Z którego miejsca kontrolować nagłówki odpowiedzi?
06 May 2020
best-practices headers http response
Wydawać by się mogło, że pytanie to jest pozbawione sensu, ponieważ niezależnie gdzie ustawimy nagłówki odpowiedzi i tak przecież finalnie trafią one do klienta. Jest to niewątpliwie prawda, jednak mimo wszystko chciałbym się pochylić nad tym pytaniem, ponieważ istnieją, moim zdaniem, pewne różnice wynikające z lokalizacji ich ustawienia. Po drugie, znajomość podstaw nagłówków, a także ich poprawnego definiowania, jest kluczem do zrozumienia wydajności i bezpieczeństwa dowolnego serwera HTTP, oraz samej aplikacji.
Inną kwestią jest to, że nie ma żadnego oficjalnego zalecenia (jako jednego dokumentu) co do konkretnego miejsca definiowania nagłówków. Żadne RFC tego nie opisuje, nie znalazłem także informacji na stronach takich organizacji jak Mozilla, Cloudflare, Google czy Fastly — dlatego nie sądzę, aby istniała jakakolwiek oficjalna reguła, która jasno określa ich rozmieszczenie.
Nie ma też jednoznacznej odpowiedzi na zadane w tytule pytanie. Tak naprawdę najbardziej oczywistą powinno być „to zależy”, gdyż mamy trzy miejsca, z których poziomu możemy je kontrolować:
- aplikacja/framework
- serwery web
- serwery proxy
Dzięki czemu jesteśmy w stanie umieszczać je i sterować nimi prawie w dowolnym momencie przetwarzania żądania. W niektórych przypadkach jesteśmy zmuszeni zwrócić nagłówki z danej warstwy (np. nagłówek Server z poziomu serwera HTTP), w jeszcze innych przypadkach kluczowe w podjęciu decyzji powinno być to, która z tych trzech warstw znajduje się najbliżej klienta. Ponadto uważam, że zależy to także od prostoty implementacji (np. intuicyjny interfejs) każdego z rozwiązań oraz odpowiedzialności i przeznaczenia konkretnego nagłówka. Inną równie ważną kwestią jest to, że aplikacje najczęściej nie są dostępne z zewnątrz, zaś klient widzi tak naprawdę serwery HTTP będące na styku z siecią publiczną. Dlatego, zwłaszcza ze względów bezpieczeństwa (a nie wygody), wskazana jest obsługa niektórych nagłówków po stronie serwerów proxy.
Prawda jest taka, że ich lokalizacja nie ma aż tak dużego znaczenia oraz wpływu na klienta, o ile są one ustawione w sposób dający oczekiwane wyniki. Istnieje też wiele różnych typów nagłówków, więc zakładając, że mamy na myśli te, które przeglądarka musi zinterpretować, wtedy moim zdaniem sprowadza się to do tego, co kontrolujemy i co jest najłatwiejsze w implementacji i późniejszym zarządzaniu.
Na przykład możesz je ustawić po stronie Twojego CDN’a (tj. Cloudflare), co jest bardzo częstą praktyką, jednak to naprawdę nie ma znaczenia jeśli zachowasz zgodność ze standardem w kwestii ich poprawnego definiowania oraz dobrymi praktykami (zastosujesz np. nagłówki zwiększające bezpieczeństwo z odpowiednimi wartościami). Możesz je także ustawić na każdym web’ie klastra jeśli zapewnisz przewidywalne zachowanie dla każdego żądania (taka sama odpowiedź razem z nagłówkami). Oczywiście, w przypadku niektórych nagłówków nie ma innej możliwości niż ustawienie ich z konkretnego poziomu, np. jeśli nagłówki zwracają informację dotyczące samego serwera — wtedy muszą zostać ustawione po jego stronie.
Co więcej, błędy związane z niepoprawnymi wartościami nagłówków lub po prostu ich brakiem (zwłaszcza tych kluczowych), mogą spowodować poważne problemy z bezpieczeństwem i/lub prywatnością. Jak każdy ogólny protokół przesyłania danych, HTTP nie może regulować ich zawartości, ani nie istnieje żadna metoda określania wrażliwości jakiejkolwiek konkretnej informacji w kontekście danego żądania czy odpowiedzi. Dlatego też serwery HTTP oraz aplikacje powinny dostarczać mechanizmy zapewniające jak największą kontrolę nad informacjami umieszczanymi w nagłówkach.
Czym są nagłówki odpowiedzi? #
Z założenia nagłówki HTTP są dodatkowymi i w większości opcjonalnymi informacjami (np. nagłówek Host jest wymagany we wszystkich komunikatach żądania HTTP/1.1), które przemieszczają się między klientem a serwerem wraz z żądaniem lub odpowiedzią.
Gdy klient żąda zasobu, używa do tego protokołu HTTP. Żądanie obejmuje zestaw par klucz-wartość, które określają informacje takie jak wersja przeglądarki czy formaty obsługiwanych plików. Te pary klucz-wartość nazywane są nagłówkami żądań (są oczywiście także obecne w odpowiedziach, o czym zaraz wspomnę). Gdy serwer otrzyma żądanie, dokładnie wie, jakiego zasobu potrzebuje klient (za pośrednictwem URI) i co chce on zrobić z tym zasobem (za pomocą metody). Na przykład w przypadku żądania GET serwer przygotowuje zasób i zwraca go w odpowiedzi HTTP.
Nagłówek HTTP składa się z nazwy bez rozróżniania wielkości liter, po której następuje dwukropek
:, a następnie jego wartość (bez podziałów linii).
Serwer odpowiada żądanym zasobem, ale wysyła również nagłówki odpowiedzi (czyli pary klucz-wartość), podając informacje na temat zasobu lub samego serwera. Te nagłówki zawierają informacje o przychodzącej odpowiedzi. Rozmowa typu żądanie-odpowiedź jest podstawowym procesem napędzającym całą komunikację wykorzystującą protokół HTTP. Ponadto, jak już wspomniałem wcześniej, nagłówki odpowiedzi protokołu HTTP można wykorzystać do zwiększenia bezpieczeństwa aplikacji internetowych i to bardzo niskim kosztem, zwykle po prostu przez dodanie kilku wierszy kodu.
Nagłówki odpowiedzi są dołączane do danych przesyłanych z powrotem do klienta (najczęściej do przeglądarki) głównie w celach informacyjnych, lub by poinstruować go, aby wykonał jakąś akcję. Większość możliwych nagłówków odpowiedzi jest generowana przez sam serwer HTTP. Obejmują one instrukcje dla klienta dotyczące buforowania zawartości (lub nie), języka treści czy kodu statusu żądania.
Technicznie nagłówki HTTP to po prostu pola zakodowane czystym tekstem, które są częścią nagłówka żądania i komunikatu odpowiedzi. Zostały zaprojektowane tak, aby umożliwić zarówno klientowi, jak i serwerowi, wysyłanie i odbieranie metadanych dotyczących nawiązanego połączenia, żądanego zasobu, a także samego zwróconego zasobu (jego treści).
Inną istotną rzeczą jest to, że wiele żądań może zostać wysłanych za pośrednictwem tego samego połączenia HTTP, jednak serwer nie nadaje im żadnego specjalnego znaczenia (jest to wyłącznie kwestia wydajności, mająca na celu zminimalizowanie czasu oraz przepustowości). Z tego powodu protokół HTTP jest protokołem bezstanowym (ang. stateless), co oznacza, że połączenie między przeglądarką a serwerem zostaje utracone po zakończeniu transakcji. Każdy zasób, do którego dostęp jest uzyskiwany przez HTTP, jest pojedynczym żądaniem bez jakiejkolwiek relacji między nimi (co oznacza, że każdy komunikat żądania jest rozumiany osobno). Wynika z tego fakt, że wszystkie prośby oraz odpowiedzi są osobnymi bytami i muszą zawierać wystarczającą ilość informacji (określaną z poziomu nagłówków), aby mogły zostać zrealizowane, bez konieczności przechowywania informacji i metadanych z poprzednich żądań lub odpowiedzi.
Bezstanowość protokołów HTTP/1.1 oraz HTTP/2 obecnie dosyć przeszkadza, ponieważ nie wymagają one od serwera przechowywania informacji ani statusu, np. o każdym użytkowniku przez czas trwania wielu żądań. Jak wiemy, głównym założeniem protokołu HTTP było przesyłanie prostych i lekkich stron statycznych. W miarę powstawania web aplikacji szybko wymyślono sposoby na złagodzenie tego stanu rzeczy, poprzez stosowanie takich elementów, jak pliki cookie czy kodowanie stanu w adresach URL.
Struktura odpowiedzi #
Przejdźmy teraz do struktury odpowiedzi zwracanej do klienta. Po otrzymaniu i zinterpretowaniu komunikatu żądania serwer odpowiada komunikatem odpowiedzi HTTP. Zgodnie z RFC budowa jest następująca:
FIELDS OF HTTP RESPONSE PART OF RFC 2616
---------------------------------------------------------------------
Response = (1) : Status-line Section 6.1
(2) : *(( general-header Section 4.5
| response-header Section 6.2
| entity-header ) CRLF) Section 7.1
(3) : CRLF
(4) : [ message-body ] Section 7.2
Aby lepiej zrozumieć wymianę komunikatów między klientem a serwerem, poniżej znajduje się przykład utworzenia żądania HTTP w celu pobrania zasobu /alerts/status z serwera HTTP uruchomionego na localhost:8000:

Oraz przykład formularza odpowiedzi HTTP na powyższe żądanie:
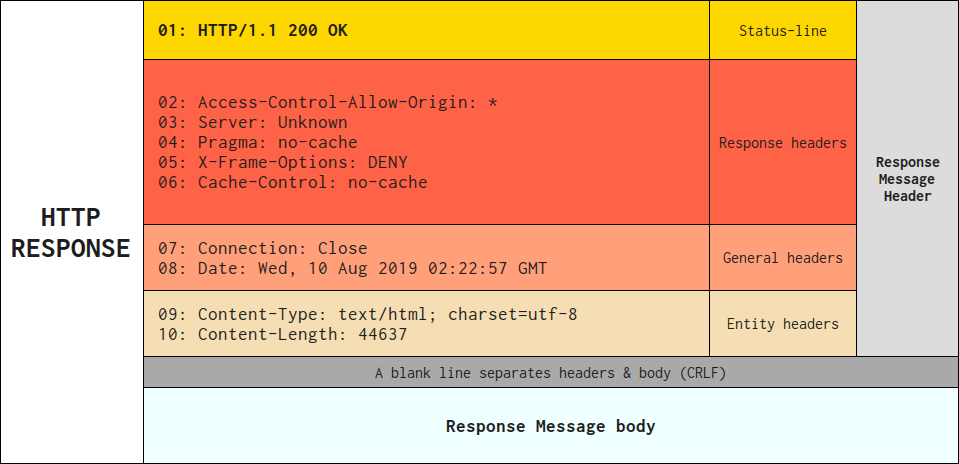
Przy czym należy pamiętać, że nie wszystkie nagłówki pojawiające się w odpowiedzi są nagłówkami odpowiedzi (to samo dotyczy żądania). Na przykład nagłówek Content-Length jest nagłówkiem encji odnoszącym się do rozmiaru treści komunikatu odpowiedzi. Nagłówkiem encji jest także Content-Encoding. Jednak żądania encji są zwykle nazywane nagłówkami odpowiedzi w takim kontekście.
Najważniejsze jest jednak, że niezależnie od używanego języka, typu aplikacji (web, mobile, JSON API) lub filozofii programistycznej, ostatecznym celem aplikacji jest zawsze zrozumienie każdego żądania oraz utworzenie i zwrócenie poprawnej odpowiedzi.
Poniżej znajduje się bardzo ogólny opis przepływu żądania i wygenerowania odpowiedzi do klienta:
- klient (np. przeglądarka) wysyła żądanie HTTP
- żądanie najczęściej przechodzi przez serwery proxy i jest przez nie obsługiwane, co więcej, już w tej warstwie może być modyfikowane
- serwery proxy, w przypadku plików statycznych, takich jak CSS, JS lub treści binarne (np. obrazy), przekazuje żądanie bezpośrednio do backendu w celu bezpośredniego zwrócenia zasobu
- już na tym etapie mogą zostać uruchomione mechanizmy związane z kontrolą dostępu, limitowaniem ruchu czy przekierowaniami
- co więcej, serwer proxy dołącza specjalne nagłówki, tj. X-Forwarded-For w celu przekazania dodatkowych informacji do serwerów webowych oraz aplikacji
- jeżeli jako front dla aplikacji wykorzystujemy serwery HTTP, żądanie może przejść przez taki serwer i także zostać poddane modyfikacji
- serwer HTTP może następnie przekazać żądanie do specjalnego interpretera (np. WSGI dla aplikacji napisanych w Pythonie), który zapewnia interfejs i pełni rolę łącznika między serwerem HTTP a oprogramowaniem aplikacji
- następnie żądanie trafia do aplikacji, która je przetwarza i najczęściej wpada przez ten sam początkowy „kontroler” (wspólny punkt wejścia dla wszystkich żądań)
- żądanie następnie przechodzi przez kilka wewnętrznych mechanizmów aplikacji
- kod aplikacji interpretuje głównie informacje o żądaniu i tworzy odpowiedź. Jednak w jego skład wchodzą dodatkowo takie czynności jak wysyłanie wiadomości e-mail, obsługa formularzy, zapisywanie w bazie danych, renderowanie stron HTML czy wszystkie kwestie związane z bezpieczeństwem
- na koniec aplikacja generuje odpowiedź (obiekt opakowany w nagłówki i treść) w celu przesłania jej z powrotem do klienta
- odpowiedź ponownie przechodzi przez serwery HTTP oraz serwery proxy (ponownie może zostać poddana dodatkowej modyfikacji)
- na koniec trafia do klienta (np. przeglądarki), która ją interpretuje
Przed przejściem do dalszej części artykułu polecam zapoznać się z następującymi zasobami:
- HTTP headers
- The HTTP Request Headers List
- The HTTP Response Headers List
- Exotic HTTP Headers
- Secure your web application with these HTTP headers
- OWASP Secure Headers Project
Status wiadomości #
Linia statusu (ang. Status-line) składa się z wersji protokołu, po której następuje numeryczny kod statusu i związana z nim fraza tekstowa:
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
Wersja HTTP #
Numer wersji HTTP wskazuje specyfikację HTTP, do której serwer próbował dopasować komunikat.
Gdy wiadomość HTTP/1.1 jest wysyłana do odbiorcy HTTP/1.0 lub adresata, którego wersja jest nieznana, komunikat HTTP/1.1 jest skonstruowany w taki sposób, że można go interpretować jako prawidłowy komunikat HTTP/1.0, jeśli wszystkie nowsze funkcje są zignorowany.
Przy okazji warto zerknąć na RFC 2145 - Use and Interpretation of HTTP Version Numbers [IETF].
Kody stanu i fraza przyczyny #
Kod stanu przekazuje klientowi ogólny wynik żądania. Czy prośba się powiodła? Czy wystąpił błąd? Istnieją różne kody stanu, które wskazują sukces, błąd lub że klient musi coś zrobić (np. przejść na inną stronę). Poniżej znajdują się krótkie opisy dla każdego typu kodów HTTP (patrz: RFC 2616 - Status Code and Reason Phrase [IETF]):
-
1xx: Informational - są często przejściowymi odpowiedziami, które wskazują, że żądanie zostało odebrane i zrozumiane, a komunikacja nadal trwa i klient wciąż czeka na ostateczną odpowiedź
-
2xx: Success - wskazują udane odpowiedzi, co zwykle oznacza, że działanie zlecone przez klienta zostało odebrane, zrozumiane i zaakceptowane
-
3xx: Redirection - wskazują one, że klient musi wykonać inną akcję (przekierowanie), aby uzyskać kompletny wymagany zasób
-
4xx: Client Error - definiują one klasę przypadków oraz reakcje na błędy po stronie klienta
-
5xx: Server Error - ta grupa kodów wskazuje, że serwer wie, że wystąpił błąd lub nie jest w stanie wykonać (pozornie poprawnego) żądania
Aby uzyskać więcej informacji na temat kodów odpowiedzi, koniecznie zapoznaj się z poniższymi zasobami:
Spójrz także na to (genialna praca!):
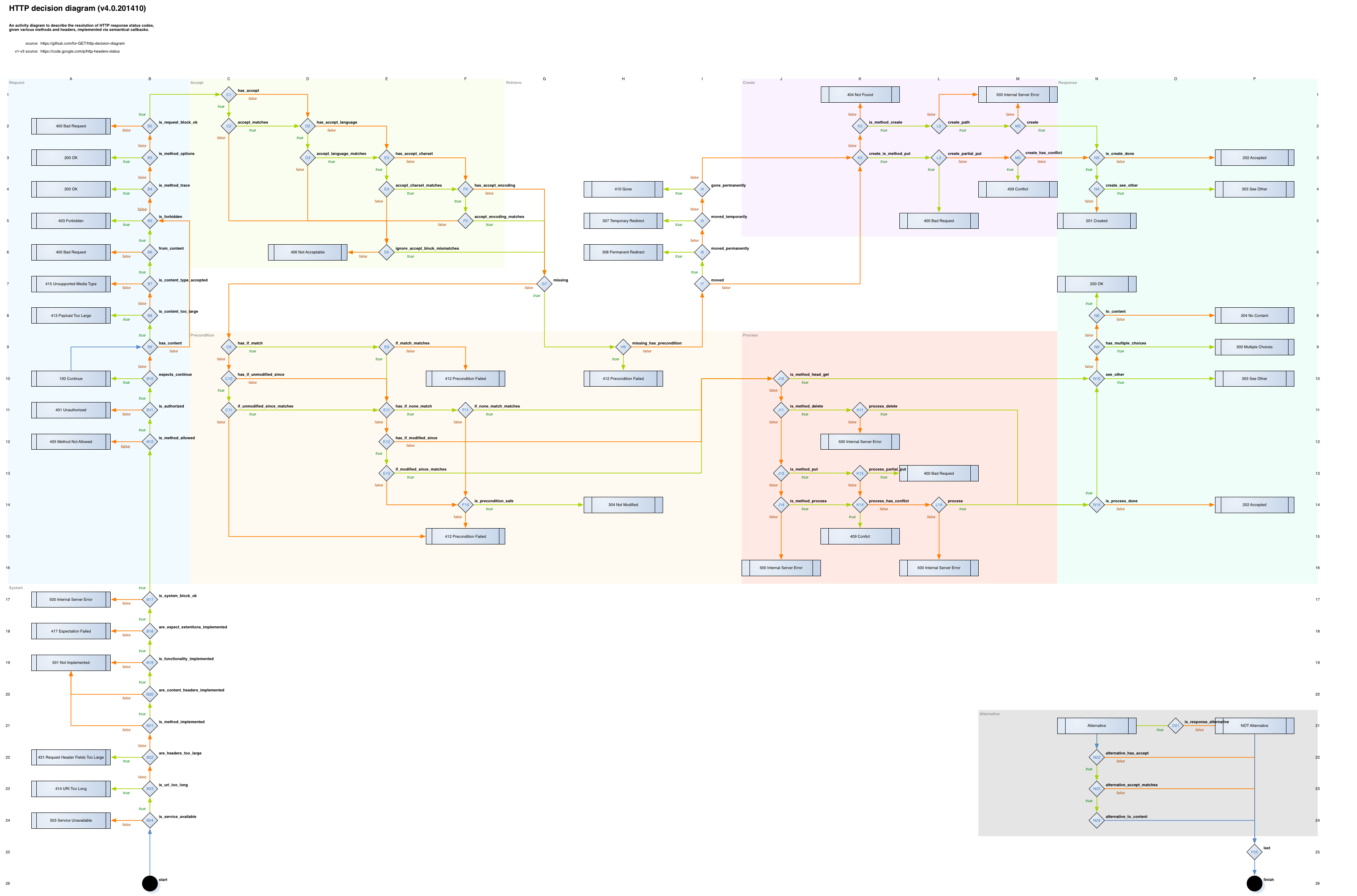
Powyższy schemat jest zgodny ze wskazaniami opisanymi w RFC7230, RFC7231, RFC7232, RFC7233, RFC7234, RFC7235 i w razie potrzeby wypełnia pustkę związaną z opisem statusu odpowiedzi HTTP na każdym etapie przetwarzania żądania lub odpowiedzi, z uwzględnieniem różnych nagłówków (oczywiście w żadnym wypadku nie zastępuje specyfikacji HTTP).
Pola nagłówków #
Istnieją trzy typy nagłówków wiadomości HTTP dla odpowiedzi:
-
Nagłówek ogólny (ang. General-header) - dotyczy zarówno żądań, jak i odpowiedzi, ale bez związku z danymi ostatecznie przesłanymi w treści
-
Nagłówek odpowiedzi (ang. Response-header) - pozwalają serwerowi przekazać dodatkowe informacje o odpowiedzi i dalszym dostępie do zasobu określonego przez identyfikator URI żądania
-
Nagłówek encji (ang. Entity-header) - zawierający więcej informacji na temat treści encji, takich jak długość treści lub typ MIME
Jak już wspomniałem, pola nagłówka odpowiedzi umożliwiają serwerowi przekazanie dodatkowych informacji. Przy czym nierozpoznane pola nagłówka są traktowane jak pola nagłówka encji (dla HTTP/1.1).
Treść wiadomości #
Treść wiadomości (ang. message-body) to dane zasobów, o które poprosił klient. Są to rzeczywiste dane (bajty danych przesyłane w komunikacie transakcji HTTP bezpośrednio po nagłówkach, jeśli istnieją) żądania HTTP (np. dane formularza) oraz dane odpowiedzi HTTP z serwera (w tym pliki, obrazy itp.).
Część treści komunikatu jest opcjonalna dla komunikatu HTTP, ale jeśli jest dostępna, służy do przenoszenia treści elementu powiązanej z żądaniem lub odpowiedzią. Jeśli treść elementu jest powiązana, wówczas zwykle nagłówki Content-Type i Content-Length określają naturę powiązanego obiektu.
Aplikacja/framework #
Na tym poziomie najszersze pole do popisu mają programiści, którzy (jeżeli framework na to pozwala, a zazwyczaj pozwala) mogą obsługiwać nagłówki zwracane do klienta poziomu logiki aplikacji. Każde wysłane żądanie przechodzi zazwyczaj przez odpowiedni komponent web aplikacji, zanim zostanie przetworzone w celu wygenerowania odpowiedzi.
Wiele nagłówków wymaga lokalnych decyzji dotyczących sposobu ich ustawienia. Na przykład niektóre nagłówki skryptów między witrynami wymagają określenia, które domeny czy subdomeny mają mieć dostęp do domeny, czy zasobu.
Nawet mimo samej możliwości ustawienia większości nagłówków z aplikacji, czy istnieje uzasadnienie zwracania każdego z nich z jej poziomu? Myślę, że aplikacja powinna zwracać zwłaszcza te nagłówki, które wpływają na jej konkretne komponenty, a nie na całość. Nie jest to jednak takie proste i oczywiste. Sytuacje, gdy aplikacja musi przesyłać dane kontekstowe, takie jak CSP dla konkretnej strony czy całej domeny powinny odbywać się z jej poziomu, a nie z poziomu serwera HTTP. Jeszcze innym przykładem jest debugowanie lub analiza działania pewnych mechanizmów zaimplementowanych w aplikacji (a także zwracanych przez nią danych). Uważam, że nagłówki ustawia się wtedy z poziomu aplikacji, serwer proxy powinien przekazać je tylko do użytkownika końcowego (przed tym ewentualnie zweryfikować).
Innym przykładem są przekierowania na wskazany adres URL i nagłówek Location (notabene, na który nie mamy wpływu, jest on dodawany automatycznie przy wykonywaniu przekierowania). Jeśli twoja aplikacja ma jakieś reguły biznesowe dla przekierowań 301/302, rozsądne jest, aby były one wykonywane po stronie aplikacji (która odpowiada za tę logikę). Jak myślisz, czy zasadne jest wykonywanie przekierowań innych niż przejście z HTTP na HTTPS po stronie serwerów proxy? Na to pytanie także nie ma jednoznacznej odpowiedzi. Z jednej strony pamiętajmy, że to proxy jest najbliżej użytkownika i wszystkie przekierowania po tej stronie zmniejszają opóźnienia, jednak jak wspomniałem wcześniej, to aplikacja odpowiada za logikę przekierowań (przynajmniej powinna).
Przekierowania można włączyć na wiele sposobów w aplikacji, jednak nie zawsze istnieje możliwość ich obsługi z jej poziomu, zwłaszcza jeśli chodzi o pliki statyczne (które mogą być poza jej kontrolą). Jest wtedy oczywistym, że obsługę przekierowań musi przejąć albo serwer proxy, albo serwery HTTP będące bezpośrednio przed aplikacją.
Mała dygresja. Tak naprawdę serwer HTTP powinien odpowiadać głównie za udostępnianie zasobów, a nie przetwarzanie lub jakiekolwiek logiczne operacje. Moim zdaniem wybór serwera internetowego powinien odzwierciedlać preferencje dotyczące dostarczania treści, a nie oprogramowania, które znajduje się za nim. Rolą serwerów jest rzetelnie odbierać i przekazywać żądania do aplikacji oraz dostarczać odpowiedzi do klienta. Nie powinny się one zagłębiać w treści czy użytkowników tylko czekać i robić to co wychodzi im najlepiej i do czego są tak naprawdę przeznaczone (mimo tego, że potrafią robić znacznie więcej i wychodzi im to w większości świetnie). Myślę, że warto mieć to na uwadze zwłaszcza jeżeli mamy robić z poziomu proxy bardziej wymagające rzeczy, które równie dobrze mogą (a najczęściej powinny) wykonywane być przez aplikację.
Wolałbym również, aby aplikacja definiowała nagłówki pamięci podręcznej, tj. Exipres, Cache-Control czy Last-Modified oraz aby cały stack będący przed nią je honorował. Uważam też, że obowiązkiem aplikacji jest określenie zasad buforowania dla każdej strony. Sprawa tutaj trochę się zmienia jeśli mamy przed aplikacją serwer cache’ujący. Jednak nadal to aplikacja powinna definiować (ew. zmieniać) reguły przechowywania obiektów w pamięci podręcznej, zaś serwer powinien stosować się do każdego takiego wyjątku mimo własnych (globalnych) reguł związanych z przechowywaniem odpowiedzi.
Przykładem nawiązującym w pewien sposób do powyższego problemu może być sytuacja, w której aplikacja ustawia maksymalny wiek za pomocą nagłówka max-age, ale robi to także serwer proxy za pomocą nagłówka s-maxage (np. Varnish), który jak wiemy, zastępuje nagłówek max-age lub Expires (dotyczy to jednak tylko współdzielonych pamięci podręcznych i jest ignorowany przez prywatną pamięć podręczną). Ponieważ nie chcemy, aby wartość s-maxage zakryła wartość tego pierwszego i dotarła do punktu końcowego (ponieważ jako parametr globalny, może mieć ustawioną wyższą wartość, której w tym konkretnym przypadku nie chcemy), serwer proxy usunie ją przed zwróceniem obiektu do klienta, respektując tym samym nagłówek zwracany z aplikacji.
Istnieją też nagłówki, które oczywiście można swobodnie ustawiać na każdej warstwie tj. związane z autoryzacją użytkownika — dlatego możemy to zrobić po stronie aplikacji, ale również po stronie serwera proxy. W tym przypadku problem może być wydajność, ponieważ czas odpowiedzi będzie niewątpliwie mniejszy w przypadku pominięcia przejścia przez aplikację. Co więcej, uważam, że niektóre mechanizmy autoryzacji (np. listy ACL) mogą być (a nawet powinny) implementowane po stronie serwerów proxy tak, aby nie zaprzęgać do tego odpowiednich mechanizmów zaimplementowanych po stronie backendu. Po co angażować aplikację do tego, skoro można to zrobić równie skutecznie, możliwie, że prościej oraz bliżej klienta zmniejszając potencjalne opóźnienia. Tyczy się to zwłaszcza sytuacji, kiedy serwer aplikacji nie jest dostępny bezpośrednio dla świata.
Inna sprawa to nagłówki, które nigdy nie powinny wyjść na zewnątrz, czyli takie, które mogą zdradzić cokolwiek ciekawego o samej aplikacji, np. X-Powered-By. Programiści nie zawsze odpowiednio dbają o takie informacje, z drugiej strony w wielu przypadkach to administratorzy zarządzają instancjami PHP i odpowiednia konfiguracji i zabezpieczenie należy do ich obowiązku (nawet jeśli ktoś dostarcza im konfigurację). Problem z tym typem nagłówków polega na tym, że informują one klienta (oraz atakującego) o języku aplikacji i używanym frameworku. W niektórych przypadkach ujawniają one również numer wersji. Dzięki tym informacjom potencjalny atakujący może skupić się na exploitach specyficznych dla danego języka lub komponentów, z których zbudowano aplikację.
Kolejny ciekawy przykład to nagłówek HSTS. Spójrzmy, jak możemy go zwrócić z poziomu Node.js:
function requestHandler(req, res) {
res.setHeader('Strict-Transport-Security','max-age=31536000; includeSubDomains');
}
Lub w celu wykonania tego samego wykorzystać moduł Helmet:
const helmet = require('helmet')
// Sets "Strict-Transport-Security: max-age=31536000; includeSubDomains".
const sixtyDaysInSeconds = 31536000
app.use(helmet.hsts({
maxAge: sixtyDaysInSeconds
includeSubDomains: true
}))
Z kolei Python i Django umożliwiają ustawienie tego nagłówka w następujący sposób (z poziomu pliku settings.py):
SECURE_HSTS_SECONDS = 31536000
SECURE_HSTS_INCLUDE_SUBDOMAINS = True
SECURE_SSL_REDIRECT = True
SECURE_PROXY_SSL_HEADER = ('HTTP_X_FORWARDED_PROTOCOL', 'https')
Oraz z wykorzystaniem tzw. oprogramowania pośredniego (ang. configurable security middleware), które może obsłużyć wszystkie ustawienia (patrz: Django Middleware).
Dzięki ustawieniu tego nagłówka domena informuje przeglądarki, że włączyła HSTS, zwracając nagłówek HTTP przez połączenie HTTPS. Zapewnia tym samym, że przeglądarki zawsze łączą się ze stroną internetową za pośrednictwem tego drugiego. HSTS istnieje, aby usunąć potrzebę powszechnej, niepewnej praktyki przekierowywania użytkowników z http:// na https://.
W tym przypadku powinny głównie zadecydować kwestie wydajnościowe, czyli która warstwa jest bliżej użytkownika oraz zastosowanie tego samego rodzaju odpowiedzialności jak w przypadku nagłówków ustawianych po stronie aplikacji. Pamiętajmy, że w przypadku tego nagłówka, pierwsze żądanie i tak dotknie albo serwer proxy, albo aplikację (chyba że witryna znajduje się na tzw. liście wstępnego ładowania) jednak każdy następny będzie wykonywany przez przeglądarkę, aby już po stronie klienta przeprowadzała wewnętrzne przekierowanie z HTTP na HTTPS bez angażowania np. warstwy serwera. Wiadomo, jest to tylko jeden skok, jednak może delikatnie zmniejszyć czas odpowiedzi.
Jeszcze co do HSTS, to nie znalazłem żadnego uzasadnienia, aby jego kontrolę miała przejąć aplikacja (mimo samej możliwości jego obsługi). Uważam, że wszystkie kwestie związane z konfiguracją SSL/TLS powinny być obsługiwane z jednego miejsca — z poziomu usługi terminującej ten rodzaj ruchu/protokołu. W tym konkretnym przypadku aplikacja tak naprawdę powinna tylko zapewnić, że wszystkie jej zasoby serwowanie są z wykorzystaniem protokołu HTTPS.
Na koniec tego rozdziału należy także wspomnieć, że w pewnych sytuacjach generowanie nagłówków z poziomu aplikacji może być ograniczone a wręcz niemożliwe. Odpowiedzi możemy tak naprawdę generować z jej poziomu tylko dla żądań, które wpadają do „aplikacji”. W takiej sytuacji wszystkie wymagane nagłówki muszą być dołączane do odpowiedzi z poziomu serwera HTTP/proxy.
Serwery web’owe i proxy #
Ta warstwa to poletko dla administratorów. Skupię się jednak głównie na warstwie proxy, ponieważ moim zdaniem powinniśmy definitywnie porzucić pomysły ustawiania nagłówków odpowiedzi po stronie frontu dla aplikacji, tj. w warstwie backendu na serwerach HTTP. Głównie ze względu na złożoność utrzymania konfiguracji, wprowadzania zmian, a także na większą szansę popełnienia pomyłki (nie jest porządane jeśli trzy odpowiedzi zwrócą nagłówek X-XSS-Protection poprawnie zaś czwarta w ogóle).
Większość nagłówków można dodać z poziomu konfiguracji serwera HTTP/proxy. W przypadku serwera NGINX możemy wykorzystać dyrektywę
add_header(jednak przed używaniem tego sposobu przeczytaj koniecznie NGINX: Jak poprawnie obsługiwać nagłówki?) lub zewnętrzny moduł ngx_headers_more. W przypadku serwera Apache możemy to zrobić za pomocą modułumod_headers.
Warstwa proxy #
Ustawiając nagłówki odpowiedzi z poziomu serwerów proxy, mamy (jako administratorzy) największą kontrolę nad tym co wychodzi w odpowiedzi oraz pewność, że to, co przejdzie przez proxy, będzie ostateczną odpowiedzią, która trafi do klienta. Dzięki temu wiemy, że już nic nie usunie lub nie zmodyfikuje tych nagłówków. Chodzi tutaj głównie o wszelkiego rodzaju nagłówki bezpieczeństwa, które są podstawową częścią każdej nowoczesnej aplikacji. Nagłówki odpowiedzi ustawiamy na serwerach proxy głównie dlatego, że jest to najtańsze, najbardziej elastyczne oraz zapewnia pojedynczy punkt obsługi.
Gdy aplikacje internetowe stoją za serwerami proxy lub modułami równoważenia obciążenia, mogą dołączać niestandardowe nagłówki lub ustawiać nieprawidłowe wartości nagłówków zdefiniowanych w RFC. Mogą to być nagłówki zawierające poufne informacje, dlatego powinniśmy je weryfikować oraz definitywnie usuwać. Oprócz dodawania nagłówków odpowiedzi możemy je poddawać normalizacji, jeśli uznamy, że niektóre z nich mają nieodpowiednie i niepoprawne wartości. Serwer proxy powinien działać jak dobry strażnik, który kontroluje i zezwala na przekazywanie tylko tych informacji, które powinny trafić do klienta oraz poprawia w miarę możliwości wszystkie niedociągnięcia, które pochodzą z aplikacji.
Istnieją oczywiście nagłówki specyficzne tylko dla tej warstwy, tj. nagłówek Server, o którym zresztą powiedziałem na początku artykułu. Pole tego nagłówka zawiera informacje o oprogramowaniu używanym przez serwer pochodzenia do obsługi żądania i jest jakby poza kontrolą aplikacji. Moim zdaniem, informacje o serwerze powinny zostać usunięte z odpowiedzi HTTP, a ich ustawienie domyślne powoduje najczęściej wyciek tych danych. Nie jest to oczywiście żadna krytyczna luka, jednak nie ma potrzeby ogłaszania takich szczegółów (patrz: NGINX: Ujawnianie wersji i sygnatur serwera).
Innym powodem weryfikacji nagłówków definiowanych po stronie web aplikacji są mechanizmy cache’ujące. Na przykład, jedną z kluczowych wartości zwracanych w nagłówkach do klienta jest identyfikator PHPSESSID (dla aplikacji PHP), który ustawiamy jako wartość nagłówka set-cookie (pliki cookie są zazwyczaj ustawiane przez aplikację za pomocą tego nagłówka, a następnie przeglądarka automatycznie dodaje je do każdego żądania). Pamiętaj, że pliki cookie są nagłówkami odpowiedzi HTTP — aplikacja najpierw przekazuje plik cookie klientowi, a ten z kolei odsyła go w celu wykonania kolejnych operacji, po to, aby aplikacja wiedziała, z którym klientem pracuje. Dlatego głównym celem dostarczenia ich użytkownikowi jest jego późniejsza identyfikacja i śledzenie.
Z ciastkami jest ten problem, że jeśli istnieje plik cookie, pamięć podręczna jest pomijana. Więcej o tym problemie możesz poczytać w dwóch świetnych artykułach: Yet another post on caching vs cookies 1/2 oraz Mastering HTTP Caching - from request to response and everything. Jeśli mechanizm sesji nie jest potrzebny, natychmiast należy usunąć takie ciastko (z wyjątkiem tych absolutnie niezbędnych), aby obiekty były pobierane z pamięci podręcznej, a nie były przekazywane bezpośrednio do aplikacji. Nagłówek zawierający tę wartość powinien (i prawie zawsze jest) być generowany po stronie aplikacji (zwłaszcza, jeśli buforowane ma być coś, co zależy od użytkownika). Pamiętaj, że serwery cache widząc pliki cookie, nie sprawdzają, jakie jest ich faktyczne znaczenie (czy są odpowiedzialne za sesję, czy po prostu dołączane do żądania). Po odebraniu ciastka, serwery najczęściej stwierdzą „ooo! jest jakiś plik cookie, więc nie zamierzam go buforować”.
Wspominam o tym, ponieważ ten przykład pokazuje pewien podział odpowiedzialności. My jako administratorzy powinniśmy przecedzić przez sito resztę nagłówków, w tym zbędne nagłówki set-cookie. Jeśli wiesz na pewno, że backend nigdy nie używa sesji ani podstawowego uwierzytelniania, usuń odpowiedni nagłówek, aby zapobiec pomijaniu pamięci podręcznej przez klientów (a najlepiej przedyskutuj problem z architektami aplikacji w celu jego odpowiedniego rozwiązania), ponieważ błędy w tym obszarze mogą prowadzić do bardzo niebezpiecznych sytuacji, włączając w to możliwość przechwytywania sesji (Session hijacking attack).
Często też nie ma innej możliwości, jak ustawienie nagłówków po stronie serwera HTTP czy proxy. Niektóre treści zwracane przez aplikację to treści statyczne, więc jedynym sposobem niezawodnego dodawania nagłówków do wszystkiego jest właśnie poziom serwera HTTP/proxy. Ponadto problem może pojawić się jeśli żądanie odwołuje się bezpośrednio do jakiegoś katalogu z pominięciem aplikacji. Wtedy aplikacja nie przechwyci takiego żądania i nie będzie mogła wygenerować odpowiedzi.
Czy warto stosować niestandardowe nagłówki odpowiedzi? #
Po pierwsze: ponieważ ta funkcjonalność jest zawarta w specyfikacji HTTP, uważam, że nic nie stoi na przeszkodzie, aby z niej korzystać, jednak tylko, gdy ma to sens. W przeciwnym razie, po co zawracać sobie głowę niestandardowymi nagłówkami?
Tak naprawdę każdy nagłówek (albo większość) może otworzyć bardzo wiele potencjalnych luk w zabezpieczeniach. Ponadto, wiele z nich działa tylko w określonych przeglądarkach, które je obsługują. Jeśli przeglądarka użytkownika obsługuje dany nagłówek, to ok, w przeciwnym razie nic z nim nie zrobi i zwiększa tylko niepotrzebny koszt samego połączenia jeśli nagłówki nie są kompresowane (np. w HTTP/1.1) oraz może doprowadzić do nieoczekiwanych zachowań.
Jeśli zdecydujesz się na nowy nagłówek HTTP, np. ze względów bezpieczeństwa lub w celu zwiększenia możliwości debugowania, zalecam dodanie takiego nagłówka. Nie sądzę jednak, aby tworzenie nowych nagłówków było dobrym pomysłem (podobnie sprawa ma się z własnymi kodami odpowiedzi, patrz: Can we create custom HTTP Status codes?). Wyjątkiem mogą być niestandardowe mechanizmy uwierzytelniania (tj. uwierzytelnianie oparte na HMAC lub plikach cookie) lub cokolwiek, co może być wrażliwe na wydajność.
Z drugiej strony, niestandardowe nagłówki odpowiedzi mogą być niezwykle przydatne w scenariuszach, w których chcesz zidentyfikować określony serwer jeśli wykorzystujesz load-balancer i chcesz, np. wysłać nagłówek odpowiedzi z danego węzła w celu jego identyfikacji. Jednak są to nagłówki wymagane jedynie w czasie debugowania i nie powinny być widoczne dla szerszego grona odbiorców.
Inne ciekawe pytanie: Czy nie lepiej spakować informację w nagłówki, zamiast przekazywać ją w inny sposób klientowi? Moim zdaniem można dodać wiele wartości, dodając nagłówki, które z natury można przekazać w odpowiedzi (tj. związane z buforowaniem). Czasami jest to po prostu szybsze i prostsze rozwiązanie.
Pamiętaj jednak, aby nie używać nazw, które mogłyby być używane przez serwer zgodnie ze specyfikacją protokołu HTTP (np. RFC 2616 [IETF] dla protokołu HTTP/1.1, zerknij zwłaszcza na rozdział 14). Może to spowodować problemy z komunikacją między klientem a serwerem.
Jak to w końcu jest? #
Każdy z opisanych sposobów pozwala na sterowanie nagłówkami w całym cyklu życia żądania. Wszelkie komponenty oprogramowania pośredniego mogą sprawdzać bieżący stan trwającego żądania HTTP i mogą go zmieniać. W drodze powrotnej oprogramowanie pośrednie (aplikacja, proxy) może również sprawdzać odpowiedź i wprowadzać zmiany. Sposób, w jaki kodowane są zmiany w odpowiedzi, jest oczywiście krytyczny.
Tak naprawdę każda z opisywanych warstw może wykonywać wszystko, na co pozwalają warunki danego środowiska wykonawczego. Wszystko zależy od aplikacji czy serwera i konkretnego nagłówka. Zazwyczaj nagłówki ustawiam na warstwie proxy, najbliżej klienta. Bez jasnego uzasadnienia, po prostu „wydaje mi się” to słuszne. Co więcej, staram się kontrolować wszystko, co przychodzi z aplikacji, tj. usuwać zbędne i potencjalnie niebezpieczne nagłówki lub normalizować ich wartości.
Musimy też wiedzieć, że ustawienie odpowiednich nagłówków HTTP może zmniejszyć ryzyko ataków typu man-in-the-middle i cross-site-scripting na aplikację internetową. Możesz także ograniczyć wycieki informacji o konfiguracji aplikacji internetowej — istotne dane, które dają potencjalnym atakującym wskazówki na temat potencjalnych luk w zabezpieczeniach.
Uważam także, że wszystkie specyficzne nagłówki dla danej warstwy należy definiować z jej poziomu, np. nagłówki informacyjne, określające wykorzystanie pamięci podręcznej takie jak X-HIT czy X-MISS ustawione powinny być po stronie proxy. Nagłówki mające faktyczny wpływ na interpretację odpowiedzi, typowo związane z ustawianiem parametrów buforowania, powinny być obsługiwane po stronie aplikacji.
Jeżeli chodzi o nagłówki bezpieczeństwa, tj. Strict-Transport-Security lub X-Frame-Options — tutaj według mnie powinny być one zdefiniowane z poziomu serwera proxy lub z poziomu usługi obsługującej ruch SSL/TSL (oczywiście w tym przypadku głównie mam na myśli nagłówek HSTS).
W tym całym gąszczu pytań i odpowiedzi należy pamiętaj chyba o najważniejszym — przetestowaniu, jakie nagłówki zwraca twoja aplikacja. Szczerze mówiąc, testowanie serwerów i aplikacji uważam za znacznie ważniejsze niż głowienie się nad miejsce umieszczenia wykorzystywanych nagłówków. Po pierwsze, możesz użyć prostego curl’a. Jednak zalecam dodatkowo sprawdzanie konfiguracji za pomocą serwisów Security Headers oraz Mozilla Observatory. Jest to bardzo ważna czynność, która nie powinna być nigdy zaniedbywana, ponieważ niektóre serwery czy aplikacje mogą wysyłać nagłówki zwracające jakieś kluczowe informacje. Jeszcze inne mogą mieć niepoprawne (wręcz potencjalnie niebezpieczne) wartości, które mogą ułatwić przeprowadzenie ataku.
Pamiętajmy także, że każdy dodany nagłówek zajmuje pewną przepustowość (zwłaszcza jeśli nie wykorzystujemy kompresji) i cykle przetwarzania — nie dużo, ale jeśli się je zsumuje, wtedy może być problem. Na przykład, widziałem serwery i aplikacje (w tym jednego z większych Polskich banków), które rutynowo zwracały odpowiedzi HTTP, w których nagłówki były znacznie większe (np. CSP) niż zwracana treść (albo w ogóle za duże niezależnie od treści). Należy też pamiętać, że niektóre nagłówki mogą uszkodzić funkcjonalność aplikacji, stąd testowanie jest kluczową sprawą, aby wyłapać potencjalne problemy na tym etapie.
Kończąc, jak wspomniałem wcześniej, nie znam żadnej specyfikacji, która w jasny sposób definiowałaby lokalizację każdego z nagłówków odpowiedzi, podejmując rozważanie na ten temat oraz biorąc pod uwagę wady i zalety każdego z rozwiązań. Należy kierować się zdrowym rozsądkiem, przeznaczeniem każdego nagłówka oraz prostotą implementacji i późniejszego zarządzania.