystem zajmujący się rozwiązywaniem zapytań. Tak naprawdę jest to cały podsystem, którego programy użytkownika używają do uzyskiwania dostępu do serwerów nazw, bez względu na jakąkolwiek konkretną architekturę. Najczęściej, jest on dość prostą biblioteką klienta działająca w procesach aplikacji, komunikującą się za pomocą protokoów UDP i TCP z uruchomionym programem zewnętrznym jako kolejnym procesem, który faktycznie wykonuje podstawową pracę związaną z rozwiązywaniem zapytań.
Jeśli odpytywany serwer DNS zna odpowiedź, ponieważ ostatnio zadano mu to samo pytanie, zwróci ją z pamięci podręcznej (o ile taki wpis nie wygasł). Jeśli odpytywany serwer DNS nie jest w stanie rozwiązać domeny, uruchomi dalszą procedurę odpytywania, np. gdy rekursywny serwer DNS usługodawcy internetowego nie może rozpoznać nazwy domeny, kontaktuje się (dlatego nazywamy je serwerami rekurencyjnymi) z innymi serwerami DNS, aby dostarczyć Ci wymaganych informacji. Każdy dostawca usług internetowych ma zazwyczaj dwa serwery DNS, w tym jeden pomocniczy, aby zapewnić maksymalną dostępność usługi.
Zapytania DNS klienta są wysyłane rekurencyjnie, co oznacza, że klient powinien otrzymać od dostawcy DNS błąd lub rozwiązany rekord. Serwery pośredniczące także nie powinny samodzielnie rozwiązywać łańcucha pośrednich serwerów DNS, ponieważ ich zadaniem jest przekazywanie zapytań dalej do serwera DNS, który obsługuje żądania klientów. W ten sposób usługi przekazywania zmniejszają obciążenie pośrednich serwerów DNS i odpowiadają klientom tak szybko, jak to możliwe, ponieważ serwery DNS dostawców są bliżej klientów.
W tym celu musi ustalić, który serwer DNS jest tzw. serwerem autorytatywnym, czyli takim serwerem, który na pewno potrafi rozwiązać szukaną przez nas nazwę (jest jej właścicielem).
Autorytatywny serwer nazw to miejsce, w którym administratorzy zarządzają nazwami serwerów i adresami IP swoich domen. Ilekroć administrator DNS chce dodać, zmienić lub usunąć nazwę serwera lub adres IP, dokonuje zmiany na swoim autorytatywnym serwerze DNS. Istnieją również „podrzędne” serwery DNS, czyli takie, które przechowują kopie rekordów DNS swoich stref i domen.
Na tym etapie nie znamy jeszcze lokalizacji serwera autorytatywnego, dlatego musimy znaleźć takie serwery, które pomogą nam wskazać, gdzie on się znajduje. Tym sposobem docieramy do kolejnego poziomu, na którym znajdują się serwery główne (ang. root). Twój serwer zawiera listę wszystkich serwerów głównych i przechowuje ją najczęściej w miejscu zwanym Root Hints lub Root Zone — jest to po prostu lista (zbiór rekordów NS, A i AAAA) zawierająca ich adresy IPv4 i IPv6 serwerów, które są autorytatywne dla domeny głównej . (należy je traktować jako wskazówki dotyczące lokalizacji serwerów głównych). Lista takich serwerów jest publikowana przez IANA i można ją znaleźć tutaj.
Operatorzy serwerów DNS powinni regularnie aktualizować swoje pliki dotyczące serwerów głównych, aby wskazywały właściwe serwery nazw. Najczęściej takie listy dostarczane są wraz z paczkami serwera DNS dlatego nie musimy martwić się o ich aktualność.
Ponieważ wskazówki dotyczące roota są zadawane w twoim imieniu, serwery DNS otrzymają odpowiedź z odpowiednim rekordem od głównego serwera DNS, a następnie przekażą ci ten rekord.
Jak już wiemy, jeżeli rekursywny serwer DNS nie znajdzie odpowiedniego wpisu w swojej pamięci podręcznej, poprosi o pomoc serwery z tzw. autorytatywnej hierarchii (ang. authoritative DNS hierarchy), aby uzyskać odpowiedź. Dzieje się tak, ponieważ każda część domeny, taka jak host1.b.example.com, ma określony autorytatywny serwer nazw DNS (lub grupę nadmiarowych autorytatywnych serwerów nazw). Co istotne, ponieważ serwer DNS nie ma odpowiedniej strefy ani rekordu, najpierw przyjrzy się wewnętrznym mechanizmom przekazywani (czyli kolejnym serwerom, z którym może uzyskać odpowiedź). Jeśli nie ma skonfigurowanego odpowiedniego rekordu odpowiedzialnego za przekazywanie zapytań dla odpowiedniej strefy lub domeny, zacznie szukać odpowiedzi właśnie w tzw. wskazówkach dotyczących serwerów głównych.
W górnej części drzewa serwerów znajdują się główne serwery nazw domen. Każdy adres witryny internetowej ma domniemane . na końcu, nawet jeśli tego nie wpiszemy. To . wyznacza główne serwery nazw DNS na szczycie hierarchii DNS. Główne serwery nazw domen będą znać adresy IP autorytatywnych serwerów nazw, które obsługują zapytania DNS dla domen najwyższego poziomu TLS (ang. Top Level Domains), takich jak .com czy .gov.
Te serwery nie mają adresu IP, którego potrzebujemy, ale mogą wysłać żądanie DNS we właściwym kierunku. Widzimy, że pierwszym wysłanym zapytaniem będzie to, które dotyczy domeny głównego rzędu, tj. . (root), aby znaleźć odpowiedni serwer dla domeny niższego rzędu, tj. .com. Gdy uda się ustalić taki serwer, serwer DNS, który odpytywaliśmy, skomunikuje się z tym serwerem z zapytaniem o serwer nazw. Rekurencyjny serwer DNS najpierw pyta główny serwer nazw domen o adres IP serwera TLD .com, ponieważ host1.b.example.com znajduje się właśnie w TLD .com.
To, co mają serwery nazw TLD, to lokalizacja autorytatywnego serwera nazw dla żądanej witryny. Autorytatywny serwer nazw odpowiada adresem IP dla example.com, a rekursywny serwer DNS przechowuje go w lokalnej pamięci podręcznej DNS i zwraca adres do komputera.
Główny serwer nazw domeny odpowiada adresem serwera TLD. Następnie rekursywny serwer DNS pyta autorytatywny serwer TLD, gdzie może znaleźć autorytatywny serwer DNS dla host1.b.example.com. Autorytatywny serwer TLD odpowiada i proces jest kontynuowany. Autorytatywny serwer host1.b.example.com jest pytany, gdzie znaleźć host1.b.example.com, a serwer odpowiada z odpowiedzią. Gdy rekursywny serwer DNS zna adres IP witryny sieci Web, odpowiada komputerowi, podając odpowiedni adres IP. Twoja przeglądarka ładuje stronę i możesz rozpocząć jej przeglądanie.
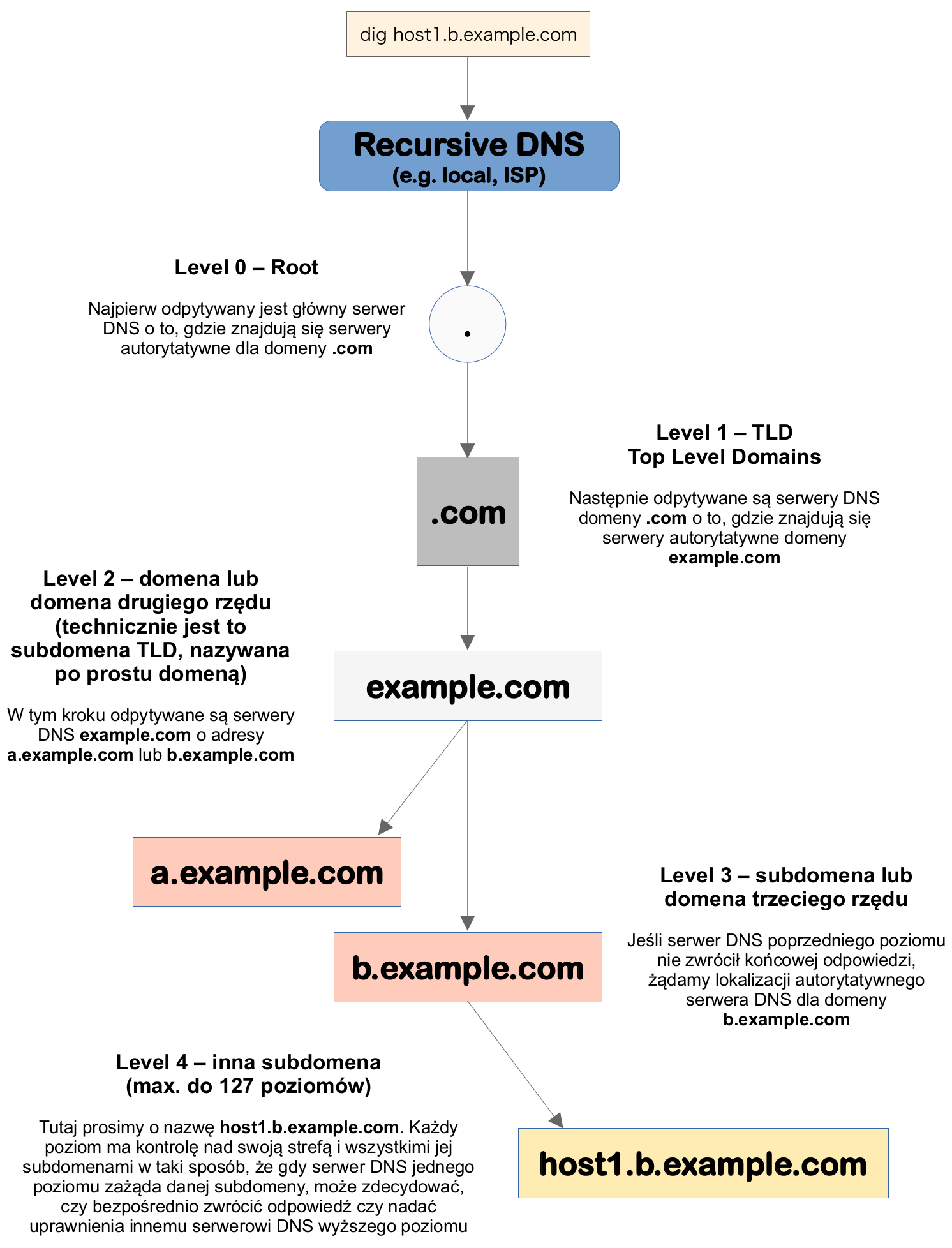
Podsumowując, gdy klient DNS wysyła takie żądanie, pierwszy odpowiadający serwer nie podaje potrzebnego adresu IP. Zamiast tego kieruje żądanie do innego serwera, który znajduje się niżej w hierarchii DNS, a ten do innego, dopóki adres IP nie zostanie w pełni rozwiązany. W procesie tym mamy trzy kluczowe elementy:
-
serwery główne (ang. Root DNS Servers) - ten typ serwerów nie mapuje adresów IP na nazwy domen. Zamiast tego przechowuje informacje o wszystkich serwerach nazw domen najwyższego poziomu (TLD) i zajmują się one jedynie wskazywaniem ich lokalizacji. TLD to skrajna prawa sekcja nazwy domeny, na przykład .com w przypadku example.com lub .org w przypadku example.org. Serwery główne są krytyczne, ponieważ są pierwszym przystankiem dla wszystkich żądań wyszukiwania DNS
-
serwery nazw TLD (ang. Top Level Domain DNS Servers) - ten typ serwerów zawiera dane z domen drugiego poziomu, takich jak example dla example.com. Wcześniej serwer główny wskazywał lokalizację serwera TLD, a następnie taki serwer kieruje żądanie do serwera zawierającego niezbędne dane dotycząca domeny
-
autorytatywny serwer nazw (ang. Authoritative DNS Server) - ten typ serwera DNS jest ostatecznym miejscem docelowym dla żądań wyszukiwania DNS. Dostarcza on adres IP domeny z powrotem do rekurencyjnych serwerów DNS, a następnie do klienta (przy okazji rekord dla tego żądania jest teraz przechowywany w pamięci podręcznej serwera rekursywnego oraz klienta tj. przeglądarki internetowej). Jeśli witryna ma subdomeny, lokalny serwer DNS będzie wysyłać żądania do autorytatywnego serwera, aż ostatecznie ustali adres IP
DNS Sinkhole #
Przypomnieliśmy sobie pokrótce, czym jest i jak działa system rozwiązywania nazw. Wiemy już, że jest to globalnie rozproszona, skalowalna, hierarchiczna i dynamiczna baza danych, która zapewnia m.in. mapowanie między nazwami hostów, adresami IP (zarówno IPv4, jak i IPv6) i jeszcze kilkoma innymi rekordami.
Z racji tego, że usługa ta jest podstawową i wręcz krytyczną usługą używaną do uzyskiwania dostępu do Internetu, istotne jest jej kontrolowanie. Tutaj do akcji wkracza mechanizm DNS Sinkholing mający na celu ochronę użytkowników poprzez przechwytywanie żądań DNS próbujących połączyć się ze znanymi złośliwymi lub niechcianymi domenami poprzez zwracanie fałszywego i kontrolowanego adresu IP. Technika ta została dokładnie opisana w świetnej pracy pod tytułem DNS Sinkhole [PDF], której autorem jest Guy Bruneau.
Na przykład przechwytując wychodzące żądania DNS próbujące uzyskać dostęp do znanych złośliwych domen lub choćby w pełni legalnych witryn zawierających jednak złośliwe reklamy, organizacja może kontrolować odpowiedź i uniemożliwić komputerom organizacji łączenie się z tymi domenami. Pozwala to zapobiec niechcianej komunikacji i jest w stanie złagodzić znane i nieznane zagrożenia w znanych złośliwych lub niechcianych domenach. Dzięki funkcji sinkholingu możemy blokować zapytania DNS do określonych domen, odbierać zapytania DNS na wyjściu sieci i podejmować działania, zamiast przekazywać je do wewnętrznych lub publicznych serwerów DNS.
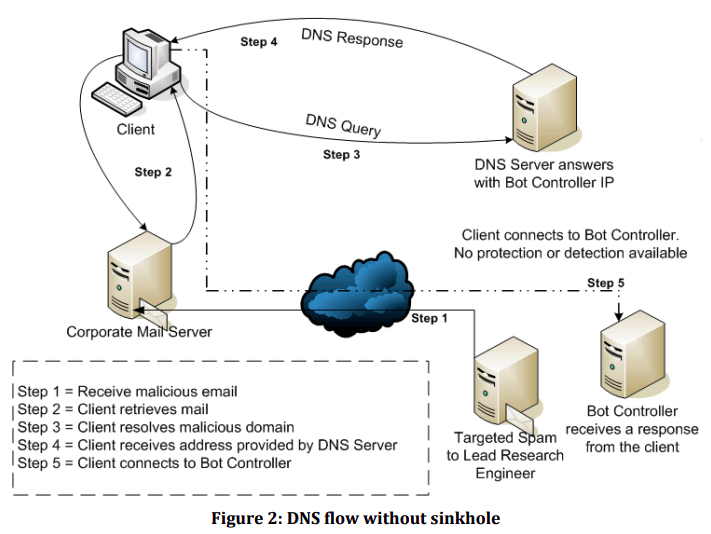
Widzisz, że tak skonfigurowany serwer przechwytuje żądania DNS klienta do znanych złośliwych witryn, odpowiadając za pomocą adresu IP, który kontrolujesz, zamiast prawdziwego ich adresu, dzięki czemu klient kierowany jest w bezpieczne miejsce. Kontrolowany adres IP wskazuje najczęściej na serwer zdefiniowany i będący pod kontrolą administratora.
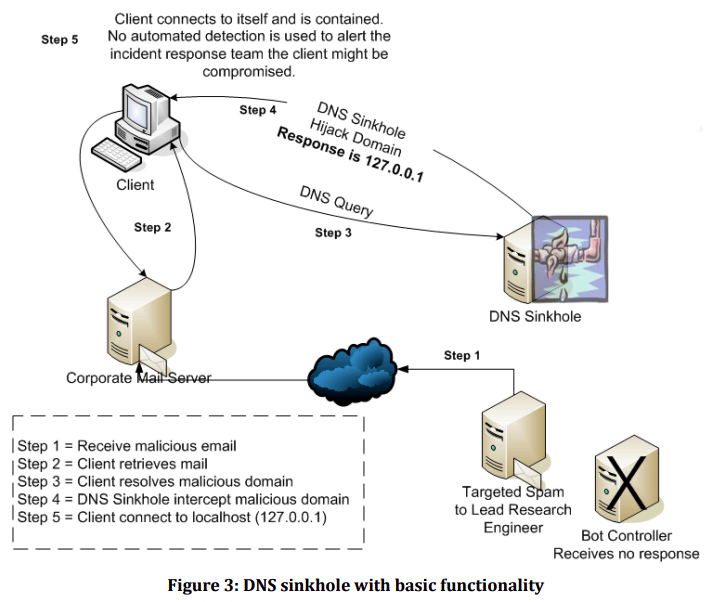
Jest to niezwykle potężna technika, która pozwala np. na ograniczenie ataków botów, poprzez blokowanie komunikacji między serwerem atakującego a nimi. Sinkholing można jednak wykonać na różnych poziomach. Wiadomo, że zarówno dostawcy usług internetowych, jak i rejestratorzy domen używają tej techniki do ochrony swoich klientów, kierując żądania do złośliwych lub niechcianych nazw domen na kontrolowane adresy IP. Administratorzy systemów mogą również skonfigurować wewnętrzny serwer DNS typu sinkhole w infrastrukturze swojej organizacji. Użytkownik może również zmodyfikować plik /etc/hosts w swoim systemie (co spowoduje nadpisanie wszystkiego lokalnie) i uzyskać ten sam wynik. Istnieje wiele list (zarówno otwartych, jak i komercyjnych) znanych złośliwych domen, których administrator może wykorzystać.
Taka metoda blokowania nie tylko zwiększa bezpieczeństwo stacji klienckich (zatrzymując potencjalne złośliwe reklamy), ale także pozwala klientom na ich blokowanie bez żadnych wtyczek czy dodatkowej konfiguracji. Kolejną zaletą blokowania na tym poziomie (DNS) jest to, że cała sieć może skorzystać z filtrowania bez konieczności konfigurowania jakiegokolwiek rodzaju filtrowania proxy na każdym kliencie.
Oprócz zapobiegania złośliwym połączeniom sinkholing może służyć do identyfikowania zainfekowanych hostów poprzez analizę dzienników i identyfikowanie klientów, którzy próbują połączyć się ze znanymi złośliwymi domenami. Na przykład, jeśli dzienniki pokazują, że jedna konkretna maszyna nieustannie próbuje połączyć się z tzw. serwerem C&C (ang. Command and Control) — czyli takim serwerem, który jest kontrolowany przez atakującego, który służy do wysyłania poleceń do systemów zainfekowanych złośliwym oprogramowaniem i odbierania skradzionych danych z sieci docelowej — ale żądanie jest przekierowywane z powodu sinkholingu, istnieje duża szansa, że ta konkretna maszyna jest zainfekowana botem.
Jeśli zainfekowany system wysyła zapytanie DNS do naszego serwera rozwiązywania nazw w celu komunikacji z serwerem atakującego, nasz serwer DNS, który zawiera czarną listę domen niepożądanych miejsc docelowych, zwraca kontrolowany przez nas adres IP. W rezultacie, ponieważ komputer zombie próbuje komunikować się z naszym serwerem, nie może komunikować się serwerem atakującego. Z drugiej strony istnieje wiele cyberataków powodowanych przez złośliwe adresy URL zawarte w wiadomościach spam. Dlatego też, jeśli wyodrębnimy złośliwe adresy URL z tego typu wiadomości i zastosujemy je do techniki sinkholingu, wiele ataków opartych na spamie może zostać zablokowanych.
Istnieje kilka prostych sposobów, dzięki którym klienci mogą złagodzić opisane problemy, np. modyfikując plik /etc/hosts w swoich systemach, aby wskazywał na poprawne adresy IP dla domen, lub używając publicznej usługi rozpoznawania nazw. Ważną sugestią jest to, że powinniśmy to robić tylko na swoich wewnętrznych resolverach, ponieważ jeśli technika sinkholingu zostanie wdrożona na publicznych, autorytatywnych serwerach, administrator będzie odpowiadać na domeny, za które nie jest odpowiedzialny.
W przypadku serwera BIND konfiguracja jest niezwykle prosta i sprowadza się do określenia, które domeny będą blokowane. W pierwszej kolejności należy dodać odwołanie do specjalnie przygotowanego pliku w głównym pliku konfiguracyjnym:
// named.conf
//
// Do any local configuration here
//
// Consider adding the 1918 zones here, if they are not used in your
// organization
//include "/etc/namedb/zones.rfc1918";
include "/etc/namedb/blacklisted.zones";
Natomiast plik /etc/namedb/blacklisted.zones może przyjąć poniższą zawartość:
zone "9nta.com" {type master; file "/etc/namedb/sinkhole/blockeddomains.db";};
zone "malware.ru" {type master; file "/etc/namedb/sinkhole/blockeddomains.db";};
zone "adworks.cat" {type master; file "/etc/namedb/sinkhole/blockeddomains.db";};
zone "herngell-our.web.app" {type master; file "/etc/namedb/sinkhole/blockeddomains.db";};
zone "google.co.uk" {type master; file "/etc/namedb/sinkhole/blockeddomains.db";};
Jak widać powyżej, definiujemy strefy, dla których nasz serwer DNS będzie autorytatywny. Gdy otrzyma zapytanie od klienta dotyczące, np. 9nta.com, serwer dostarczy dane z powiązanego pliku. W tym przypadku, ponieważ traktujemy je wszystkie jako domeny typu sink, wszystkie mogą wskazywać ten sam plik strefy, aby ułatwić zarządzanie.
Plik blockeddomains.db dla specjalnie przygotowanej strefy może mieć poniższą zawartość:
$ORIGIN .
$TTL 600 ; 1 hour
@ IN SOA ns01.example.com. hostmaster.example.com. (
2020100301 ; serial
3600 ; refresh (1 hour)
900 ; retry (15 minutes)
1814400 ; expire (3 weeks)
3600 ; minimum (1 hour)
)
NS ns01.example.com.
NS ns02.example.com.
; Każde odwołanie do 9nta.com spowoduje przekierowanie na wskazany adres
A 172.31.252.10
; Każde odwołanie do *.9nta.com spowoduje przekierowanie na wskazany adres
* IN A 172.31.252.10
; * IN A 127.0.0.1
; * IN AAAA ::1
W tym przypadku chodzi o wskazanie określonego adresu IP, na którym połączenia z nim będą monitorowane w celu generowania informacji o zapytaniach do niepożądanych domen. Jeśli zależy nam na zablokowaniu połączeń z takimi domenami, docelową lokalizację należy zmienić na adres pętli zwrotnej.
Po tych zmianach wewnętrzny resolver będzie od teraz autorytatywny dla wszystkich domen, które były wymienione na czarnej liście. Jeżeli chcesz poznać inny przykład podejścia, zerknij do poniższych artykułów:
Na koniec koniecznie zapoznaj się z dokumentem Consequences of DNSbased Internet filtering [PDF], który przedstawia możliwe konsekwencje takiego blokowania domen z poziomu serwera BIND, a także świetnej prezentacji DNS Response Policy Zones na temat mechanizmu, który umożliwia administratorowi serwera nazw nakładanie niestandardowych informacji na globalny DNS w celu dostarczania alternatywnych odpowiedzi na zapytania klientów.