Redis: Kilka słów wprowadzenia
05 Sep 2020
database debugging nosql performance redis redis-cluster redis-sentinel replication
Do napisania serii artykułów o Redisie nakłoniły mnie ostatnie problemy, które musiałem rozwiązać na jednym ze środowisk produkcyjnych. Mówiąc dokładniej, chodziło o analizę replikacji Redisa, który złożony był z jednej instancji głównej i dwóch instancji podrzędnych. Administruję tą technologią na co dzień i byłem pewien, że znam w większości jej tajniki oraz to jak działa i jak zachowuje się w przypadku awarii. Myliłem się. Jeżeli administrujesz środowiskami, które wykorzystują usługę Redis w takiej lub podobnej konfiguracji, najprawdopodobniej potwierdzisz moje słowa, że odpowiednio zestawiona replikacja działa prawie bezobsługowo.
Ta seria artykułów jest zorganizowanym zbiorem materiałów, które powinny pomóc zrozumieć niektóre z mechanizmów występujących głównie przy replikacji Master-Slave wykorzystującą dodatkowo usługę Redis Sentinel. Takie połączenie jest chyba najczęstszym i najprostszym wykorzystaniem tych usług w środowiskach produkcyjnych. Starałem się zebrać najważniejsze tematy i na podstawie własnego doświadczenia zwrócić uwagę na istotne kwestie dotyczące zwłaszcza tego rodzaju replikacji asynchronicznej.
Przed przystąpieniem do czytania zachęcam do zapoznania się z poniższymi zasobami:
- Redis Documentation
- Redis Commands
- Redis in Action
- Salvatore ‘antirez’ Sanfilippo Blog
- Learn Redis the hard way (in production)
- StackExchange.Redis
- Memory Optimization for Redis
- Intro to Redis Presentation 2013 [PDF]
- The System Design Primer
- Scalability, Availability & Stability Patterns
- Try Redis, a demonstration of the Redis database!
Oraz książkami Redis Essentials i Redis 4.x Cookbook. Natomiast w przypadku problemów, warto zajrzeć do artykułu Problems with Redis? This is a good starting point. Jeżeli w którymś momencie napotkasz trudności lub coś będzie dla Ciebie nie jasne, niech powyższe zasoby będą pierwszymi, w których będziesz szukał pomocy.
Czym właściwie jest Redis? #
Strona domowa projektu opisuje go w ten oto sposób:
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker. It supports data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes with radius queries and streams.
Czyli jest to magazyn danych umieszczony w pamięci serwera, który obsługuje wiele struktur danych, używany najczęściej jako baza danych, pamięć podręczna lub tzw. broker komunikatów. Generalnie Redis jest bazą danych NoSQL typu klucz-wartość (ang. key-value stores), w której każdy element jest przechowywany właśnie jako para klucz-wartość, gdzie każdy możliwy klucz (identyfikator) pojawia się maksymalnie raz, zaś dane nie są przechowywane w tabelach ani nie istnieją w niej żadne relacje. Wniosek z tego taki, że łatwość zapisu i pobierania danych oraz szybkość działania jest ważniejsza od skomplikowanej struktury danych. Jednym z najważniejszych mechanizmów w przypadku tego typu baz, jest konieczność odpowiedniego zarządzania pamięcią, czyli najczęściej zapewnienie kompresji danych czy algorytmów zwalniających pamięć.
Baza tego typu jest chyba najprostszym rozwiązaniem spośród baz danych NoSQL natomiast Redis używa zaawansowanego magazynu klucza i wartości z opcjonalnym zapisem danych na dysk. Zaawansowanego, ponieważ klucze mogą zawierać ciągi, skróty czy listy (dlatego nazywany jest często serwerem struktury danych) oraz zapewnia dodatkowe mechanizmy takie jak wbudowana replikacja, skrypty Lua, transakcje, a także zapewnia wysoką dostępność za pośrednictwem usługi Redis Sentinel lub automatycznego partycjonowania (ang. sharding) za pomocą klastra.
Co istotne Redis obsługuje ogromną liczbę języków programowania z ogromną listą klientów. Kilka najpopularniejszych znajduje się poniżej:
- C (hiredis, hiredis-vip)
- C# (Redis, StackExchange.Redis)
- Java (Jedis, lettuce)
- Python (redis-py)
- js (ioredis, node_redis)
- PHP (phpredis, Predis)
- Go (Radix)
Pierwotnym założeniem Redisa było posiadanie określonego klucza lub identyfikatora dla każdego pojedynczego fragmentu danych. Szybko rozszerzono tę koncepcję na typy danych, w których pojedynczy klucz może odnosić się do wielu fragmentów. Następnie idea klucza została jeszcze bardziej rozszerzona, ponieważ pojedynczy fragment danych mógł obejmować wiele kluczy. Dlatego obecnie, jeśli mówimy, że Redis jest bazą typu klucz-wartość, należy mieć świadomość, że jest on bazą typu klucz-wartość „na sterydach”.
Redis jest obecnie uznawany za jedną z najszybszych baz danych i jest naprawdę przepotężnym narzędziem wykorzystywanym dość intensywnie w środowiskach produkcyjnych (także przez naprawdę znaczące organizacje), często obejmujących kilka centrów danych czy nawet obszarów geograficzny.
W wielu przypadkach Redis jest stosowany jako miejsce do przechowywania danych przejściowych takich jak sesje klientów (zamiast wykorzystywania plików lub bazy danych) czy obiektów generowanych przez aplikację, które mogą zostać ponownie użyte, jednak spisuje się równie świetnie w przypadku kolejkowania wiadomości, buforowania (które ma bardzo często kluczowe znaczenie dla witryny o dużym natężeniu ruchu) czy operacji wykonywanych w czasie rzeczywistym. Krótko mówiąc, jeżeli potrzebujesz miejsca do zapisywania naprawdę dużych ilości danych lub znajdziesz wąskie gardło w Twojej aplikacji czy systemie i planujesz rozwiązać je za pomocą pamięci podręcznej, najprawdopodobniej wybierzesz Redisa.
Bardzo często można spotkać się z porównaniem, co jest lepsze, Redis czy inny niezwykle znany i często stosowany system buforowania pamięci podręcznej — Memcached. Myślę, że świetną odpowiedź znajdziesz tutaj: Memcached vs. Redis?. Ogromnymi zaletami Redisa w porównaniu z Memcached są potężne typy danych i mnogość poleceń umożliwiających ich wykorzystanie. Redis potrafi zapewnić trwałość danych, zapisując je na dysk. Co bardzo istotne, jest on niezwykle szybki (może wykonać 100 000 zapytań na sekundę) praktycznie w każdej sytuacji i we wszystkim, do czego jest przeznaczony. Jeśli interesuje Cię porównanie Redisa z innymi tego typu bazami, polecam trzy poniższe prace:
- Which NoSQL Database? A Performance Overview [PDF]
- Solving Big Data Challenges for Enterprise Application Performance Management [PDF]
- Performance Evaluation of NoSQL Systems [PDF]
Przy okazji zapoznaj się z forkiem projektu Redis o nazwie KeyDB, który przedstawiony został w artykule A Multithreaded Fork of Redis That’s 5X Faster Than Redis.
Osobiście uważam, że każde z wymienionych przed chwilą rozwiązań nie będzie prawdopodobnie wąskim gardłem w Twojej infrastrukturze. Tak naprawdę możliwymi limitami prędkości działania nie jest sam Redis czy inne tego typu rozwiązanie, które rzadko są winowajcami, gdy aplikacja zwalnia, a sieć i przepustowość pamięci (zamiast procesora).
Redis jako pamięć podręczna #
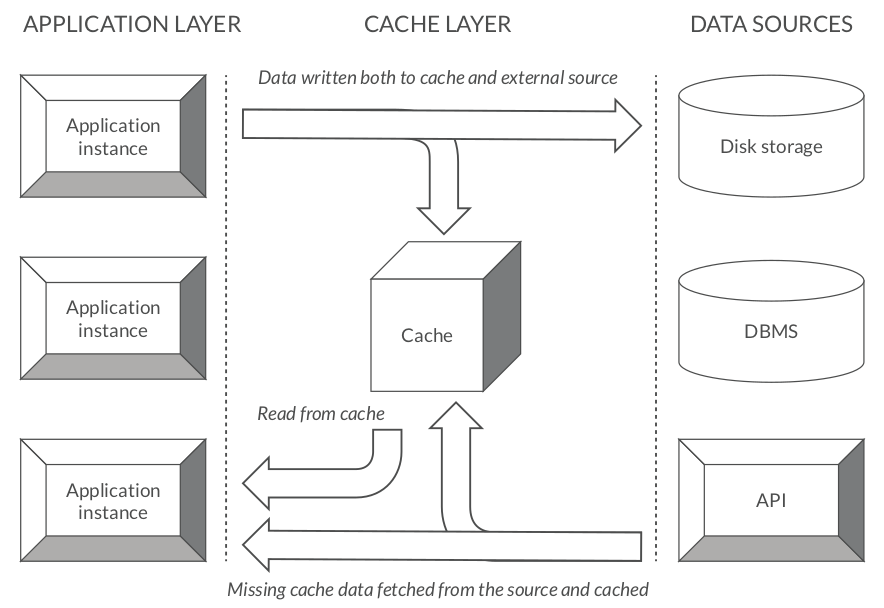
Jest to chyba najczęstsze wykorzystanie Redisa. Głównym celem pamięci podręcznej jest skrócenie czasu potrzebnego na dostęp do danych przechowywanych poza pamięcią główną aplikacji. Pamięć podręczna skutecznie zmniejsza zapotrzebowanie na zasoby potrzebne do obsługi danych będących poza przestrzenią aplikacji. Pozwala zoptymalizować, zmniejszyć a w niektórych przypadkach wyeliminować wszystkie niepotrzebne wywołania z warstwy backendu. Bez tego typu magazynu danych aplikacja wymagałaby połączenia ze źródłem danych przy każdym zapytaniu, podczas gdy użycie pamięci podręcznej wymaga tylko jednego żądania do zewnętrznego źródła po to, by następnie dostęp był obsługiwany już bezpośrednio z niej.
Dlaczego mielibyśmy w ogóle wykorzystać cache? Ponieważ pamięć podręczna działa błyskawicznie. Przechowuje każdy zestaw danych w pamięci RAM, a żądania są obsługiwane tak szybko, jak to technicznie możliwe. Na przykład Redis może wykonać kilkaset tysięcy operacji odczytu na sekundę, gdy jest hostowany serwerze o klasycznej konfiguracji. Również zapisy, zwłaszcza przyrosty, są bardzo, bardzo szybkie. Nie osiągniemy tego z bazą danych typu SQL. Pamięć podręczna to prosty magazyn klucza i wartości, który powinien znajdować się jako warstwa buforująca między aplikacją a trwałym magazynem danych. Ilekroć aplikacja ma odczytać dane, powinna najpierw spróbować pobrać je z pamięci podręcznej. Jeżeli operacja zakończy się niepowodzeniem, dopiero wtedy powinna spróbować pobrać dane z głównego źródła danych.
Dzięki pamięci podręcznej Redis jest w stanie tymczasowo przechowywać dane specyficzne dla użytkownika, na przykład przedmioty przechowywane w koszyku. Dodatkowo dzięki zapisom do pliku, co może być niekiedy kluczowe także w przypadku danych tymczasowych, użytkownicy nie tracą swoich danych w przypadku wylogowania lub utraty połączenia. Chociaż utrzymywanie pamięci podręcznej nie jest zazwyczaj krytyczne pod względem spójności, większość użytkowników nie byłaby zachwycona, gdyby wszystkie sesje koszyka zniknęły.
Widzisz, że wykorzystanie pamięci podręcznej ma ogromny wpływ na wydajność jak i dostępność aplikacji. Zewnętrzne źródła danych mogą ulec awarii, która spowoduje niedostępność usługi. Podczas takich przestojów pamięć podręczna może nadal udostępniać dane, a tym samym zachować ciągłą dostępność aplikacji.
Jednym z najczęstszych zastosowań Redisa jest umieszczenie go przed innymi, wolniejszymi bazami danych, aby działał jako szybka pamięć podręczna przechowująca np. sesje użytkowników lub pamięć dla warstwy interfejsów API.
Każda instancja Redis ma swój własny plik konfiguracyjny i można ją dostroić zgodnie z konkretnym przypadkiem użycia. Na przykład serwery buforujące można skonfigurować tak, aby używały trwałości RDB do okresowego zapisywania pojedynczej kopii zapasowej. Wykonywanie okresowych migawek maksymalizuje wydajność kosztem spójności z dokładnością do sekundy. W przypadku pamięci podręcznej, podczas awarii, można stracić część danych, jednak po ponownym uruchomieniu będzie ona nienaruszona i wygrzana.
Redis pracujący jako pamięć podręczna może korzystać z kilku wzorców (przy odpowiedniej implementacji), które powinny być bezpośrednio związane z buforowaniem i celami, jakie stawia się przed aplikacją, a także dostępnymi elementami infrastruktury. Ponieważ w pamięci podręcznej możesz przechowywać tylko ograniczoną ilość danych, musisz określić, która strategia aktualizacji zadziała najlepiej w Twoim przypadku użycia. Innymi słowy, podczas projektowania musisz odpowiedzieć na pytania, w jaki sposób dane będą zapisywane i odczytywane oraz ile tych operacji będzie wykonywane. Na przykład:
- czy aplikacja opiera się głównie na zapisach, a odczyty występują sporadycznie? (np. dzienniki, skomplikowane obliczenia wymagające zapisów)
- czy dane są zapisywane raz a odczytywane wielokrotnie? (np. profil użytkownika)
- czy zwracane dane są zawsze niepowtarzalne? (np. zapytania wyszukiwania)
Najprawdopodobniej (świadomie bądź nie) wykorzystasz kilka technik, które w niektórych sytuacjach się uzupełniają. Niezależnie jednak od wyboru danej strategi lub połączenia kilku z nich, pamiętaj o odpowiedniej obsłudze kluczy, odpowiednim zarządzaniu ich wygasaniem i odświeżaniem pamięci podręcznej, a także konieczności zachowania spójności między pamięciami rezydującymi na różnych poziomach. Wszystkie te rzeczy zależą od kompromisu, jaki chcesz osiągnąć, między kosztem aktualizacji pamięci podręcznej a ryzykiem obsługi nieaktualnych danych.
Gorąco zachęcam do zapoznania się ze świetnym artykułem pod tytułem Consistency between Redis Cache and SQL Database, a także repozytorium The System Design Primer - When to update the cache.
Strategie buforowania #
Poniżej znajdują się możliwe wzorce do wykorzystania podczas projektowania środowiska wykorzystującego usługę Redis:
Cache-Aside (Lazy Loading) - jest to najpopularniejsza dostępna strategia buforowania. Jej działanie można podsumować następująco:
- Gdy aplikacja musi odczytać dane, np. z bazy danych, najpierw sprawdza pamięć podręczną, aby określić, czy dane, których potrzebuje są w niej przechowywane
- Jeśli dane są dostępne (Cache HIT), zwracane są natychmiast do klienta
- Jeśli dane nie są dostępne (Cache MISS), do bazy danych jest wysyłane zapytanie w celu ich uzyskania
- Następnie dane pobrane z bazy mogą być umieszczone w pamięci podręcznej w celu ponownego ich użycia
Dzięki tej technice pamięć podręczna zawiera tylko te dane, których aplikacja faktycznie żąda, co pomaga zachować rozmiar pamięci podręcznej na akceptowalnym i opłacalnym poziomie. Nowe obiekty są dodawane do pamięci podręcznej tylko w razie potrzeby. Dodatkowo możesz zarządzać pamięcią podręczną, po prostu pozwalając Redisowi eksmitować (odpowiada za to parametr maxmemory-policy) najmniej używane klucze w miarę zapełniania się pamięci podręcznej.
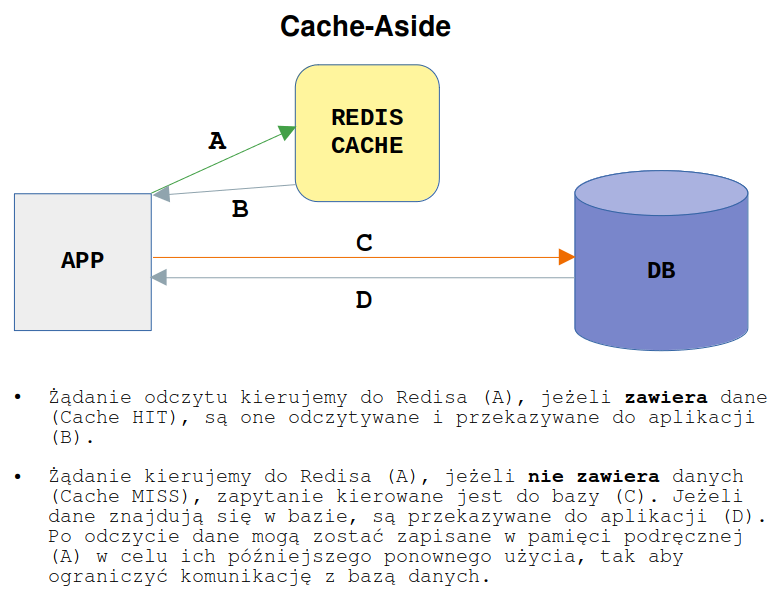
Pamięć podręczna tego typu jest zwykle przeznaczona do celów ogólnych i najlepiej sprawdza się w przypadku obciążeń z dużą ilością odczytów. Wykorzystanie tej techniki zapewnienia odporność na niedostępność pamięci podręcznej, ponieważ jeśli ulegnie ona awarii, zapytania mogą być kierowane do bazy danych z pominięciem cache.
Tak naprawdę ta strategia buforowania powinna być fundamentem, którego można używać w aplikacji, a pozostałe wzorce powinny być bardziej optymalizacją, którą można zastosować w określonych sytuacjach.
Co niezwykle istotne:
- każde chybienie (Cache MISS) skutkuje wykonaniem przynajmniej trzech skoków, które mogą powodować zauważalne opóźnienie
- dane mogą stać się nieaktualne, jeśli zostaną zaktualizowane w bazie danych. Ten problem można rozwiązań przez ustawienie czasu wygasania (TTL), który wymusza aktualizację wpisu pamięci podręcznej lub przez wykonanie operacji zapisu
Write-Through - w tej technice pamięć podręczna jest aktualizowana w czasie rzeczywistym podczas aktualizacji bazy danych. Zamiast zapisywania danych bezpośrednio do bazy, są one najpierw ładowane do pamięci podręcznej, po czym natychmiast aktualizowane w bazie danych. Jej działanie można podsumować następująco:
- Aplikacja wykorzystuje cache jako główny magazyn danych, odczytując i zapisując do niego dane
- Natomiast cache odpowiada za odczyt i zapis do bazy danych
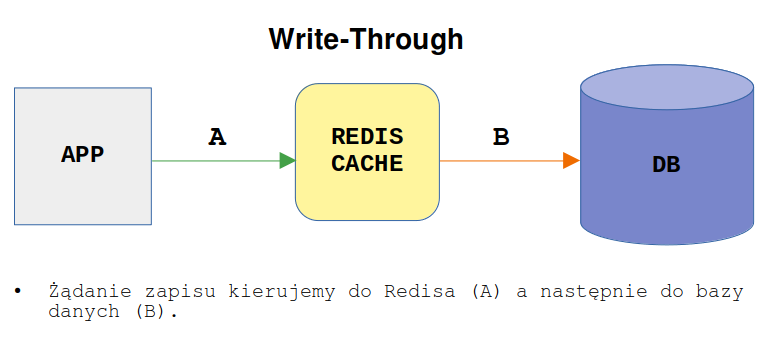
W tej strategii zapis jest wykonywany synchronicznie do obu magazynów danych. Pamięć podręczna znajduje się w linii z bazą danych, a zapisy zawsze przechodzą przez nią do pamięci głównej. Ogromną zaletą tego trybu jest pewność, że posiadamy kopię danych i pamięć podręczna jest zawsze aktualna, ponieważ jeśli dojdzie do zapisu w pamięci podręcznej, przy zachowaniu dostępności pamięci głównej, zawsze znajdzie się aktualna kopia, która jest w niej umieszczona.
Ten tryb jest łatwy w użyciu i pozwala uniknąć błędów pamięci podręcznej, co może pomóc aplikacji działać lepiej i szybciej. Jednak zapisywanie danych jest ogólnie powolne, ponieważ tego typu strategia wprowadza dodatkowe opóźnienie zapisu, tj. dane są najpierw zapisywane w pamięci podręcznej, a następnie w głównej bazie danych (każde trafienie zapisu musi zostać wykonane dwa razy). Może to nie tylko wymagać dodatkowej pamięci, ale także spowodować usunięcie bardziej przydatnych elementów przez niewykorzystywane dane, które są niepotrzebnie przechowywane przez cały czas. Jednak w połączeniu ze strategią Read-Through zyskujemy wszystkie zalety odczytu i zapisu, a także gwarancję spójności danych.
Jak możesz się domyślić, można połączyć buforowaniem z zapisem z leniwym buforowaniem (pierwsza strategia) w celu rozwiązania niektórych problemów, ponieważ obie strategie są powiązane z przeciwnymi stronami przepływu danych. Leniwe buforowanie wyłapuje błędy pamięci podręcznej podczas odczytu, a buforowanie z zapisem zapełnia dane przy zapisach, więc te dwa podejścia się uzupełniają.
Co niezwykle istotne:
- gdy zostanie dodany nowy węzeł, nie będzie on buforował odpowiedzi, dopóki odpowiedni wpis nie zostanie zaktualizowany w bazie danych (można to załagodzić techniką Cache-Aside)
- większość zapisanych danych może nigdy nie zostać odczytana, co można zminimalizować za pomocą TTL
Read-Through - w tej technice podobnie jak w przypadku strategii Write-Through dla zapisów, wszystkie odczyty przechodzą przez pamięć podręczną. W ten sposób pamięć podręczna jest zawsze zgodna z bazą danych. W przypadku braku danych w pamięci podręcznej (Cache MISS) brakujące dane są ładowane z bazy, a następnie umieszczane są w pamięci podręcznej i zwracane do aplikacji. Jest to podobna strategia do Cache-Aside, jednak w tym przypadku dane pobierane z bazy są zawsze umieszczane w pamięci podręcznej. Jej działanie można podsumować następująco:
- Aplikacja odczytuje dane najpierw z pamięci podręcznej a następnie z bazy (pierwszy odczyt)
- Następnie dane są natychmiast aktualizowane w pamięci podręcznej i dalej czytane z niej
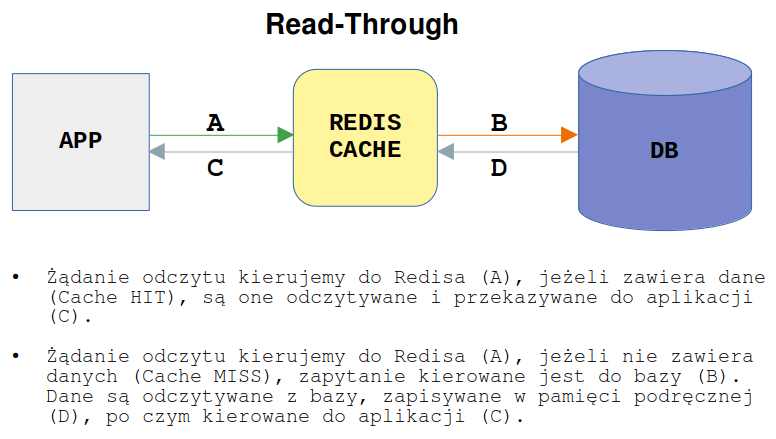
Pamięć podręczna do odczytu znajduje się w linii (a nie obok) z bazą danych. W przypadku braku obiektu w pamięci podręcznej jest on odczytywany z bazy danych, następnie dane są umieszczane w pamięci podręcznej i zwracane do aplikacji. Pamięć tego typu działa najlepiej w przypadku obciążeń z dużą ilością odczytów, zwłaszcza gdy te same dane są żądane wiele razy. Wadą jest to, że gdy dane są żądane po raz pierwszy, zawsze powoduje to brak pamięci podręcznej i wiąże się z dodatkowym opóźnieniem wczytywania danych z bazy. Jednym z rozwiązań jest ręczne wysyłanie najczęstszych zapytań (zwane wygrzewaniem pamięci podręcznej), aby zostały one umieszczone w pamięci podręcznej.
Write-Back/Write-Behind - jest to podobna strategia do Write-Through, z tą różnicą, że pamięć podręczna nie aktualizuje bazy danych przy każdej operacji zapisu. Zamiast tego aktualizuje bazę danych po określonym czasie w celu zmniejszenia liczby połączeń sieciowych. W tym przypadku aplikacja zapisuje dane do pamięci podręcznej, która natychmiast potwierdza i po pewnym opóźnieniu zapisuje dane do bazy danych. Gdy dane są aktualizowane, są zapisywane tylko w pamięci podręcznej, a zapisy do pamięci głównej wykonywane są tylko wtedy, gdy dane z pamięci podręcznej są usuwane.
Główną zaletą tego trybu jest to, że zapisy następują z prędkością pamięci podręcznej, a wielokrotne zapisy w bloku wymagają tylko jednego zapisu do pamięci głównej, co w rezultacie zużywa mniej przepustowości pamięci. Natomiast największym minusem jest to, że pamięć główna nie zawsze jest zgodna z pamięcią podręczną, więc możemy stracić spójność danych.
Co niezwykle istotne:
- może dojść do utraty danych, jeśli pamięć podręczna ulegnie awarii, zanim jej zawartość trafi do bazy danych
- implementacja zapisu z opóźnieniem jest bardziej skomplikowana niż implementacja odkładania na bok lub zapisu w pamięci podręcznej
Single-threaded vs Multi-threaded #
W przeciwieństwie do Memcached, który jest wielowątkowy, Redis uruchamia tylko jeden wątek na proces. Implementuje on prostą bibliotekę sterowaną zdarzeniami opartą na multipleksowaniu I/O, a wybór danego rozwiązania zależy oczywiście od systemu, na którym został uruchomiony. Cała logika zdefiniowana jest w pliku ae.c:
/* Include the best multiplexing layer supported by this system.
* The following should be ordered by performances, descending. */
#ifdef HAVE_EVPORT
#include "ae_evport.c"
#else
#ifdef HAVE_EPOLL
#include "ae_epoll.c"
#else
#ifdef HAVE_KQUEUE
#include "ae_kqueue.c"
#else
#include "ae_select.c"
#endif
#endif
#endif
Moim zdaniem, brak wielowątkowości jest jedną z większych wad Redisa (przy okazji zerknij do artykułu WHY Redis choose single thread (vs multi threads)), jednak, co chcę wyraźnie zaznaczyć, jednowątkowość zwykle nie stanowi (wielkiego) problemu w jego przypadku. Jeżeli chcemy w pełni wykorzystać kilka rdzeni i jeśli zajdzie potrzeba skalowania poza jeden lub kilka wątków, jesteśmy w stanie uruchomić kilka procesów Redis na danej maszynie. W takim przypadku możemy skonfigurować instancję (np. klastra) dla każdego rdzenia procesora, jeśli zajdzie potrzeba zmaksymalizowania liczby wątków. Co niezwykle istotne w kontekście Redisa i wielowątkowości, to należy pamiętać, że Redis nie jest związany z procesorem tak mocno jak z pamięcią czy siecią.
Oczywiście wszelkie dostępne testy wskazują na większą wydajność w przypadku wykorzystania wielu rdzeni najprawdopodobniej ze względu na możliwą dużą ilość zadań blokujących operacje I/O, które można wykonać. W takich sytuacjach wzrost wydajności może być zauważalny, zakładając, że dodatkowa praca może zostać wykonana, gdy wykonywane są operacje I/O. Jeśli jednak zadania są zdominowane przez tego typu operacje, to głównym czynnikiem ograniczającym jest prędkość podsystemu i urządzeń I/O, a nie procesora.
Co również niezwykle istotne, Redis jako aplikacja jednowątkowa także w wersjach starszych obsługiwał niektóre z operacji z rozbiciem na wątki. Wspomina o tym fragment pliku konfiguracyjnego:
Redis is mostly single threaded, however there are certain threaded operations such as UNLINK, slow I/O accesses and other things that are performed on side threads.
Sytuacja uległa nieznacznej zmianie od wersji 6.x (więcej na ten temat poczytasz w artykule An update about Redis developments in 2019), w której zaimplementowano koncepcję wielowątkowego I/O. Polega to głównie na wykonywaniu operacji zapisu do gniazda, które jak wiemy, są operacjami powolnymi, z rozbiciem na kilka wątków. Do tej pory optymalizacją było wykorzystanie potoków lub uruchomienie kilku procesów na tej samej maszynie. Nowa koncepcja pozwala na przetworzenie większej liczby żądań i może znacznie zwiększyć wydajność, np. w przypadku synchronizacji między mistrzem a repliką, a także zminimalizować częsty problem zbyt długich poleceń, tj. komendy MGET z dużą liczbą kluczy. Podejście autorów do wielowątkowości jest nadal konserwatywne, jednak powyższa optymalizacja poprawia główny problem, którym jest spora ilość czasu poświęcana na operacje odczytu i zapisu z i do gniazda zwłaszcza dla przetwarzania, które zajmuje dużo czasu, powodując bardzo często przekroczenie limitu czasu żądania.
Widzimy, że wielowątkowość w Redisie nie jest do końca prawdą, ponieważ jest on nadal jednowątkowy na poziomie użytkownika, natomiast wszystkie asynchroniczne operacje I/O są obsługiwane przez pule wątków jądra. Oznacza to, że na serwerze, na którym został uruchomiony Redis, obsługa współbieżnych operacji I/O świadczy jedynie o tym, że może on obsługiwać kilku klientów, wykonując kilka operacji odpowiadających tym klientom jednak nadal z jedną jednostką obliczeniową.
Widzimy, że Redis nadal nie jest w stanie zapewnić równoległości (ang. parallelism). Dobrą analogią jego działania jest przykład barmana, który może opiekować się kilkoma klientami, a jednocześnie może przygotować tylko jeden napój. W ten sposób zapewnia współbieżność bez równoległości.
Za obsługę operacji I/O przez wiele wątków odpowiada parametr io-threads, przy czym przed jego włączeniem zapoznaj się z dokumentacją i miej na uwadze opinię głównego autora projektu:
You need to test in a box with at least 8 cores or so. With just two cores performances can even drop especially if you also run the benchmark itself there.
Z drugiej strony, biorąc pod uwagę kosmiczną szybkość Redisa, pojedynczy proces wydaje się być wystarczający dla większości przypadków. Dzieje się tak jednak do momentu, gdy ruch nie zacznie znacznie wzrastać i nie będzie utrzymywał się na takim poziomie przez dłuższy czas, a zadania w tle nie będą uruchamiane w sposób ciągły. Jedną z optymalizacji wykorzystywania Redisa jako pamięci podręcznej jest uruchomienie wielu oddzielnych instancji (także na tym samym serwerze), w celu zmniejszenia wykorzystania pojedynczego procesu.
Forki projektu, tj. Thredis i KeyDB, zapewniają własne implementacje wątków. KeyDB uruchamia normalną pętlę zdarzeń w wielu wątkach, a autorzy tego projektu wspominają nawet o pięciokrotnym wzroście wydajności. Redis 6.x implementuje wątki w mniejszym stopniu niż te rozwiązania, ale mimo to zapewnia znaczną poprawę wydajności bez dokonywania większych zmian architektonicznych. Testy porównawcze znajdziesz w artykule Comparing the new Redis6 multithreaded I/O to Elasticache & KeyDB.
Wracając jeszcze do wersji 6.x, to wprowadzono w niej koncepcję przypinania (ang. pinning) różnych wątków do danego procesora/rdzenia, dzięki czemu możemy zarezerwować określony rdzeń dla określonego wątku, który będzie wykonywany. Co istotne, pozwala to na przypięcie wątków do kilku mechanizmów występujących w Redisie, tj. procesu głównego serwera, wątków I/O, procesu potomnego zapisów AOF, a nawet przypięciu procesu odpowiedzialnego za zapisy komendą BGSAVE. Więcej informacji na ten temat znajdziesz w pliku konfiguracyjnym dla wersji 6.x.
Master-Slave vs Redis Cluster #
Są to dwie różne rzeczy i należy mieć świadomość, że Redis może pracować w obu trybach, które prezentują odmienne podejścia do replikacji oraz rozkładania danych pomiędzy węzłami. Poniższy zrzut prezentuje możliwe rozwiązania, które oczywiście mogę się delikatnie różnić w zależności od potrzeb:
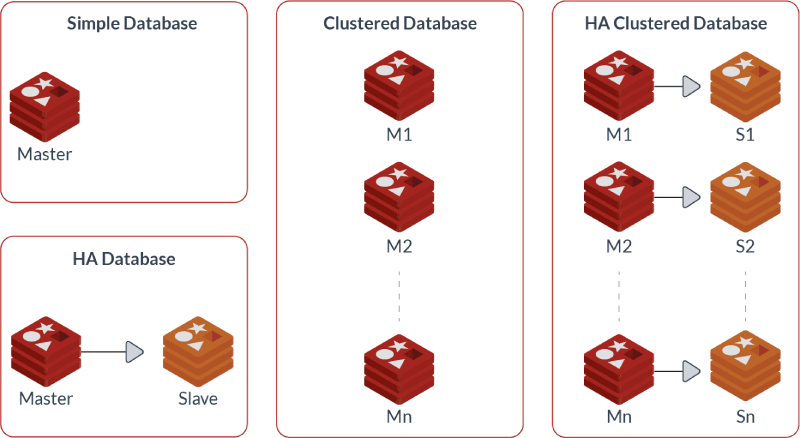
Natomiast bardzo ciekawe wyjaśnienie kilku koncepcji znajdziesz w artykule What Redis deployment do you need ?.
Tak naprawdę, pierwszą formą działania Redisa jest pojedynczy węzeł, czyli podstawowe rozwiązanie, w którym uruchamiasz pojedynczy proces Redis. Nie zapewnia on ani skalowalności, ani wysokiej dostępności. Tymczasem pierwszą formą replikacji jest replikacja asynchroniczna w konfiguracji Master-Slave (zerknij do rozdziału Replication oficjalnej dokumentacji). Można ją nazwać trybem pojedynczej instancji, ponieważ konfiguracja tego typu oznacza, że jeden serwer jest wyznaczony jako serwer główny, czyli tzw. mistrz (Master), który obsługuje zapisy i odczyty, a pozostałe działają jako serwery podrzędne/repliki, czyli jako tzw. podwładni (Slave), przechowując kopię danych instancji głównej i jednocześnie pozwalając tylko na operacje odczytu (domyślnie). Oczywiście w takiej konfiguracji Redis może obsługiwać wiele urządzeń podrzędnych replikujących dane z węzła głównego.
W tym trybie pracy Redis wykorzystuje replikację asynchroniczną, co oznacza, że gdy Master dokona zmiany, to nie ma żadnej pewności, że serwer podrzędny otrzyma te dane natychmiast. Zwykle replikacja odbywa się w czasie rzeczywistym, jednak nie ma żadnej gwarancji co do czasu wymaganego do rozprzestrzenienia się zmiany do serwerów podrzędnych. Mówiąc jednak dokładniej, Redis używa strumieniowej replikacji asynchronicznej, która jest jedną z najprostszych form replikacji, jaką można sobie wyobrazić: ciągły strumień zapisów jest wysyłany do replik, bez czekania, aż przetworzą one zapisy w jakikolwiek sposób przed odpowiedzią klientowi.
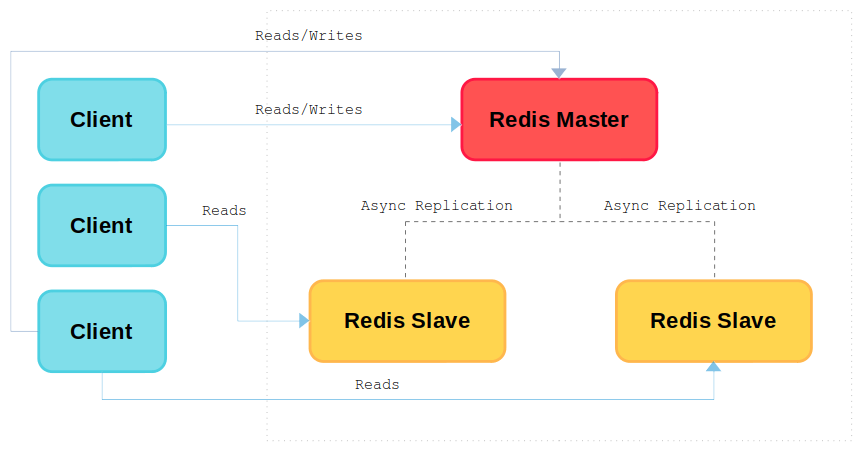
Natomiast aby zapewnić automatyczne wykrywanie awarii i możliwość automatycznego promowania nowego mistrza, należy użyć usługi Redis Sentinel. Dzięki takiemu rozwiązaniu pojedyncza grupa wartowników/strażników (ang. sentinels) jest w stanie zarządzać wieloma instancjami Redis — w większości przypadków bez ingerencji administratora.
Oczywiście nic nie stoi na przeszkodzie, aby wdrożyć dowolną liczbę mistrzów, z dowolną liczbą niewolników (kolejna forma działania Redisa), jednak będą one zachowywać się jak pojedyncze oddzielne instancje z własną przestrzenią adresową, a obowiązkiem architekta aplikacji będzie prawidłowe rozmieszczenie kluczy przy użyciu każdej z instancji nadrzędnych. Rozwiązaniem automatycznym i transparentnym dla aplikacji może być wykorzystanie specjalnego proxy, które będzie zajmowało się odpowiednim rozmieszczaniem kluczy pomiędzy instancjami (o tym jednak wspomnę w ostatniej części).
Innym rozwiązaniem jest tryb klastra (Redis Cluster), czyli rozproszony system partycjonowania oparty na zasadzie, że każda instancja przechowuje tylko część danych, które są dzielone między instancjami Master i rozrzucone między wszystkie węzły klastra. W tym trybie Redis może replikować dane asynchronicznie oraz synchronicznie. Dokładne informacje o obu typach replikacji znajdziesz w oficjalnej dokumentacji Redis cluster tutorial natomiast typowo o klastrze poczytasz w bardzo dobrym artykule pod tytułem First Step to Redis Cluster. Co bardzo istotne, dokumentacja zaleca wdrożenie klastra składającego się z co najmniej 6 odseparowanych od siebie węzłów — 3x Master i 3x Slave, gdzie każdy mistrz ma pod sobą jeden węzeł podrzędny. Jeżeli masz ograniczone zasoby, możesz umieścić jedną instancję Master i Slave na tym samym serwerze lub wykorzystać replikację krzyżową (ang. cross-replication).
W tym artykule nie będziemy zajmować się usługą klastra, jednak chciałbym trochę o niej opowiedzieć. Co ważne podkreślenia, klaster Redis jest rozwiązaniem z wieloma modułami zapisującymi i ma zupełnie inną architekturę, która ma zapewnić odpowiednią wydajność przy zwiększającym się obciążeniu dzięki skalowalności poziomej (ang. horizontal scaling). Przypadki użycia klastra ewoluują w kierunku rozkładania obciążenia (w szczególności zapisów) i wyeliminowania limitów pamięci dla pojedynczej instancji. Natomiast zapewnienie wysokiej dostępności nie było priorytetem podczas projektowania (jest systemem nastawionym raczej na spójność niż dostępność) i jeśli Twoim celem jest tylko HA, prawdopodobnie tryb klastra nie będzie dla Ciebie odpowiedni.
Klaster Redis nie jest typowym rozwiązaniem wysokiej dostępności jednak oczywiście ją zapewnia. Na przykład gdy awarii ulegnie jeden z serwerów nadrzędnych jedna z instancji podrzędnych zostanie automatycznie awansowana do roli Master.
Klaster to rozwiązanie działające na fragmentach danych a każdy fragment jest dystrybuowany między węzłami nadrzędnymi i podrzędnymi. Wynika z tego fakt, że klaster jest miejscem, w którym znaczenie kluczy jest szczególnie ważne i nabiera szerszego znaczenia. Co to oznacza? W Redisie dane znajdują się w jednym miejscu w klastrze, a każdy węzeł lub fragment ma jedynie część klucza. Klaster jest podzielony na 16384 gniazda (ang. slots), które są miejscem przechowywania kluczy (są mapowane do różnych węzłów w klastrze) lub mówiąc dokładniej ich skrótów (ang. hash) — czyli klucz jest poddawany funkcji mieszającej, aby uzyskać jego matematyczną reprezentację. Z racji tego, że większość klastrów składa się z dużo mniejszej liczby węzłów, te sloty skrótów są logicznymi podziałami kluczy.
Tak więc Redis ma 16384 części, które są mapowane na dostępne maszyny fizyczne w klastrze, a takie mapowanie może wyglądać na przykład tak:
- węzeł A przechowuje sloty od 0 do 4095
- węzeł B przechowuje sloty od 4096 do 8191
- węzeł C przechowuje sloty od 8192 do 12287
- węzeł D przechowuje sloty od 12288 do 16384
Widzimy, że każdy węzeł w klastrze jest odpowiedzialny za podzbiór gniazd. Na przykład, jeśli masz klucz, o którym wiesz, że znajduje się w gnieździe 2000, to wiesz, że dane znajdują się w węźle A. Jeśli klucz znajduje się w gnieździe 9000, to wiesz, że znajduje się w węźle C. W rzeczywistości jest to o wiele bardziej złożone, ale w celu zrozumienia idei wystarczy to uproszczone koncepcyjne rozumowanie.
Tak więc gdy Redis otrzymuje klucz, wykonuje następujące czynności:
- oblicza skrót klucza za pomocą funkcji
hash(key) - oblicza lokalizację klucza wykonując resztę z dzielenia skrótu przez ilość wszystkich slotów (czyli przez 16384), dzięki czemu jest w stanie znaleźć konkretny fragment logiczny, do którego należy dany klucz
- w wyniku obliczeniu skrótu, fragment logiczny mapowany jest na fizyczną instancję, w celu jego zidentyfikowania
Więcej na ten temat napisano w świetnym artykule pod tytułem Redis Clustering Best Practices with Keys dlatego bardzo zachęcam do jego przeczytania.
Co niezwykle ważne, w przypadku minimalnej konfiguracji klastra, będą wymagane trzy serwery nadrzędne, jednak aby zapewnić pełnoprawny klaster i jego odpowiednią dostępność, zalecane jest wykorzystanie klastra z sześcioma węzłami, tj. trzema nadrzędnymi i trzema podrzędnymi. Na przykład jeśli klaster składa się z węzłów A, B, C, które są węzłami nadrzędnymi, oraz A1, B1, C1, które są węzłami podrzędnymi i działają na tych samych serwerach (jeden z mistrzów i podwładnych na tej samej maszynie), system może kontynuować pracę, jeśli np. węzeł B ulegnie awarii. Przy wszystkich działających węzłach, B1 replikuje dane z węzła B, jednak jeśli B ulegnie awarii, klaster wypromuje węzeł B1 do nowego mistrza i będzie nadal działał poprawnie. Jeśli jednak węzły B i B1 ulegną awarii w tym samym czasie, klaster nie będzie mógł dalej działać.
Widzimy, że jeśli masz trzy węzły główne z jedną instancją podrzędną dla każdego mistrza uruchomione na tym samym serwerze, możesz stracić tylko jeden z serwerów, ponieważ aby nastąpiło przełączenie awaryjne, klaster musi mieć dostępną większość wzorców — wszystko po to, by po awarii jednego z serwerów głównych pozostały jeszcze 2/3 działających instancji. Jeśli jednak stracisz dwóch ze swoich trzech mistrzów w tym samym czasie, nie nastąpi przełączenie awaryjne, ponieważ większość z nich nie będzie online. Zapytania będą otrzymywały błąd CLUSTERDOWN, dopóki większość z instancji nadrzędnych nie będzie dostępna.
Dobrze, a które z rozwiązań jest lepsze? Oczywiście to zależy od konkretnego przypadku i jest bardzo mocno związane z samą aplikacją, wymaganiami, jakie się przed nią stawia, ale także od środowiska i dostępności zasobów. Jeśli Twoim celem jest głównie zapewnienie HA, prawdopodobnie użycia klastra nie będzie odpowiednie, tutaj idealna będzie replikacja Master-Slave. Jednak zapewnienie HA w przypadku takiej konfiguracji wymaga większej ilości elementów, tj. serwera głównego, serwerów podrzędnych czy Redis Sentinela (oczywiście oba tryby do pełnego i stabilnego działania wymagają odpowiedniej ilości mistrzów, podwładnych czy wartowników w przypadku replikacji Master-Slave).
Natomiast jednym z kluczowych czynników podczas projektowania środowiska wykorzystującego usługę Redis, są zasoby (sprzęt, wirtualizacja), które mają wpływ na późniejsze działanie systemu i jego mechanizmów takich jak HA czy auto-failover. Pamiętajmy, że tryb klastra pozwala na uruchomienie, mając jedynie trzy serwery nadrzędne, jednak zgodnie z zaleceniami, wymaga co najmniej sześciu odseparowanych od siebie węzłów. Natomiast tryb replikacji Master-Slave pozwala na w pełni działające wdrożenie przy jednym mistrzu i replice oraz minimum trzech węzłach Sentinel gdzie każda z usług powinna być także od siebie odseparowana. Jeżeli chodzi o wydajności i możliwości zapisów i odczytów, to jeżeli zależy Ci na lepszym skalowaniu tych pierwszych, tutaj odpowiedni będzie tryb klastra, podczas gdy replikacja Master-Slave sprawdzi się lepiej w przypadku skalowania tych drugich.
Wykorzystanie konkretnego trybu pracy determinuje także obsługę po stronie klienta. W przypadku replikacji Master-Slave sprawa jest dosyć prosta, ponieważ klient puka zawsze do mistrza i ew. do serwerów podrzędnych w przypadku odczytów. Automatyczne wykrywanie mistrza rozwiązywane jest natomiast za pomocą np. HAProxy. Uruchomienie trybu klastra delikatnie komplikuje sprawę, ponieważ klienci powinni mieć bezpośrednie połączenie ze wszystkimi węzłami nadrzędnymi i podrzędnymi. Dzieje się tak, ponieważ dane są dzielone między węzłami i w przypadku, kiedy klient próbuje zapisać dane do instancji M1 (Master), gdy M2 (Master) jest właścicielem danych, M1 zwróci klientowi komunikat
MOVE, kierując go do wysłania żądania do M2.
Oczywiście oba rozwiązania są używane do zapewnienia wysokiej dostępności, tylko robią to na dwa różne sposoby (określają różne przypadki partycjonowanego lub niepartycjonowanego mistrza). Klaster Redis ma jednak pewne ograniczenia, zwłaszcza dotyczące operacji z wieloma kluczami, więc niekoniecznie jest to proste rozwiązanie. Umożliwia jednak skalowanie w poziomie i może pomóc w obsłudze dużych obciążeń, ponieważ jednym z głównych celów tego trybu jest równomierne rozkładanie obciążeń głównie przez fragmentowanie i możliwość zapisów do wielu węzłów. Moim zdaniem użycie replikacji w połączeniu z usługą Redis Sentinel jest mniej kosztowne, prostsze w konfiguracji i zarządzaniu oraz w większości przypadków jest trybem pracy, który spełnia większość wymagań. Co niezwykle istotne, w przypadku działania tylko jednej repliki, jesteśmy w stanie awansować ją do roli mistrza i wznowić działanie aplikacji. Natomiast do przywrócenia pracy klastra zawsze potrzebna jest działająca większość.
Nie można zapomnieć, że wybór między tymi dwoma trybami pracy powinien być także oparty na oczekiwanym obciążeniu. Jeśli obciążeniem zapisu można zarządzać za pomocą jednego węzła głównego, możesz spokojnie przeprowadzić wdrożenie replikacji Master-Slave wykorzystując dodatkowo Redis Sentinele. Jeśli jeden węzeł nie może obsłużyć oczekiwanego obciążenia związanego z zapisami, musisz przejść do wdrożenia klastra. Oczywiście w przypadku projektowania replikacji Master-Slave lub klastra należy zawsze przetestować wdrożoną konfigurację (także na produkcji!), aby zweryfikować, jak się zachowuje, poznać jej słabe punkty i przygotować środki zaradcze na wypadek awarii.
Znaczenie replikacji #
Replikacja jest najczęściej wykorzystywana w systemach rozproszonych, gdzie dane z jednego zdalnego węzła są kopiowane do innych zdalnych węzłów w celu zapewnienia niezawodności i wydajności systemu. Główną jej zaletą jest to, że dane we wszystkich lokalizacjach będą stale aktualne oraz spójne (lub w miarę aktualne i w miarę spójne). Natomiast głównym jej celem jest skrócenie czasu dostępu do danych oraz uniezależnienie się od czasowej niedostępności serwerów i awarii. Oczywiście w celu zapewnienia replikacji konieczne jest ciągłe aktualizowanie replik w przypadku zmian danych źródłowych.
W przypadku Redisa, w obu trybach używana jest replikacja asynchroniczna, która wprowadza małe opóźnienia, jednak zapewnia wysoką wydajność i jest naturalnym trybem replikacji dla większości przypadków użycia. Co więcej, ten typ replikacji jest znacznie szybszy, zarówno pod względem przepustowości, jak i opóźnień klienta. Ciekawostką jest to, że w przypadku Redisa to repliki potwierdzają dane, które otrzymały (asynchronicznie) z instancją główną, a nie na odwrót. Dzięki takiemu rozwiązaniu Master nigdy nie czeka ani na potwierdzenia, ani na przetworzenie instrukcji przez repliki.
Ma to ogromny wpływ na wydajność serwera nadrzędnego, który (tak naprawdę niezależnie od trybu pracy) w Redisie nie jest blokowany przez replikację. Oznacza to, że Master będzie nadal obsługiwał zapytania, gdy co najmniej jedna replika wykonuje początkową synchronizację lub częściową ponowną synchronizację. Replikacja jest również w dużej mierze nieblokująca po stronie serwerów podrzędnych. Podczas gdy replika wykonuje początkową synchronizację, może obsługiwać zapytania przy użyciu starej wersji zestawu danych, zakładając, że została odpowiednio skonfigurowana (jednak po początkowej synchronizacji stary zestaw danych musi zostać usunięty, a nowy musi zostać załadowany).
Co niezwykle ważne, dzięki replikacji jesteśmy w stanie zapewnić dwie istotne rzeczy:
-
skalowalność, dzięki której możemy rozszerzać system bez ponoszenia dużych nakładów, czyli dodawać lub usuwać węzły nie zaburzając działania całego systemu
-
redundancję, dzięki której w przypadku niedostępności serwera głównego, jeden z pozostałych automatycznie i prawie niezauważalnie przejmuje jego funkcje
Jeżeli chodzi o skalowalność, to możemy ją podzielić na dwa rodzaje: skalowalność zapisów i odczytów. Pierwszy rodzaj jest zapewniany jedynie w trybie klastra, ponieważ w tym przypadku można dodawać kolejne węzły nadrzędne, tak aby nowe z nich przejmowały część obciążenia. Wykorzystanie replikacji Master-Slave w połączeniu z usługą Sentinel nie zapewnia skalowalności zapisów, ponieważ węzeł główny jest jedynym węzłem, który może zapisywać dane, przez co dodanie większej ilości replik nie poprawi ani wydajności, ani lepszego rozkładania obciążenia.
Jeśli chodzi o skalowalność odczytów, to jest ona zapewniana w jednym jak i drugim trybie. Dodanie instancji podrzędnych może znacznie poprawić wydajność odczytu (w przypadku kierowania takich żądań do nich), dzięki czemu takie zapytania można przekazać do dowolnej instancji w tym do instancji podrzędnych. Oczywiście operacje zapisu kierowane będą tylko do serwera lub serwerów nadrzędnych niezależnie od trybu pracy. Sentinel w tym przypadku zapewni jedynie dwa mechanizmy: wykrywanie awarii węzła głównego i awansowanie jednej z instancji podrzędnych do stanu Master.
Pamiętaj, że jeśli czytasz dane z instancji podrzędnej, a następnie zapisujesz je w węźle głównym, możesz nieumyślnie zniszczyć zapisy, które zakończyły się, ale nie zostały jeszcze zreplikowane do replik.
Zwróć również uwagę, że kolokowanie aplikacji i Redisa na tym samym serwerze powoduje niemal pewne problemy ze skalowalnością. Co się stanie, gdy będziesz potrzebować więcej zasobów obliczeniowych dla swoich aplikacji i nowym wymaganiem będzie dostawienie kolejnych instancji? Jest to kolejny powód za oddzieleniem Redisa od aplikacji i umieszczenie go na odseparowanych zasobach. Minusem może być zwiększone zapotrzebowanie na sieć, z drugiej strony pozwala to na większą elastyczność i kontrolę nad znacznie prostszą konfiguracją.
Biorąc natomiast pod uwagę replikację Master-Slave, która jest jednym z głównych tematów tej serii artykułów, to uruchomienie jej w skalowanym środowisku wymaga:
- wielu instancji Redis uruchomionych w topologii Master-Slave
- wielu instancji Sentinel przy zachowaniu minimalnej ilości równej trzy
- wsparcia po stronie aplikacji
- widoczności wszystkich instancji Redis oraz Sentinel i pełnej komunikacji między nimi
Jeżeli chodzi o redundancję, to jest ona ściśle związana z przełączaniem awaryjnym, które pozwala wykrywać awarie i automatycznie przełączać instancje między sobą (pamiętajmy jednak, że z racji replikacji asynchronicznej, nie wszystkie zmiany mogą zostać przesłane odpowiednio szybko do serwerów podrzędnych). Dzięki redundancji jesteśmy w stanie utrzymać instancje w trybie online przy minimalnych lub zerowych przestojach co jest niezwykle istotne w środowiskach o niskim SLA.
Kompilacja ze źródeł #
W tym rozdziale chciałbym przeprowadzić Cię przez proces kompilacji Redisa, ponieważ wiem, że taki sposób instalacji jest dosyć często stosowany. Poza tym nie znalazłem jednego działającego przepisu, który pozwalałby skompilować to oprogramowanie bezproblemowo. Jeżeli chodzi o opcje kompilacji i związane z nią optymalizacje (w tym wydajności), to zerknij do artykułu Redis Benchmarks with Optimizations.
Co w ogóle daje nam kompilacja ze źródeł? Dzięki skompilowanej wersji Redisa mamy możliwość posiadania jego najbardziej aktualnej wersji dostosowanej do konkretnej maszyny i pozbawionej niepotrzebnych opcji (oczywiście jeśli zajdzie potrzeba optymalizacji) lub dostrojonej do wymagań i potrzeb danego projektu. Oczywiście z drugiej strony ogromną zaletą pakietów binarnych jest to, że są one przygotowywane przez osoby naprawdę znające się na rzeczy, są gotowe do zainstalowania najczęściej przy pomocy menadżera pakietów i generalnie najczęściej wykorzystywane.
Kompilacja Redisa i wszystkich wymaganych narzędzi, które dostarczone są w źródłach, jest dosyć prosta, jednak różni się trochę od standardowej kompilacji złożonej z poleceń configure, make i make install. Przed rozpoczęciem zerknij do pliku README.md, w którym cały proces został bardzo dokładnie opisany.
Przejdźmy od razu do szczegółów i w pierwszej kolejności pobierzmy źródła:
git clone https://github.com/redis/redis
Następnie należy zainstalować dodatkowe zależności, które są wymagane do przeprowadzenia kompilacji:
yum install tcl gcc make jemalloc-devel lua-devel
Kiedy aktualizujesz kod źródłowy za pomocą git pull lub gdy kod wewnątrz drzewa zależności jest modyfikowany w jakikolwiek inny sposób, wykonaj poniższe polecenie, aby wyczyścić wszystko (w tym dane konfiguracyjne) i odbudować źródła do postaci początkowej:
cd redis
make distclean
Kolejny niezwykle ważny krok, to rozwiązanie lokalnych zależności:
cd deps
make lua hiredis linenoise
make jemalloc
# Jeżeli pojawią się błędy, wykonaj ten proces ponownie ale w innej kolejności:
make hiredis lua jemalloc linenoise
Teraz możemy przejść do kompilacji Redisa:
cd ..
make
# Alternatywa (jednak powyższa komenda wykona to za Ciebie):
cd ../src
make all
Skompilowane binarki znajdują się w katalogu redis/src. Można przetestować czy Redis i Redis Sentinel działają:
cd src
./redis-server --port 6379 /etc/redis/redis.conf --loglevel debug
./redis-sentinel --port 26379 /etc/redis/redis-sentinel.conf
Zarządzanie i wersja Redisa #
Redis dostarcza kilka ciekawych narzędzi pomocnych w zarządzaniu uruchomionymi instancjami oraz zestawionym klastrem. Większość z nich znajduje się w katalogu utils źródła projektu:
cd redis/utils
tree -L 1
.
├── build-static-symbols.tcl
├── cluster_fail_time.tcl
├── corrupt_rdb.c
├── create-cluster
├── generate-command-help.rb
├── gen-test-certs.sh
├── graphs
├── hashtable
├── hyperloglog
├── install_server.sh
├── lru
├── redis-copy.rb
├── redis_init_script
├── redis_init_script.tpl
├── redis-sha1.rb
├── releasetools
├── speed-regression.tcl
├── srandmember
├── systemd-redis_multiple_servers@.service
├── systemd-redis_server.service
├── tracking_collisions.c
└── whatisdoing.sh
Jeżeli chodzi o wersję, to wykorzystałem Redisa w wersji 5, który został zainstalowany z repozytorium Software Collections (SCL) w systemie CentOS 7.7.1908. O wersji Redisa wspominam nie bez powodu, ponieważ w zależności, na jaką się zdecydujemy i jaką metodę instalacji wybierzemy, zmienią się m.in. ścieżki do plików konfiguracyjnych oraz sposób uruchamiania konsoli (przykłady zostały przedstawione w następnym podrozdziale).
W tym artykule w każdym przykładzie wykorzystane zostaną krótsze wersje poleceń, aby zrozumienie niektórych kwestii było łatwiejsze, natomiast jeżeli zajdzie konieczność odwołania się do innej wersji, jasno o tym wspomnę. Należy tym samym pamiętać, aby dostosować niektóre polecenia w zależności od wykorzystywanej wersji.
Konsola #
Redis zapewnia interfejs wiersza poleceń, z którego poziomu jesteśmy w stanie kontrolować daną instancję w czasie rzeczywistym i w zależności od potrzeby modyfikować jej parametry. Dokładny opis wszystkich poleceń znajdziesz w rozdziale Redis Commands oficjalnej dokumentacji. W tym paragrafie zostaną omówione jedynie najważniejsze z poleceń.
Aby podłączyć się do konsoli, wydajemy polecenie:
# Bez uwierzytelniania:
redis-cli -h 127.0.0.1 -p 6379
# Z włączonym uwierzytelnianiem:
redis-cli -a $(grep "^requirepass" /etc/redis.conf | awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 6379
Po poprawnym podłączeniu możesz sprawdzić, czy dany węzeł działa:
127.0.0.1:6379> PING
PONG
Konsola zapewnia dosyć przystępną pomoc:
127.0.0.1:6379> HELP
redis-cli 5.0.5
To get help about Redis commands type:
"help @<group>" to get a list of commands in <group>
"help <command>" for help on <command>
"help <tab>" to get a list of possible help topics
"quit" to exit
To set redis-cli preferences:
":set hints" enable online hints
":set nohints" disable online hints
Set your preferences in ~/.redisclirc
127.0.0.1:6379> HELP ping
PING [message]
summary: Ping the server
since: 1.0.0
group: connection
Wartości parametrów konfiguracyjnych sprawdzamy za pomocą:
127.0.0.1:6379> CONFIG get <key>
Natomiast ustawiamy je za pomocą:
127.0.0.1:6379> CONFIG set <key> <value>
Jeśli chodzi o opcje konfiguracyjne, to po każdej zmianie są one ustawiane (zmieniane) jedynie w pamięci. By zapisać je do pliku redis.conf, należy wykonać:
127.0.0.1:6379> CONFIG rewrite
OK
W przypadku uruchomionego SELinuxa nie uda się zapisać konfiguracji i na wyjściu zostanie zwrócony błąd:
127.0.0.1:6379> CONFIG rewrite
(error) ERR Rewriting config file: Permission denied
Aby rozwiązać ten problem, należy wykonać poniższe kroki:
mkdir /etc/redis/selinux
cd /etc/redis/selinux
# Wygenerować moduł:
ausearch -m avc -c redis | audit2allow -a -M redis-conf
# Podgląd zawartości:
cat redis-conf.te
module redis-conf 1.0;
require {
type etc_t;
type redis_t;
class file write;
}
#============= redis_t ==============
#!!!! WARNING: 'etc_t' is a base type.
allow redis_t etc_t:file write;
# Załadować moduł
semodule -i redis-conf.pp
Jednym z najczęstszych poleceń, z jakich będziesz korzystał, jest polecenie INFO. Zwraca ono informacje i statystyki dotyczące danej instancji Redis:
127.0.0.1:6379> INFO
Opcjonalnego parametru można użyć do wybrania określonej sekcji informacji:
127.0.0.1:6379> INFO stats
# Stats
total_connections_received:37126961
total_commands_processed:303336127
instantaneous_ops_per_sec:8
total_net_input_bytes:53799070421
total_net_output_bytes:55871322834
instantaneous_input_kbps:4.92
instantaneous_output_kbps:2.31
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:0
evicted_keys:0
keyspace_hits:105
keyspace_misses:6
pubsub_channels:1
pubsub_patterns:0
latest_fork_usec:15622
migrate_cached_sockets:0
Powiedzieliśmy na wstępie, że Redis jest bazą typu klucz-wartość. Tworzenie i usuwanie kluczy jest niezwykle proste i sprowadza się do wykonania:
# Tworzy klucz:
127.0.0.1:6379> SET foo bar
OK
# Usuwa klucz:
127.0.0.1:6379> DEL foo
(integer) 1
Polecenie SET jest podstawowym i najprostszym sposobem na tworzenie kluczy. Za jego pomocą tworzymy klucz do przechowywania wartości ciągu (ang. string). Redis pozwala na tworzenie wielu struktur danych, a ciągi są tylko jedną z nich. Po więcej informacji odsyłam do rozdziału Zarządzanie pamięcią tego artykułu.
Natomiast aby wyświetlić wartość klucza:
127.0.0.1:6379> GET foo
"bar"
Jeśli chcesz sprawdzić, ile jest kluczy w danej bazie:
127.0.0.1:6379> DBSIZE
(integer) 4
Możesz także wyświetlić klucze według podanego wzorca lub wszystkie, które są dostępne w danej bazie:
127.0.0.1:6379> KEYS fo*
1) "foo"
127.0.0.1:6379> KEYS *
1) "x"
2) "foo"
Pamiętaj: w dużych bazach danych i w zależności od wzorca zastosowanego w poleceniu
KEYSoperacja ta może prowadzić do długiego blokowania instancji Redis.
Istnieje też możliwość ustawienia limitu życia (w sekundach) danego klucza:
127.0.0.1:6379> SET foo bar
OK
127.0.0.1:6379> EXPIRE foo 20
(integer) 1
Aby podejrzeć czas, jaki pozostał do wygaśnięcia:
127.0.0.1:6379> TTL foo
(integer) 18
Oczywiście istnieje możliwość usunięcia wszystkich kluczy oraz wykonanie tej operacji tylko na konkretnej bazie:
127.0.0.1:6379> FLUSHALL
OK
127.0.0.1:6379[10]> FLUSHDB
OK
Możesz teraz zadać pytanie: a co, jeśli chcielibyśmy wykonać kilka poleceń albo utworzyć 10000 kluczy naraz? Musimy wykonywać je jedno po drugim lub 10000 razy wywołać odpowiednią komendę? No właśnie, wysyłanie wielu poleceń w takiej formie może zająć bardzo, ale to bardzo dużo czasu i może zablokować na jakiś czas główny proces, co jest chyba największym problemem. Redis zapewnia jednak przynajmniej dwa sposoby na przyspieszenie takich czynności (oba są formą grupowania poleceń):
- agregacja za pomocą komend
MSETiMGET - wykonanie za pomocą potoków
PIPELINE
Te polecenia istnieją w celu usprawnienia wykonania wielu operacji i potrafią znacznie zmniejszyć czas ich przetworzenia. Ogromną zaletą potoków jest to, że nie blokują one innych poleceń oraz klientów i są przede wszystkim pewną formą optymalizacji sieci, ponieważ ich użycie oznacza, że klient buforuje kilka poleceń i wysyła je do serwera „w jednej paczce”, oszczędzając czas przesyłania. Jednym ze sposobów zrozumienia potoku jest zrozumienie faktu, że jest on w całości implementacją po stronie klienta, a serwer Redis nie ma z tym tak naprawdę nic wspólnego. Przy wykorzystaniu potoków, serwer jest w stanie przetwarzać nowe żądania, nawet jeśli klient nie przeczytał jeszcze starych odpowiedzi. W ten sposób możliwe jest wysłanie wielu poleceń do serwera bez czekania na potwierdzenie odpowiedzi, które mogą zostać odczytane w jednym kroku i to na samym końcu.
Zastosowanie pipeliningu pozwala natychmiastowo przesłać żądania, eliminując większość opóźnień i pomaga również zmniejszyć fragmentację pakietów. Na przykład 100 żądań wysłanych indywidualnie (oczekujących na każdą odpowiedź) będzie wymagało co najmniej 100 pakietów, ale 100 żądań wysłanych potokiem może zmieścić się w znacznie mniejszej liczbie pakietów.
W przypadku GET, MGET, SET lub MSET każde pojedyncze polecenie będzie blokowane do momentu zakończenia (głównie z racji tego, że Redis jest aplikacją jednowątkową), co może opóźnić wykonanie innych istotnych poleceń. Co ważne, standardowo pojedyncze polecenia od różnych klientów będą wykonane kolejno jedno po drugim, jednak w przypadku multiwykonania za pomocą MGET lub MSET inni klienci nie będą w stanie wykonać poleceń między tymi poleceniami, do momentu aż nie zostaną one zakończone.
Oto przykłady. Jeśli chcesz utworzyć wiele kluczy, wykorzystując komendę MSET:
127.0.0.1:6379> MSET foo bar x z
OK
Natomiast aby je odczytać, wykorzystując komendę MGET:
127.0.0.1:6379> MGET foo x
1) "bar"
2) "z"
Poniżej znajduje się przyład wykorzystania potoku za pomocą narzędzia netcat:
(printf "PING\r\nPING\r\nPING\r\n"; sleep 1) | nc localhost 6379
+PONG
+PONG
+PONG
Świetne wyjaśnienie potoków znajdziesz we wpisie Beating Round-Trip Latency With Redis Pipelining oraz Using pipelining to speedup Redis queries oficjalnej dokumentacji. Natomiast co nieco o MGET i MSET poczytasz we wpisie Benchmarking Redis. W przypadku masowego dodawania kluczy koniecznie zerknij do oficjalnej dokumentacji i rozdziału Redis Mass Insertion, a także przeczytaj rozdział 4.5 Non-transactional pipelines książki Redis in Action.
Zatrzymajmy się teraz na chwilę, ponieważ muszę wspomnieć o dwóch niezwykle ważnych kwestiach. Redis obsługuje coś takiego jak transakcje, które w żaden sposób nie przypominają transakcji znanych z baz danych SQL. Transakcje w Redisie składają się z bloku poleceń umieszczonych między komendami MULTI i EXEC (lub DISCARD w przypadku ich wycofania). Po napotkaniu komendy MULTI, polecenia nie są wykonywane a jedynie umieszczane w kolejce. Po napotkaniu EXEC wszystkie są stosowane w jednej jednostce (tj. bez innych połączeń uzyskujących czas między operacjami). Ponieważ polecenia wewnątrz transakcji są umieszczane w kolejce, nie można podejmować decyzji w ramach transakcji.
Wykonanie transakcji może wyglądać tak:
127.0.0.1:6379> MULTI
127.0.0.1:6379> SET foo 1
127.0.0.1:6379> INCR foo
127.0.0.1:6379> INCRBY foo 10
127.0.0.1:6379> GET foo
127.0.0.1:6379> EXEC
Polecenie MULTI informuje o rozpoczęciu bloku transakcji, a wszelkie kolejne polecenia będą umieszczane w kolejce, dopóki nie zostanie uruchomione polecenie EXEC, które je wykona. Pierwsza komenda inicjuje transakcję, druga ustawia klucz trzymający łańcuch o wartości 1, trzecia zwiększa wartość o 1, czwarta zwiększa jej wartość o 10, piąta zwraca aktualną wartość ciągu, a ostatnia odpowiada za wykonanie bloku transakcji.
Jeżeli chodzi o polecenie EXEC, to wyzwala ono wykonanie wszystkich poleceń w transakcji, więc jeśli klient utraci połączenie z serwerem w kontekście transakcji przed wywołaniem tego polecenia, żadna z operacji nie zostanie wykonana. Co również ważne, wykorzystując opcję zapisu na dysk, Redis użyje pojedynczego wywołania do zapisania transakcji do pliku. Jeśli jednak proces ulegnie awarii lub zostanie w jakiś sposób zatrzymany, możliwe jest, że zarejestrowana zostanie tylko część operacji w kontekście danej transakcji. Redis wykryje ten stan przy ponownym uruchomieniu i zakończy pracę z błędem, uniemożliwiając uruchamianie swojego procesu, ponieważ nie będzie on mógł załadować danych z pliku. Rozwiązaniem tego jest wykorzystanie narzędzia redis-check-aof, które usunie częściową transakcję, aby serwer mógł się ponownie uruchomić.
Wszystkie polecenia w transakcji są serializowane i wykonywane sekwencyjnie. Nigdy nie może się zdarzyć, że żądanie wysłane przez innego klienta zostanie obsłużone w trakcie wykonywania transakcji. Gwarantuje to, że polecenia są wykonywane jako pojedyncza izolowana operacja. Co niezwykle istotne, transakcje w Redisie są niepodzielne lub mówiąc inaczej atomowe (ang. atomic), co oznacza, że albo każde polecenie w bloku transakcji jest przetwarzane (akceptowane jako prawidłowe i umieszczane w kolejce do wykonania) albo nie jest wykonywane żadne z nich. Jeśli polecenie zostanie pomyślnie umieszczone w kolejce, to nadal może powodować błąd podczas wykonywania. W takich przypadkach inne polecenia w transakcji mogą nadal działać, a Redis po prostu pominie polecenie, które spowodowało błąd.
Możesz teraz pomyśleć, że transakcje są bardzo podobne do potoków, ponieważ także pozwalają na grupowanie poleceń. Pamiętaj jednak, że potoki to przede wszystkim optymalizacja sieci i oznaczają, że klient buforuje kilka poleceń i wysyła je na serwer za jednym razem. Nie ma jednak gwarancji, że polecenia zostaną wykonane, a zaletą w tym przypadku jest oszczędność czasu podróży w obie strony. Transakcje natomiast zapewniają, że żaden inny klient nie wykonuje poleceń pomiędzy poleceniami w sekwencji MULTI/EXEC. Krótko mówiąc, po wykonaniu sekwencja poleceń transakcji musi wystąpić w całości lub nic się nie stanie. Ponadto, inne transakcje nie będą z nią kolidować, gdy zostanie uruchomiona. Mając to na uwadze, użycie transakcji w Redisie może być kluczem do usprawnienia obciążenia oraz pozwala zapobiec uszkodzeniu danych. To tyle o transakcjach. Przy okazji polecam przeczytać ciekawy artykuł You Don’t Need Transaction Rollbacks in Redis.
Wróćmy do konsoli i opisywanych poleceń. Istnieją jeszcze trzy niezwykle ważne komendy, które pozwalają zarządzać podłączonymi klientami, analizować statusy połączenia i replikacji, a także debugować występujące problemy. Pierwszym z nich jest komenda CLIENT:
127.0.0.1:6379> CLIENT help
1) CLIENT <subcommand> arg arg ... arg. Subcommands are:
2) id -- Return the ID of the current connection.
3) getname -- Return the name of the current connection.
4) kill <ip:port> -- Kill connection made from <ip:port>.
5) kill <option> <value> [option value ...] -- Kill connections. Options are:
6) addr <ip:port> -- Kill connection made from <ip:port>
7) type (normal|master|replica|pubsub) -- Kill connections by type.
8) skipme (yes|no) -- Skip killing current connection (default: yes).
9) list [options ...] -- Return information about client connections. Options:
10) type (normal|master|replica|pubsub) -- Return clients of specified type.
11) pause <timeout> -- Suspend all Redis clients for <timout> milliseconds.
12) reply (on|off|skip) -- Control the replies sent to the current connection.
13) setname <name> -- Assign the name <name> to the current connection.
14) unblock <clientid> [TIMEOUT|ERROR] -- Unblock the specified blocked client.
Widzisz, że pozwala ona zarządzać wszystkimi podpiętymi klientami do instancji, na której wywołano to polecenie. Jednym z najczęściej przeze mnie wykorzystywanych jest komenda CLIENT list, która zwraca status i parametry wszystkich klientów:
127.0.0.1:6379> CLIENT list
id=3042 addr=192.168.10.20:47538 fd=9 name=sentinel-ed03f0f8-pubsub age=69128 idle=0 flags=P db=0 sub=1 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=subscribe
id=3039 addr=192.168.10.30:51809 fd=13 name=sentinel-59b4bc00-pubsub age=69129 idle=0 flags=P db=0 sub=1 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=subscribe
id=3054 addr=192.168.10.20:6379 fd=14 name= age=69118 idle=0 flags=M db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=publish
id=3036 addr=192.168.10.10:43740 fd=10 name=sentinel-9de6b932-cmd age=69129 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=publish
id=3037 addr=192.168.10.10:53360 fd=11 name=sentinel-9de6b932-pubsub age=69129 idle=0 flags=P db=0 sub=1 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=subscribe
id=3052 addr=192.168.10.30:53968 fd=8 name=sentinel-59b4bc00-cmd age=69119 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=publish
id=11288 addr=127.0.0.1:43234 fd=15 name= age=228 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=26 qbuf-free=32742 obl=0 oll=0 omem=0 events=r cmd=client
id=3053 addr=192.168.10.20:57263 fd=12 name=sentinel-ed03f0f8-cmd age=69119 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=ping
Natomiast drugim komenda MONITOR, która wyświetla wszystko to, co dzieje się aktualnie w środowisku (przesyła strumieniowo wszystkie polecenia przetwarzane przez proces), na których działają węzły Redis:
127.0.0.1:6379> MONITOR
OK
1600927132.287841 [0 192.168.10.20:38831] "INFO"
1600927132.287905 [0 192.168.10.20:38831] "PING"
1600927132.478911 [0 192.168.10.30:52278] "INFO"
1600927132.479005 [0 192.168.10.30:52278] "PING"
1600927144.922003 [0 127.0.0.1:47646] "AUTH" "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
1600927144.922321 [0 127.0.0.1:47646] "info" "replication"
1600927144.931165 [0 127.0.0.1:47648] "AUTH" "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
1600927144.931465 [0 127.0.0.1:47648] "info" "replication"
1600927144.941100 [0 127.0.0.1:47650] "AUTH" "meiNae5Thio7shohghiovoh7AhMieng3feex7feiraiQuoh2"
1600927144.941373 [0 127.0.0.1:47650] "info" "replication"
[...]
Wyświetlane kolumny oznaczają:
1600927132.287841- znacznik czasu0- identyfikator bazy danych192.168.10.20:38831- adres IP i numer portu klienta"info" "replication"- wykonaną komendę
W przypadku tego polecenia uruchomienie jednego klienta w tym trybie może zmniejszyć przepustowość o ponad 50%, zaś uruchomienie kolejnych klientów zmniejsza ją jeszcze bardziej.
Trzecie z poleceń pozwala podejrzeć status danej instancji oraz wszystkie kluczowe parametry odpowiedzialne za replikację i będzie to chyba najczęściej wykorzystywane przez nas polecenie (wywoływane m.in. jako alias redis.stats):
127.0.0.1:6379> INFO replication
# Replication
role:slave
master_host:192.168.10.20
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_repl_offset:21156540
slave_priority:1
slave_read_only:1
connected_slaves:0
master_replid:7060b6ced48fa590e885b373f638a97115d59487
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:21156540
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:20107965
repl_backlog_histlen:1048576
Poniżej znajduje się lista poleceń, które są niezwykle przydatne podczas pracy z Redisem i rozwiązywania problemów. Część z nich zostanie omówiona w następnych wpisach, jednak dla większej przejrzystości wymienię je już teraz:
INFOINFO commandstatsINFO replicationINFO memoryINFO persistence
MONITORMEMORYMEMORY statsMEMORY usage <key>MEMORY malloc-stats
MEMORY DOCTORLATENCY DOCTORDEBUG OBJECTDEBUG htstats <db_id>SUBSCRIBECLIENT LISTredis-cli --intrinsic-latency 100redis-cli --latencyredis-cli --bigkeysredis-benchmark -q -n 100000redis-benchmark -t set,lpush -n 100000 -qredis-benchmark -t set -r 100000 -n 1000000redis-benchmark -n 1000000 -t set,get -P 16 -qredis-benchmark -n 100000 -q script load "redis.call('set','foo','bar')"
W przypadku problemów z Redisem koniecznie zerknij do oficjalnej dokumentacji oraz poniższych artykułów:
- Redis debugging guide
- Redis performance debugging
- Debugging Redis Keyspace Misses
- Redis Lua scripts debugger
- 7 Methods For Tracing and Debugging Redis Lua Scripts
- Redis Pub/Sub: Howto Guide
Aliasy i skrypty #
Praca z Redisem jest naprawdę przyjemna, ponieważ odpowiednio skonfigurowany w większości przypadków działa bezproblemowo. Jednak w przypadku problemów czy awarii warto mieć pod ręką polecenia lub skrypty przydatne podczas debugowania i wspomagające zarządzanie.
Poniżej znajduje się zestaw aliasów przygotowany pod odpowiednie wersje Redisa (dodajemy je np. do ~/.bashrc), które mają pomóc zarządzać pojedynczymi instancjami jak i całym stackiem:
- Redis 3.2.12:
alias CD_REDIS="cd /etc/"
alias CD_REDIS_LOG="cd /var/log/redis/"
_redis_conf="/etc/redis.conf"
_redis_bin="redis-cli --no-auth-warning"
_sentinel_conf="/etc/redis-sentinel.conf"
# alias redis.stats='while : ; do clear ; /etc/redis/redis-stats.sh ; sleep 1 ; done'
alias redis.stats='watch -n1 -d /etc/redis/redis-stats.sh'
alias redis.cli="$_redis_bin -a $(grep '^requirepass' $_redis_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 6379"
# Usage: redis.promote no one <ip> <port>
function redis.promote {
$_redis_bin -a $(grep '^requirepass' $_redis_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 6379 SLAVEOF no one $1 $2
}
# Usage: redis.demote <ip> <port>
function redis.demote {
$_redis_bin -a $(grep '^requirepass' $_redis_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 6379 REPLICAOF
}
function redis.save {
$_redis_bin -a $(grep '^requirepass' $_redis_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 6379 CONFIG REWRITE
}
alias redis.status='systemctl status redis'
alias redis.restart='systemctl restart redis'
alias redis.start='systemctl start redis'
alias redis.stop='systemctl stop redis'
function sentinel.cli {
$_redis_bin -a $(grep '^requirepass' $_sentinel_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 26379
}
# Usage: sentinel.failover <label>
function sentinel.failover {
$_redis_bin -a $(grep '^requirepass' $_sentinel_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 26379 SENTINEL failover
}
function sentinel.reset {
$_redis_bin -a $(grep '^requirepass' $_sentinel_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 26379 SENTINEL reset $1
}
function sentinel.save {
$_redis_bin -a $(grep '^requirepass' $_sentinel_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 26379 SENTINEL flushconfig
}
alias sentinel.status='systemctl status redis-sentinel'
alias sentinel.restart='systemctl restart redis-sentinel'
alias sentinel.start='systemctl start redis-sentinel'
alias sentinel.stop='systemctl stop redis-sentinel'
- Redis 3.2 (RH, SCL):
alias CD_REDIS="cd /etc/opt/rh/rh-redis32/"
alias CD_REDIS_LOG="cd /var/opt/rh/rh-redis32/log/redis/"
_redis_conf="/etc/opt/rh/rh-redis32/redis.conf"
_redis_bin="redis-cli --no-auth-warning"
_sentinel_conf="/etc/opt/rh/rh-redis32/redis-sentinel.conf"
# alias redis.stats='while : ; do clear ; /etc/redis/redis-stats.sh ; sleep 1 ; done'
alias redis.stats='watch -n1 -d /etc/redis/redis-stats.sh'
alias redis.cli="/usr/bin/scl enable rh-redis32 \"$_redis_bin -a $(grep '^requirepass' $_redis_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 6379\""
# Usage: redis.promote no one <ip> <port>
function redis.promote {
/usr/bin/scl enable rh-redis32 "$_redis_bin -a $(grep '^requirepass' $_redis_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 6379 SLAVEOF no one"
}
# Usage: redis.demote <ip> <port>
function redis.demote {
/usr/bin/scl enable rh-redis32 "$_redis_bin -a $(grep '^requirepass' $_redis_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 6379 REPLICAOF $1 $2"
}
function redis.save {
/usr/bin/scl enable rh-redis32 "$_redis_bin -a $(grep '^requirepass' $_redis_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 6379 CONFIG REWRITE"
}
alias redis.status='systemctl status rh-redis32-redis'
alias redis.restart='systemctl restart rh-redis32-redis'
alias redis.start='systemctl start rh-redis32-redis'
alias redis.stop='systemctl stop rh-redis32-redis'
function sentinel.cli {
/usr/bin/scl enable rh-redis32 "$_redis_bin -a $(grep '^requirepass' $_sentinel_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 26379"
}
# Usage: sentinel.failover <label>
function sentinel.failover {
/usr/bin/scl enable rh-redis32 "$_redis_bin -a $(grep '^requirepass' $_sentinel_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 26379 SENTINEL failover $1"
}
function sentinel.reset {
/usr/bin/scl enable rh-redis32 "$_redis_bin -a $(grep '^requirepass' $_sentinel_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 26379 SENTINEL reset $1"
}
function sentinel.save {
/usr/bin/scl enable rh-redis32 "$_redis_bin -a $(grep '^requirepass' $_sentinel_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 26379 SENTINEL flushconfig"
}
alias sentinel.status='systemctl status rh-redis32-redis-sentinel'
alias sentinel.restart='systemctl restart rh-redis32-redis-sentinel'
alias sentinel.start='systemctl start rh-redis32-redis-sentinel'
alias sentinel.stop='systemctl stop rh-redis32-redis-sentinel'
- Redis 5 (RH, SCL):
alias CD_REDIS="cd /etc/opt/rh/rh-redis5/"
alias CD_REDIS_LOG="cd /var/opt/rh/rh-redis5/log/redis/"
_redis_conf="/etc/opt/rh/rh-redis5/redis.conf"
_redis_bin="redis-cli --no-auth-warning"
_sentinel_conf="/etc/opt/rh/rh-redis5/redis-sentinel.conf"
# alias redis.stats='while : ; do clear ; /etc/redis/redis-stats.sh ; sleep 1 ; done'
alias redis.stats='watch -n1 -d /etc/redis/redis-stats.sh'
alias redis.cli="/usr/bin/scl enable rh-redis5 \"$_redis_bin -a $(grep '^requirepass' $_redis_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 6379\""
alias redis.cli="/usr/bin/scl enable rh-redis5 \"$_redis_bin -a $(grep '^requirepass' $_redis_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 6379\""
# Usage: redis.promote no one <ip> <port>
function redis.promote {
/usr/bin/scl enable rh-redis5 "$_redis_bin -a $(grep '^requirepass' $_redis_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 6379 SLAVEOF no one"
}
# Usage: redis.demote <ip> <port>
function redis.demote {
/usr/bin/scl enable rh-redis5 "$_redis_bin -a $(grep '^requirepass' $_redis_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 6379 REPLICAOF $1 $2"
}
function redis.save {
/usr/bin/scl enable rh-redis5 "$_redis_bin -a $(grep '^requirepass' $_redis_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 6379 CONFIG REWRITE"
}
alias redis.status='systemctl status rh-redis5-redis'
alias redis.restart='systemctl restart rh-redis5-redis'
alias redis.start='systemctl start rh-redis5-redis'
alias redis.stop='systemctl stop rh-redis5-redis'
function sentinel.cli {
/usr/bin/scl enable rh-redis5 "$_redis_bin -a $(grep '^requirepass' $_sentinel_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 26379"
}
# Usage: sentinel.failover <label>
function sentinel.failover {
/usr/bin/scl enable rh-redis5 "$_redis_bin -a $(grep '^requirepass' $_sentinel_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 26379 SENTINEL failover $1"
}
function sentinel.reset {
/usr/bin/scl enable rh-redis5 "$_redis_bin -a $(grep '^requirepass' $_sentinel_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 26379 SENTINEL reset $1"
}
function sentinel.save {
/usr/bin/scl enable rh-redis5 "$_redis_bin -a $(grep '^requirepass' $_sentinel_conf | \
awk '{print $2}' | sed 's/"//g') -h 127.0.0.1 -p 26379 SENTINEL flushconfig"
}
alias sentinel.status='systemctl status rh-redis5-redis-sentinel'
alias sentinel.restart='systemctl restart rh-redis5-redis-sentinel'
alias sentinel.start='systemctl start rh-redis5-redis-sentinel'
alias sentinel.stop='systemctl stop rh-redis5-redis-sentinel'
Przygotowałem także bardzo prosty skrypt (tak naprawdę zbiór poleceń, dodajemy go np. do /etc/redis/redis-stats.sh), który wyświetla najważniejsze parametry i status w czasie rzeczywistym, który będzie wywoływany za pomocą aliasu redis.stats. Obsługuje trzy wersje Redisa dlatego przed wykorzystaniem należy go odpowiednio dostosować (odkomentować odpowiednie linijki):
#!/usr/bin/env bash
# CentOS Redis 3.2.12:
# _redis_conf="/etc/redis.conf"
# _sentinel_conf="/etc/redis-sentinel.conf"
# CentOS (SCL) Redis32:
# _redis_conf="/etc/opt/rh/rh-redis32/redis.conf"
# _sentinel_conf="/etc/opt/rh/rh-redis32/redis-sentinel.conf"
# CentOS (SCL) Redis5:
_redis_conf="/etc/opt/rh/rh-redis5/redis.conf"
_sentinel_conf="/etc/opt/rh/rh-redis5/redis-sentinel.conf"
_redis_bin="redis-cli --no-auth-warning"
_redis_label="mymaster"
# Dla przejrzystości wykorzystałem taką metodę,
# wydajniejszy jest jednak grep|egrep.
_r_opts=("requirepass" \
"masterauth" \
"replicaof" \
"slaveof" \
"replica-priority" \
"slave-priority" \
"replica-read-only" \
"slave-read-only" \
"protected-mode")
_s_opts=("myid" \
"requirepass" \
"sentinel monitor" \
"sentinel auth-pass" \
"down-after-milliseconds" \
"failover-timeout" \
"sentinel known-replica" \
"sentinel known-slave" \
"sentinel known-sentinel" \
"sentinel parallel-syncs")
ifconfig | \
grep -Eo 'inet (addr:)?([0-9]*\.){3}[0-9]*' | \
grep -Eo '([0-9]*\.){3}[0-9]*' | \
grep -v '127.0.0.1'
# ps aux | grep "^redis"
ps -o pid,%cpu,%mem,cmd -C redis-server -C redis-sentinel
for opt in "${_r_opts[@]}" ; do
egrep -v '#|^$' "$_redis_conf" | egrep "$opt" "$_redis_conf"
done
for opt in "${_s_opts[@]}"; do
egrep -v '#|^$' "$_sentinel_conf" | egrep "$opt" "$_sentinel_conf"
done
echo -en "---------------------------------------\n"
_rpass=$(grep "^requirepass" "$_redis_conf" | awk '{print $2}' | sed 's/"//g')
_spass=$(grep "^requirepass" "$_sentinel_conf" | awk '{print $2}' | sed 's/"//g')
# CentOS Redis 3.2.12:
# $_redis_bin -a $_rpass -h 127.0.0.1 -p 6379 INFO replication
# $_redis_bin -a $_spass -h 127.0.0.1 -p 26379 PING
# $_redis_bin -a $_spass -h 127.0.0.1 -p 26379 SENTINEL ckquorum $_redis_label
# CentOS (SCL) Redis32:
# /usr/bin/scl enable rh-redis32 "$_redis_bin -a $_rpass -h 127.0.0.1 -p 6379 INFO replication"
# /usr/bin/scl enable rh-redis32 "$_redis_bin -a $_spass -h 127.0.0.1 -p 26379 PING"
# /usr/bin/scl enable rh-redis32 "$_redis_bin -a $_spass -h 127.0.0.1 -p 26379 SENTINEL ckquorum $_redis_label"
# CentOS (SCL) Redis5:
/usr/bin/scl enable rh-redis5 "$_redis_bin -a $_rpass -h 127.0.0.1 -p 6379 INFO replication"
/usr/bin/scl enable rh-redis5 "$_redis_bin -a $_spass -h 127.0.0.1 -p 26379 PING"
/usr/bin/scl enable rh-redis5 "$_redis_bin -a $_spass -h 127.0.0.1 -p 26379 SENTINEL ckquorum $_redis_label"
Podsumowanie #
W tym wpisie omówiliśmy czym jest Redis. W następnej serii wpisów przedstawię jego działanie na przykładzie replikacji asynchronicznej Master-Slave w połączeniu z usługą Redis Sentinel.