Redis: 3 instancje i replikacja Master-Slave cz. 3
29 Sep 2020
database debugging haproxy nosql performance redis redis-cluster redis-sentinel replication
Oto trzecia i ostatnia część rozważań na temat Redisa i Redis Sentinela, w której omówię dodatkowe narzędzia pomocne podczas budowania pełno prawnego rozwiązania HA opartego na replikacji Master-Slave.
HAProxy #
Mając poprawnie zestawioną replikację, nie pozostaje nam nic innego jak przekazać architektom i developerom namiary na serwer nadrzędny, do którego będą się łączyć. Tym samym nasza praca dobiegła końca.
Nic z tych rzeczy. Pomyśl, co się stanie jeśli Master ulegnie awarii i będziemy musieli awansować jedną z replik do nowej roli? Z naszej strony będzie to 5 minut pracy, jednak taką samą pracę (jak nie większą) będą musieli wykonać architekci, którzy zmuszeni będą zaktualizować konfigurację aplikacji, tak aby wskazywała na adres IP nowego mistrza. Wyobraź sobie, że taka sytuacja powtarza się kilkukrotnie, co spowoduje tylko niepotrzebną irytacją. Tutaj z pomocą przychodzi omawiane wcześniej HAProxy.
W jednym z początkowych rozdziałów stwierdziłem, że wykorzystanie HAProxy w tym zestawie wprowadza pewną inteligencję, dzięki której serwer nadrzędny jest automatycznie wykrywany na każdym węźle, więc jeśli działa, aplikacja zawsze pisze do niego. Dzięki temu aplikacja nie komunikuje się bezpośrednio z Redisem tylko z odpowiednim lokalnym gniazdem, na którym nasłuchuje HAProxy. Dla aplikacji całe rozwiązanie jest całkowicie transparentne i nie wymaga ciągłych zmian po stronie kodu. Oczywiście możliwości jest więcej a inną alternatywą opartą na HAproxy jest skonfigurowanie go tak, aby odseparował zapisy i odczyty i kierował je do różnych backendów.
W pierwszej kolejności zainstalujemy HAProxy z repozytorium SCL oraz włączymy usługę, aby uruchamiała się podczas startu systemu:
yum install rh-haproxy18
systemctl enable rh-haproxy18-haproxy
HAProxy dostępne w głównym repozytorium CentOS nie działa poprawnie i sprawia problemy z Redisem w wersji 5 i wyższymi, dlatego instalację przeprowadziłem z wersją RH. Konfiguracja HAProxy do współpracy z Redisem jest niezwykle prosta i najczęściej wygląda tak:
global
pidfile /var/run/haproxy.pid
log 127.0.0.1 local0 info
user haproxy
group haproxy
maxconn 512
nbproc 2
nbthread 2
defaults redis
mode tcp
timeout connect 4s
timeout server 10s
timeout client 10s
log global
option tcplog
frontend http
bind *:8080
default_backend stats
backend stats
mode http
stats enable
stats uri /
stats refresh 5s
stats show-legends
stats auth ha-admin:piph1NeiceHe
frontend ft_redis
bind :16379 name redis
default_backend bk_redis
backend bk_redis
log global
option tcp-check
tcp-check send AUTH\ meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2\r\n
tcp-check expect string +OK
tcp-check send PING\r\n
tcp-check expect string +PONG
tcp-check send info\ replication\r\n
tcp-check expect string role:master
tcp-check send QUIT\r\n
tcp-check expect string +OK
server R1 192.168.10.10:6379 check inter 1s
server R2 192.168.10.20:6379 check inter 1s
server R3 192.168.10.30:6379 check inter 1s
W zależności od wybranego źródła instalacji w systemie CentOS dodajemy ją do pliku /etc/haproxy/haproxy.cfg lub /etc/opt/rh/rh-haproxy18/haproxy/haproxy.cfg (w naszym przypadku) na każdym serwerze, na którym działają wszystkie usługi.
Taka konfiguracja jest dobra, ale pod warunkiem, że w naszym środowisku nie wykorzystujemy Redis Sentinela a przełączanie awaryjne wykonywane jest przez administratora — co jak się domyślasz, może być katorżniczym wyzwaniem. Jeżeli wykorzystujemy Sentinele to taka konfiguracja jest bardzo mocno niezalecana a wręcz niepoprawna w przypadku kiedy zależy nam, aby nie doszło do uszkodzenia ani utraty danych.
Dlaczego? Wyobraź sobie następującą sytuację. Jeżeli podczas pracy wystąpią pewne problemy z siecią, może dojść do sytuacji, że jedna z replik zostanie awansowana do roli nadrzędnej, podczas gdy stary Master nie będzie dostępny (zostanie odizolowany od reszty). Jeśli stary mistrz wróci to trybu online, nadal będzie miał rolę Master, a HAProxy uzna obie instancje jako prawidłowy backend, więc będzie wysyłać zapytania do obu nawet przez kilka sekund, do momentu, aż Sentinele nie rozwiążą tej sytuacji, degradując starego mistrza do roli instancji podrzędnej.
Główną ideą działania HAProxy jest to, że stara się on wykryć serwery główne poprzez wysyłanie zapytań do każdego ustawionego backendu. Jeżeli dojdzie do sytuacji podobnej jak wyżej, HAProxy będzie widziało dwa węzły główne, co spowoduje pisanie raz do jednego i raz do drugiego. W przypadku środowisk, gdzie tolerancja na utratę danych jest wysoka, nie będzie to problemem, jednak tam, gdzie dane są niezwykle krytyczne, dojdzie do ich nieodwracalnej utraty. Jeżeli wymagania biznesowe nie stawiają przed aplikacją przymusu odpowiedniego dbania o przechowywane dane w Redisie, konfiguracja HAProxy zaprezentowana wyżej sprawdzi się doskonale.
Natomiast jeśli wymagania są inne, należy mieć świadomość potencjalnych problemów, a także komplikacji w przypadku wykorzystania Redisa i Sentineli w połączeniu z HAProxy. Rozwiązaniem tych problemów jest dostosowanie HAProxy tak, aby pobierał informacje o aktualnym mistrzu wprost z działających Sentineli, które powinny być autorytetami w dostarczaniu wszelkich danych o działających instancjach i to niezależnie od ich roli. Czyli cały mechanizm przełączania instancji głównej z poziomu HAProxy będzie polegał na monitorowaniu i odpytywaniu wartowników. Moim zdaniem, powinniśmy zawsze odpytywać Sentinele, aby zminimalizować niepotrzebną utratę danych zapisywanych do Redisa (nawet, jeśli nie zapisujemy ich na dysk) oraz wykluczyć problemy w przypadku działaniu dwóch instancji głównych.
Długo szukałem za rozwiązaniem tego problemu i odpowiednim dostrojeniu konfiguracji HAProxy. Przykład zmodyfikowanej konfiguracji znajduje się poniżej:
global
pidfile /var/run/haproxy.pid
log 127.0.0.1 local0 info
user haproxy
group haproxy
maxconn 512
nbproc 2
nbthread 2
defaults redis
mode tcp
timeout connect 4s
timeout server 10s
timeout client 10s
log global
option tcplog
frontend http
bind *:8080
default_backend stats
backend stats
mode http
stats enable
stats uri /
stats refresh 5s
stats show-legends
stats auth ha-admin:piph1NeiceHe
backend check_sentinel_R1
mode tcp
option tcp-check
tcp-check connect
tcp-check send AUTH\ meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2\r\n
tcp-check expect string +OK
tcp-check send PING\r\n
tcp-check expect string +PONG
tcp-check send SENTINEL\ master\ mymaster\r\n
tcp-check expect string 192.168.10.10
tcp-check send QUIT\r\n
tcp-check expect string +OK
server S1 192.168.10.10:26379 check inter 2s
server S2 192.168.10.20:26379 check inter 2s
server S3 192.168.10.30:26379 check inter 2s
backend check_sentinel_R2
mode tcp
option tcp-check
tcp-check connect
tcp-check send AUTH\ meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2\r\n
tcp-check expect string +OK
tcp-check send PING\r\n
tcp-check expect string +PONG
tcp-check send SENTINEL\ master\ mymaster\r\n
tcp-check expect string 192.168.10.20
tcp-check send QUIT\r\n
tcp-check expect string +OK
server S1 192.168.10.10:26379 check inter 2s
server S2 192.168.10.20:26379 check inter 2s
server S3 192.168.10.30:26379 check inter 2s
backend check_sentinel_R3
mode tcp
option tcp-check
tcp-check connect
tcp-check send AUTH\ meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2\r\n
tcp-check expect string +OK
tcp-check send PING\r\n
tcp-check expect string +PONG
tcp-check send SENTINEL\ master\ mymaster\r\n
tcp-check expect string 192.168.10.30
tcp-check send QUIT\r\n
tcp-check expect string +OK
server S1 192.168.10.10:26379 check inter 2s
server S2 192.168.10.20:26379 check inter 2s
server S3 192.168.10.30:26379 check inter 2s
frontend ft_redis
bind *:16379
mode tcp
acl network_allowed src 127.0.0.1 192.168.10.0/24
tcp-request connection reject if !network_allowed
timeout connect 4s
timeout server 15s
timeout client 15s
use_backend bk_redis
backend bk_redis
mode tcp
tcp-check send PING\r\n
tcp-check expect string +PONG
use-server R1-SERVER if { srv_is_up(R1-SERVER) } { nbsrv(check_sentinel_R1) ge 2 }
use-server R2-SERVER if { srv_is_up(R2-SERVER) } { nbsrv(check_sentinel_R2) ge 2 }
use-server R3-SERVER if { srv_is_up(R3-SERVER) } { nbsrv(check_sentinel_R3) ge 2 }
server R1-SERVER 192.168.10.10:6379 check inter 2s
server R2-SERVER 192.168.10.20:6379 check inter 2s
server R3-SERVER 192.168.10.30:6379 check inter 2s
Powyższa konfiguracja i taki sposób działania HAProxy powoduje, że:
- jeśli Sentinele nie będą w stanie wykryć instancji głównej, nie dojdzie do zapisów, splitów oraz utraty danych
- jeśli nie zapewnimy większości, Sentinel nie wypromuje działającej repliki na mistrza, nie dojdzie do zapisów, splitów oraz utraty danych
- jeśli Sentinele wykryją instancję główną a w tym czasie inna replika stanie się mistrzem, ruch kierowany będzie nadal do poprawnego węzła
Przekazanie komendy AUTH w drugim przykładzie jest wymagane wtedy, kiedy w konfiguracji Redis Sentinela ustawiony został parametr requirepass. Nie uruchamiajmy jeszcze HAProxy i poczekajmy do wyjaśnienia jeszcze kilku dodatkowych i istotnych kwestii.
Oczywiście warunkiem działania i jednocześnie pewnym minusem takiej konfiguracji jest ciągły wymóg dostępności przynajmniej jednego z Sentineli i instancji głównej, dlatego jedną z gwarancji ich działania powinno być kompletne odseparowania procesów Redis i Redis Sentinel od siebie (uruchomienie ich na całkowicie odrębnych serwerach). Problem może pojawić się także w sytuacji, w której z pewnych względów Sentinele nie będą mogły dostarczyć informacji o aktualnym mistrzu.
Innym problemem może być sytuacja, w której aktualny Master jest zamykany, a jedna z replik jest promowana w jego miejsce i musi załadować duży zestaw danych do pamięci lub kiedy nie odebrała od niego wszystkich danych. Może to spowodować awarię klientów jeśli nie są poprawnie napisani (widzisz, że także klienci powinni wykrywać i obsługiwać awarie instancji głównej). Nie jest to błahy problem, ponieważ w obu powyższych konfiguracjach HAProxy nie jest świadome ilości przetworzonego strumienia replikacji, więc na tej podstawie nie jest w stanie stwierdzić, który backend jest odpowiedni. Nie wiem, czy jest w ogóle sens zaimplementowania takiego sprawdzania a jedyną zaletą, jaką widzę, jest ochrona przed niepotrzebnymi zapisami do nowego mistrza, który jeszcze nie odebrał wszystkich danych lub, co chyba najważniejsze, nie załadował wszystkich danych z plików podczas powrotu z awarii. Inna sprawa jest taka, że przesunięcia replikacji są czymś normalnym dlatego ich weryfikacja z poziomu HAProxy może powodować niepotrzebne rozłączanie. Po drugie, pamiętajmy, że jeśli przesunięcie jest zbyt duże, Sentiele posiadają mechanizmy chroniące przed wypromowaniem takiej repliki do roli nadrzędnej. Widzisz, że podczas projektowania i wdrożenia jednego z rozwiązań musisz rozważyć wszystkie za i przeciw.
Druga konfiguracja rozwiązuje jednak w 100% problem zapisywania do dwóch mistrzów naraz. Mimo tego, że nadal istnieje krótki przedział czasowy, w którym podczas przełączania awaryjnego mogą działać dwie instancje główne, to dzięki zastosowaniu takiej konfiguracji jesteśmy w stanie zawsze pisać do aktualnego Mastera widzianego z poziomu Sentineli i zmniejszyć czas ew. niedostępności i niedziałania replikacji do minimum.
Twemproxy #
W poprzednim rozdziale przestawiłem rozwiązanie, które pomaga klientom komunikować się z Redisem tak, aby widziały i miały dostęp zawsze do aktualnej instancji nadrzędnej. W tym rozdziale natomiast omówię rozwiązania, które poprawiają wydajność, np. głównie w celu zmniejszenia liczby połączeń z instancjami Redis.
Istnieją cztery niezwykle ciekawe technologie:
Każdy z wyżej wymienionych projektów jest bardzo ciekawy i prezentuje inne możliwości. Codis jest rozwiązaniem typowo przeznaczonym do pracy z klastrem i składa się z kilku części dlatego jego wdrożenie może zając trochę czasu. Jednak jest to bardzo stabilne narzędzie, które dodatkowo zapewnia przyjemne GUI. Natomiast sporą wadą Dynomite jest brak obsługi polecenia AUTH, więc jeżeli zechcesz go uruchomić, musisz zapewnić odpowiednie mechanizmy bezpieczeństwa. Mcrouter natomiast został przystosowany głównie do działania z memcached więc nadaje się idealnie jeśli wykorzystujesz to rozwiązanie.
Jeżeli napotkałeś problemy z wydajnością i szukałeś rozwiązania tego problemu, na pewno natknąłeś się na narzędzie Twemproxy, które jest kolejnym rozwiązaniem podobnym do tutaj opisywanych. Twemproxy to niezwykle lekki i bardzo szybki serwer proxy, który przekazuje żądania do puli instancji Memcached lub Redis. Został on opracowany głównie w celu zmniejszenia liczby otwartych połączeń (można je zredukować nawet o 80%) z oboma typami serwerów pamięci podręcznej, dzięki multipleksowaniu i potokowaniu żądań przez pojedyncze połączenie z każdą instancją. Dzięki temu pozwala on na ponowne wykorzystanie połączeń sieciowych, znacznie zmniejszając obciążenie połączenia z demonami Redis.
Jego zastosowanie służy głównie poprawie wydajności poprzez utrzymywanie trwałych połączeń. Ma on jednak wiele innych istotnych funkcji, tj. gromadzenie żądań (ang. Command Pipelining) przeznaczonych dla tego samego hosta i wysyłanie ich jako jedną porcję danych, zapewnienie kilku algorytmów mieszania używanych do określania, gdzie umieścić określony klucz w wielowęzłowym systemie buforowania, automatyczne odłączanie niedziałających węzłów czy automatyczne dzielenie danych między wieloma serwerami pamięci podręcznej. Na temat pozostałych funkcji i zalet możesz poczytać w oficjalnym repozytorium.
Niestety projekt nie jest aktualizowany od dłuższego czasu (jako alternatywę możesz rozważyć Dynomite). Spotkałem się także z opiniami co do wątpliwej jakości samego kodu, co jeśli jest prawdą (nie byłem w stanie tego zweryfikować), moim zdaniem trochę dyskwalifikuje go do wykorzystania produkcyjnego. Jednak lista organizacji, które wykorzystują Twemproxy jest naprawdę bardzo długa. Oprócz paru minusów słyszałem także wiele pozytywnych opinii, w których praktycznie zawsze pojawiała się największa zaleta stosowania Twemproxy, którą zresztą mogę potwierdzić: to, że działa naprawdę bardzo stabilnie.
Jedną z wad Twemproxy jest konieczność ponownego uruchomienia procesu w przypadku zmiany konfiguracji. Może wydawać się to nieistotnym i nadmiernym zarzutem, jednak czas ponownego uruchomienia w zakresie 1-2 sekund może być zbyt dużym zakłóceniem dla łączących się klientów.
W naszym przykładzie wykorzystamy ostatnie z rozwiązań, czyli Twemproxy. Przed przystąpieniem do dalszego czytania zalecam zapoznać się z opisem projektu oraz oficjalnymi rekomendacjami.
W pierwszej kolejności pobieramy źródła projektu:
git clone https://github.com/twitter/twemproxy.git
Następnie instalujemy dodatkowe paczki:
yum install dh-autoreconf
Teraz możemy przejść do zbudowania binarki:
cd twemproxy
autoreconf -fvi
./configure --enable-debug=full
make
Następnie tworzymy katalog dla przyszłych konfiguracji oraz pod dzienniki, w których będziemy odkładać komunikaty zwracane przez Twemproxy:
mkdir /etc/twemproxy /var/log/twemproxy
Na koniec kopiujemy nowo skompilowany program do /usr/local/sbin:
cp src/nutcracker /usr/local/sbin/nutcracker
I testowo go uruchamiamy w celu weryfikacji czy działa:
nutcracker --help
Możemy przyjąć kilka strategii uruchomienia Twemproxy. Jedną z nich przedstawia poniższy zrzut:

Taka konfiguracja pozwala na dwie rzeczy:
- buforowanie zapytań kierowanych do instancji Redis
- automatyczne wykrywanie mistrza i na tej podstawie kierowanie zapytań już nie bezpośrednio do instancji nadrzędnej, tylko do procesu Twemproxy, który będzie komunikował się z mistrzem
Oczywiście jedną z kluczowych rzeczy jest odpowiednio skonfigurowane HAProxy, które będzie odpowiedzialne za ciągłe wykrywanie mistrza. Pojawia się jednak jeszcze jedna istotna kwestia. Mianowicie ile serwerów Redis ustawić po stronie Twemproxy? Aby nie komplikować sytuacji, możemy ustawić gniazdo tylko do lokalnej instancji Redis na danym serwerze, na którym działa Twemproxy a wykrywaniem i rozrzucaniem serwera głównego nadal będzie zajmował się HAProxy.
Konfigurację zapiszemy do pliku /etc/twemproxy/nutcracker.yml na każdym z węzłów i będzie ona wyglądała tak (kopiujemy tylko część przeznaczoną dla danej instancji i dodajemy ją do pliku konfiguracyjnego):
### R1 - 192.168.10.10 ###
redis_stack:
listen: 192.168.10.10:36379
hash: fnv1a_64
hash_tag: "{}"
distribution: ketama
auto_eject_hosts: true
server_retry_timeout: 5000
server_failure_limit: 2
timeout: 5000
redis: true
redis_auth: meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
servers:
- 127.0.0.1:6379:1 R1
### R2 - 192.168.10.20 ###
redis_stack:
listen: 192.168.10.20:36379
hash: fnv1a_64
hash_tag: "{}"
distribution: ketama
auto_eject_hosts: true
server_retry_timeout: 5000
server_failure_limit: 2
timeout: 5000
redis: true
redis_auth: meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
servers:
- 127.0.0.1:6379:1 R2
### R3 - 192.168.10.30 ###
redis_stack:
listen: 192.168.10.30:36379
hash: fnv1a_64
hash_tag: "{}"
distribution: ketama
auto_eject_hosts: true
server_retry_timeout: 5000
server_failure_limit: 2
timeout: 5000
redis: true
redis_auth: meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2
servers:
- 127.0.0.1:6379:1 R3
W sekcji servers ustawiony został adres interfejsu pętli zwrotnej. Jeżeli zajdzie potrzeba komunikacji między instancjami Twemproxy należy ustawić adresy IP interfejsu zewnętrznego. Dokładny opis wszystkich dostępnych parametrów znajdziesz w repozytorium projektu.
Musimy jeszcze nadać mu odpowiednie uprawnienia i pamiętać o zrobieniu tego samego dla katalogu z logami:
chown -R redis:redis /etc/twemproxy
chown -R redis:redis /var/log/twemproxy
Teraz pozostaje jedynie przygotowanie serwisu pod systemd. Umieścimy go w pliku /usr/lib/systemd/system/twemproxy.service:
[Unit]
Description=Twemproxy (Nutcracker) Redis Proxy.
After=network.target
[Service]
ExecStart=/usr/local/sbin/nutcracker -v 5 -o /var/log/twemproxy/nutcracker.log -c /etc/twemproxy/nutcracker.yml
ExecStop=/bin/kill -SIGTERM $MAINPID
Restart=always
User=redis
Group=redis
[Install]
WantedBy=multi-user.target
Pozostało jeszcze przeładować konfigurację systemd oraz dodać nowy serwis do autostartu:
systemctl daemon-reload
systemctl enable twemproxy
Możemy teraz wystartować nową usługę:
systemctl start twemproxy
Mając poprawnie skonfigurowane usługi Redis i Redis Sentinel, możemy podpiąć się pod konsolę instancji nadrzędnej i utworzyć testowy klucz. Następnie podłączyć się przez Twemproxy i zweryfikować czy mamy połączenie:
# Tworzymy klucz na węźle głównym (R1):
redis.cli
127.0.0.1:6379> SET foo bar
OK
# Testujemy połączenie z wykorzystaniem Twemproxy:
./src/redis-cli --no-auth-warning -a meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2 -h 127.0.0.1 -p 36379 get foo
"bar"
W konfiguracji złożonej z trzech instancji Redis tj. 1x Master i 2x Slave oraz uruchomionej usłudze Redis Sentinel na każdym węźle, serwery podrzędne będą kopiami danych (tylko do odczytu) serwera nadrzędnego. Redis Sentinel będzie stale monitorował węzeł główny i jeśli ulegnie on awarii, jedna z replik zostanie awansowana do roli Master. Pozostałe instancje Slave zostaną ponownie skonfigurowane, aby były replikami nowego węzła głównego.
Mamy już dwie możliwe konfiguracje HAProxy, jednak musimy je dostosować do działania z Twemproxy. Wykorzystamy tą, która do zlokalizowania instancji głównej wykorzystuje Sentinele. Zmiana jest trywialna, ponieważ dotyczy sześciu ostatnich linijek:
# Przed zmianą:
use-server R1-SERVER if { srv_is_up(R1-SERVER) } { nbsrv(check_sentinel_R1) ge 2 }
use-server R2-SERVER if { srv_is_up(R2-SERVER) } { nbsrv(check_sentinel_R2) ge 2 }
use-server R3-SERVER if { srv_is_up(R3-SERVER) } { nbsrv(check_sentinel_R3) ge 2 }
server R1-SERVER 192.168.10.10:6379 check inter 2s
server R2-SERVER 192.168.10.20:6379 check inter 2s
server R3-SERVER 192.168.10.30:6379 check inter 2s
# Po zmianie:
use-server T1-SERVER if { srv_is_up(T1-SERVER) } { nbsrv(check_sentinel_R1) ge 2 }
use-server T2-SERVER if { srv_is_up(T2-SERVER) } { nbsrv(check_sentinel_R2) ge 2 }
use-server T3-SERVER if { srv_is_up(T3-SERVER) } { nbsrv(check_sentinel_R3) ge 2 }
server T1-SERVER 192.168.10.10:36379 check inter 2s
server T2-SERVER 192.168.10.20:36379 check inter 2s
server T3-SERVER 192.168.10.30:36379 check inter 2s
Po zmianie należy przeładować obie usługi:
# Wystartowanie HAProxy i przeładowanie konfiguracji Twemproxy
systemctl start rh-haproxy18-haproxy
systemctl restart twemproxy
Niestety nie uda się tego zrobić w przypadku HAProxy i włączonego SELinuxa. Musimy wygenerowany i dodać odpowiedni moduł:
mkdir /etc/haproxy/selinux
cd /etc/haproxy/selinux
# Wygenerować moduł:
ausearch -m avc -c haproxy | audit2allow -a -M haproxy-conf
# Podgląd zawartości:
cat haproxy-conf.te
module haproxy-conf 1.0;
require {
type redis_port_t;
type ephemeral_port_t;
type haproxy_t;
class tcp_socket { name_bind name_connect };
}
#============= haproxy_t ==============
#!!!! This avc can be allowed using one of the these booleans:
# nis_enabled, haproxy_connect_any
allow haproxy_t ephemeral_port_t:tcp_socket name_connect;
#!!!! This avc is allowed in the current policy
allow haproxy_t redis_port_t:tcp_socket name_bind;
#!!!! This avc can be allowed using the boolean 'haproxy_connect_any'
allow haproxy_t redis_port_t:tcp_socket name_connect;
# Załadować moduł
semodule -i haproxy-conf.pp
Jeżeli obie usługi mamy uruchomione, spróbujmy ponownie uzyskać klucz tym razem łącząc się z wykorzystaniem HAProxy:
# Tworzymy klucz na węźle głównym (R1):
redis.cli
127.0.0.1:6379> SET xyz 123
OK
# Testujemy połączenie z wykorzystaniem HAProxy:
./src/redis-cli --no-auth-warning -a meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2 -h 127.0.0.1 -p 16379 get xyz
"123"
Wartą do zastanowienia rzeczą jest sposób komunikacji między aplikacją a HAProxy i Twemproxy. W tym zestawieniu aplikacja działająca na każdym webie będzie pukać zawsze do HAProxy, które będzie odpytywać Sentinele w celu uzyskania informacji o aktualnym mistrzu. Na podstawie tego ruch zostanie skierowany do usługi Twemproxy uruchomionej na tym samym serwerze co Master. Twemproxy będzie działać bezpośrednio przed instancją główną, dzięki czemu zapewnimy mechanizm buforowania zapytań i utrzymywania połączeń. W przypadku przełączania awaryjnego HAProxy będzie aktualizować lokalizację mistrza i kierować ruch do odpowiedniego procesu Twemproxy.
Pamiętajmy, że uzyskanie 100% dostępności jest praktycznie niemożliwe. Jednak czas powrotu działania wszystkich komponentów jak i działania mechanizmu wykrywania instancji głównej w przypadku wykorzystania powyższych usług jest bardzo mały.
Smitty + alternatywy #
Oczywiście nic nie stoi na przeszkodzie, aby zrezygnować z HAProxy i kierować ruch z aplikacji bezpośrednio do Twemproxy (zyskamy wtedy na wydajności połączenia przez brak dodatkowego przeskoku sieciowego). Wszystko zależy tak naprawdę od wymagań i konkretnych potrzeb. Możemy również postawić HAProxy i Twemproxy (lub tylko to drugie) przed Redisem oraz uruchomić specjalnego agenta, który będzie monitorował instancję główną.
Do tego celu możemy wykorzystać projekt o nazwie Smitty. Jest to agent napisany w języku Go, którego głównym celem jest rozszerzenie możliwości HA serwerów proxy nawet po awarii węzła Redis. Aby to osiągnąć, Smitty stale monitoruje zdarzenia +switch-master łącząc się do Sentinela w celu ich wykrycia. Gdy dojdzie do takiej sytuacji, konfiguracja Twemproxy zostanie zaktualizowana o dane nowego mistrza i w konsekwencji automatycznie uruchomiona ponownie w celu załadowania zmian. Użycie agenta jest tutaj kluczowym elementem, ponieważ w przypadku awansu jednej z replik, przy takiej konfiguracji Twemproxy nadal będzie kierował ruch do starej instancji głównej.
Dzięki takiemu połączeniu wszystkich trzech technologii możemy zapewnić praktycznie doskonałą redundancję. W tym celu możemy w konfiguracji HAProxy pominąć sprawdzanie lokalizacji instancji nadrzędnej odpytując Sentinele i po prostu rozrzucać ruch między wszystkie procesy Twemproxy. Całą logiką wykrywania mistrza i dynamicznego dostosowywania konfiguracji Twemproxy będzie zajmował się proces Smitty.
Konfiguracja będzie wyglądać tak jak poniżej przy wykorzystaniu tego rozwiązania:

Oficjalne repozytorium Smitty przedstawia inną, równie ciekawą grafikę prezentującą wykorzystanie tej usługi. Pozwolę ją sobie umieścić:
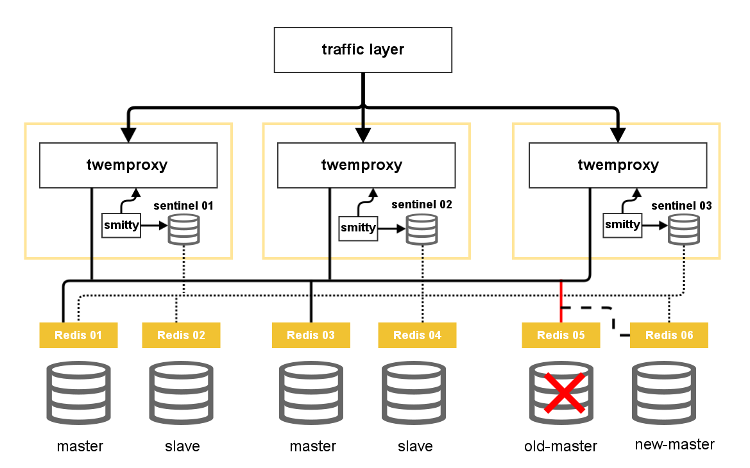
To tyle tytułem krótkiego wstępu do tej usługi. Aby zbudować projekt, w pierwszej kolejności należy pobrać i zainstalować kompilator Go:
wget https://dl.google.com/go/go1.13.5.linux-amd64.tar.gz
tar -xvf go1.13.5.linux-amd64.tar.gz
mv go /usr/lib && ln -s /usr/lib/go/bin/go /usr/bin/go
Następnie instalujemy wymagane zależności:
yum install bzr
Oraz pobieramy i instalujemy pakiet główny:
go get github.com/areina/smitty
ln -s /root/go/bin/smitty /usr/local/sbin/smitty
Na koniec tworzymy katalog na przyszłe konfiguracje oraz logi:
mkdir /etc/smitty /var/log/smitty
Oraz weryfikujemy czy narzędzie działa:
smitty --help
Natomiast konfiguracja jest niezwykle prosta i sprowadza się głównie do ustawienia i dostosowania poniższych parametrów:
twemproxy_pool_name: "redis_stack"
twemproxy_config_file: "/etc/twemproxy/nutcracker.yml"
sentinel_ip: "127.0.0.1"
sentinel_port: "26379"
restart_command: "systemctl restart twemproxy"
log_file: "/var/log/smitty/agent.log"
Musimy jeszcze nadać mu odpowiednie uprawnienia i pamiętać o zrobieniu tego samego dla katalogu z logami:
chown -R root:root /etc/smitty
chown -R root:root /var/log/smitty
Teraz pozostaje jedynie przygotowanie serwisu pod systemd. Umieścimy go w pliku /usr/lib/systemd/system/smitty.service:
[Unit]
Description=Smitty.
After=network.target
[Service]
ExecStart=/usr/local/sbin/smitty -c /etc/smitty/agent.yml -verbose
ExecStop=/bin/kill -SIGTERM $MAINPID
Restart=always
User=root
Group=root
[Install]
WantedBy=multi-user.target
Pozostało jeszcze przeładować konfigurację systemd oraz dodać nowy serwis do autostartu:
systemctl daemon-reload
systemctl enable smitty
Możemy teraz wystartować nową usługę:
systemctl start smitty
Istnieje jeszcze inne rozwiązanie o nazwie redis-twemproxy-agent. Nigdy z niego nie korzystałem, jednak zasada działania jest bardzo podobna do narzędzia opisanego wyżej. Sytuację i możliwą konfigurację złożoną ze wszystkich elementów, w których sprawdza się ten agent, przedstawia poniższa grafika:
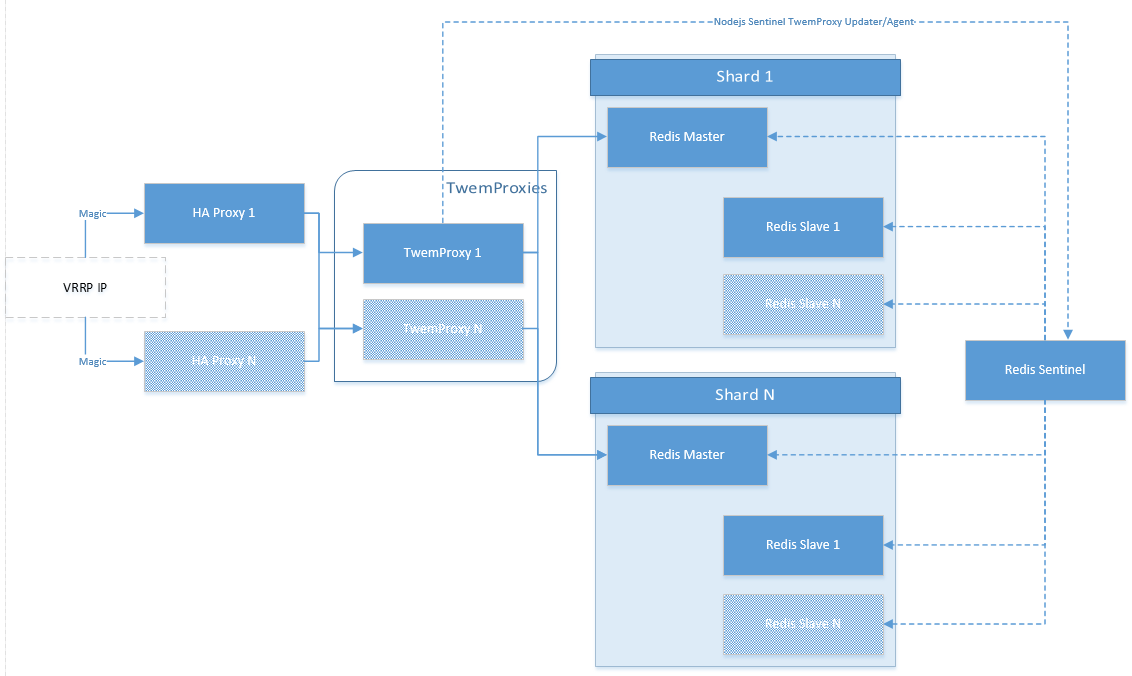
Niestety, nie udało mi się sprawić, aby Smitty aktualizował adres IP nowego mistrza. Druga sprawa jest taka, że przy ustawionym parametrze requirepass w konfiguracji Sentineli, nie będzie możliwości podłączenia się do nich z poziomu obu rozwiązań. Zacząłem zastanawiać się, czy jest w ogóle sens stosowania takiego rozwiązania, a jeśli tak, to czy nie da się zrobić tego prościej. W niektórych przypadkach wykorzystanie Smitty ma sens zwłaszcza wtedy, kiedy nie wykorzystujemy HAPRoxy lub nie mamy mechanizmu, który będzie lokalizował serwer nadrzędny.
Po chwili namysłu napisałem bardzo proste narzędzie:
#!/usr/bin/env bash
_REDIS_CLI="/root/redis/src/redis-cli"
_MASTER_ID="mymaster"
_SENTINEL_IP="$1"
_SENTINEL_PORT="$2"
_SENTINEL_CFG="/etc/redis-sentinel.conf"
_TWEMPROXY_CONFIG="/etc/twemproxy/nutcracker.yml"
_TWEMPROXY_POOL="redis_stack"
_TWEMPROXY_RESTART="systemctl restart twemproxy"
_LOG_FILE="/var/log/twemproxy/twemproxy-change-master.log"
_CHECK_INTERVAL="5"
echo -en "Start Twemproxy Agent.\\n" >> "$_LOG_FILE"
while : ; do
_MASTER_PARAMS=$("$_REDIS_CLI" --no-auth-warning \
-a `grep '^requirepass' $_SENTINEL_CFG | awk '{print $2}' | sed 's/"//g'` \
-h "$_SENTINEL_IP" \
-p "$_SENTINEL_PORT" \
SENTINEL get-master-addr-by-name $_MASTER_ID)
# pip install shyaml
_MASTER_OLD_PARAMS=$(cat "$_TWEMPROXY_CONFIG" | \
shyaml get-value ${_TWEMPROXY_POOL}.servers | \
awk '{print $2}')
_MASTER_IP=$(echo "$_MASTER_PARAMS" | tr '\r\n' ':' | awk -v FS="(:|:)" '{print $1}')
_MASTER_PORT=$(echo "$_MASTER_PARAMS" | tr '\r\n' ':' | awk -v FS="(:|:)" '{print $2}')
_MASTER_OLD_IP=$(echo "$_MASTER_OLD_PARAMS" | tr '\r\n' ':' | awk -v FS="(:|:)" '{print $1}')
_MASTER_OLD_PORT=$(echo "$_MASTER_OLD_PARAMS" | tr '\r\n' ':' | awk -v FS="(:|:)" '{print $2}')
if [[ "$_MASTER_OLD_IP" != "$_MASTER_IP" ]] ; then
echo -en \
"detect new master: ${_MASTER_OLD_IP}:${_MASTER_OLD_PORT} -> ${_MASTER_IP}:${_MASTER_PORT}\\n" \
>> "$_LOG_FILE"
sed -i "s|${_MASTER_OLD_IP}:${_MASTER_OLD_PORT}|${_MASTER_IP}:${_MASTER_PORT}|g" \
"$_TWEMPROXY_CONFIG"
if grep "\- ${_MASTER_IP}:${_MASTER_PORT}:" "$_TWEMPROXY_CONFIG" ; then
echo -en \
"select new master: ${_MASTER_OLD_IP}:${_MASTER_OLD_PORT} -> ${_MASTER_IP}:${_MASTER_PORT}\\n" \
>> "$_LOG_FILE"
$_TWEMPROXY_RESTART
fi
fi
sleep "$_CHECK_INTERVAL"
done
Nie jest ono idealne i wymaga kilku poprawek takich jak weryfikacja połączenia do Sentineli, weryfikacja autoryzacji czy logowanie czasu wykonania komend. Jednak w takiej formie działa i to całkiem dobrze. Zapiszmy w takim razie powyższy kod do pliku /usr/local/sbin/twemproxy-change-master i ustawmy uprawnienia wykonywania:
chmod a+x /usr/local/sbin/twemproxy-change-master
Oczywiście przed użyciem musisz dostosować początkowe zmienne. Narzędzie wywołuje się w ten sposób:
twemproxy-change-master 127.0.0.1 26379
Przygotujmy w takim razie nowy serwis pod systemd i poniższą konfigurację dodajmy do pliku /usr/lib/systemd/system/twemproxy-agent.service:
[Unit]
Description=Twemproxy Agent.
After=network.target
[Service]
ExecStart=/usr/local/sbin/twemproxy-change-master 127.0.0.1 26379
ExecStop=/bin/kill -SIGTERM $MAINPID
Restart=always
User=root
Group=root
[Install]
WantedBy=multi-user.target
Pozostało jeszcze przeładować konfigurację systemd oraz dodać nowy serwis do autostartu:
systemctl daemon-reload
systemctl enable twemproxy-agent
Możemy teraz wystartować nową usługę:
systemctl start twemproxy-agent
Na koniec przetestować czy wszystko działa.