NGINX: Logika przetwarzania żądań
18 Jan 2020
best-practices http nginx requests
Proces przetwarzania żądań przez serwer NGINX na pierwszy rzut oka może wydawać się skomplikowany. Cała logika jest jednak prosta i dobrze przemyślana.
W dużym skrócie wyszukiwanie rozpoczyna się od bloku http, następnie przechodzi przez jeden lub więcej bloków server, a następnie przez bloki location. Blok http zawiera dyrektywy do obsługi ruchu w sieci (do obsługi protokołów HTTP/HTTPS), które są przekazywane do wszystkich konfiguracji domen obsługiwanych przez NGINX.
Podczas obsługi żądań NGINX wykorzystuje bloki server (ich działanie jest analogiczne jak wirtualne hosty w Apache), które zawierają dwie kluczowe dyrektywy:
listendo wiązania się z gniazdami TCPserver_namew celu identyfikacji wirtualnych hostów
W trakcie oceny żądania NGINX sprawdza nagłówek Host, którego wartość zawiera domenę lub adres IP, do którego klient faktycznie próbuje dotrzeć. Co więcej, NGINX próbuje znaleźć najlepsze dopasowanie do wartości, którą znajdzie w tym nagłówku, patrząc na dyrektywę server_name w każdym z bloków serwera.
Obsługa połączeń przychodzących #
NGINX używa następującej logiki do określenia, który serwer wirtualny (blok serwera) powinien zostać użyty:
1) Dopasowuje parę <adres:port> do dyrektywy listen — może istnieć wiele bloków z dyrektywami listen o tej samej specyfice, które mogą obsłużyć żądanie
NGINX używa kombinacji
<adres:port>do obsługi połączeń przychodzących. Ta para jest przypisana do dyrektywylisten.
Wartość dyrektywy listen można ustawić na kilka sposobów:
-
kombinacja
<adres:port>, tj.127.0.0.1:80;(najbardziej zalecana) -
tylko adres IP; jeśli podano tylko adres, domyślnie używany jest port
80, czyli np. ustawiamy127.0.0.1;, który przekształca się w127.0.0.1:80; -
tylko nr portu; NGINX będzie nasłuchiwał na każdym interfejsie na tym porcie, czyli np. ustawiamy
80;lub*:80;, który przekształca się na0.0.0.0:80; -
ścieżka do gniazda, tj.
unix: /var/run/nginx.sock;
Jeśli dyrektywa listen nie jest ustawiona, wówczas używana jest konstrukcja *:80 (działa z uprawnieniami superużytkownika), albo *:8000.
Przetwarzanie w obrębie dyrektywy listen zaczyna się od następujących kroków:
-
NGINX tłumaczy wszystkie niepełne dyrektywy
listen, zastępując brakujące wartości ich wartościami domyślnymi (patrz wyżej) -
NGINX próbuje zebrać listę bloków serwera, które najbardziej pasują do żądania, na postawie konstrukcji
<adres:port> -
jakikolwiek blok, który używa
0.0.0.0nie zostanie wybrany, jeśli istnieją pasujące bloki, które zawierają jawnie określony adres IP -
jeśli istnieje choćby jedno dokładne dopasowanie, ten blok serwera zostanie wykorzystany do obsługi żądania
-
jeśli istnieje wiele bloków
servero tym samym poziomie dopasowania, NGINX zaczyna oceniać dyrektywęserver_namekażdego bloku serwera
Spójrz na poniższy przykład:
# From client side:
GET / HTTP/1.0
Host: api.random.com
# From server side:
server {
# This block will be processed:
listen 192.168.252.10; # --> 192.168.252.10:80
...
}
server {
listen 80; # --> *:80 --> 0.0.0.0:80
server_name api.random.com;
...
}
2) Dopasowuje pole nagłówka Host do dyrektywy server_name jako ciąg znaków z wykorzystaniem tablicy skrótów z dokładnymi nazwami
3) Dopasowuje pole nagłówka Host do dyrektywy server_name z symbolem wieloznacznym na początku łańcucha oraz z wykorzystaniem tablicy skrótów z nazwami symboli wieloznacznych rozpoczynającymi się gwiazdką
Jeśli na tym etapie dopasowanie będzie poprawne, blok, w którym występuje dyrektywa
server_namezostanie wykorzystany do obsługi żądania. Jeśli znaleziono wiele dopasowań, do wykonania żądania zostanie użyty blok serwera z najdłuższym dopasowaniem.
4) Dopasowuje pole nagłówka Host do dyrektywy server_name ze znakiem wieloznacznym na końcu łańcucha oraz z wykorzystaniem tablicy skrótów z nazwami symboli wieloznacznych kończącymi się gwiazdką
Jeśli na tym etapie dopasowanie będzie poprawne, blok, w którym występuje taka dyrektywa
server_namezostanie wykorzystany do obsługi żądania. Jeśli znaleziono wiele dopasowań, do wykonania żądania zostanie użyty blok serwera z najdłuższym dopasowaniem.
5) Dopasowuje pole nagłówka Host do dyrektywy server_name jako wyrażenie regularne
Pierwsze wystąpienie dyrektywy
server_name(z wyrażeniem regularnym) pasującej do nagłówka Host zostanie użyte do obsługi żądania.
6) Jeśli nagłówek Host nie pasuje do nazwy serwera, NGINX przechodzi się do dyrektywy listen oznaczonej jako default_server (parametr ten powoduje, że blok serwera odpowiada na wszystkie żądania, które nie pasują do żadnego bloku serwera)
7) Jeśli nagłówek Host nie pasuje do nazwy serwera i nie ma domyślnego serwera, NGINX przechodzi bezpośrednio do pierwszego bloku serwera z dyrektywą listen
Wynika z tego, że domyślny serwer występuje zawsze. Jeżeli nie wskażemy go jawnie za pomocą dyrektywy
default_serverbędzie nim pierwszy blokserverw konfiguracji. Może rodzić to niepożądane problemy dlatego zalecane jest aby zawsze wskacać serwer domyślny w konfiguracji.
8) Następnie NGINX przechodzi do kontekstu location
Dopasowanie lokalizacji #
Blok lokalizacji umożliwia obsługę kilku typów identyfikatorów URI/tras (routing w warstwie 7 na podstawie adresu URL) w obrębie bloku serwera. Składnia wygląda następująco:
location optional_modifier location_match { ... }
location_match określa sprawdzenie identyfikatora URI żądania. Argument optional_modifier spowoduje, że skojarzony blok lokalizacji zostanie zinterpretowany w następujący sposób (w tej chwili kolejność nie ma znaczenia):
-
(none): jeśli nie ma żadnych modyfikatorów, lokalizacja jest interpretowana jako dopasowanie przedrostka. Aby ustalić dopasowanie, lokalizacja będzie teraz dopasowywana do początku identyfikatora URI
-
=: jest dokładnym dopasowaniem, bez żadnych symboli wieloznacznych, dopasowywania prefiksów ani wyrażeń regularnych; wymusza dosłowne dopasowanie między identyfikatorem URI żądania a parametrem lokalizacji
-
~: jeśli obecny jest modyfikator tyldy, to położenie musi być użyte do dopasowania z rozróżnianiem wielkości liter (dopasowanie wyrażeń regularnych)
-
~*: jeśli używany jest modyfikator tyldy i gwiazdki, należy użyć lokalizacji do dopasowania bez rozróżniania wielkości liter (dopasowanie wyrażeń regularnych)
-
^~: zapobiega dopasowaniu wyrażeń regularnych i okraśla najlepsze dopasowanie wyrażeń nieregularnych; oznacza, że dopasowanie wyrażeń regularnych nie nastąpi
A teraz krótkie wprowadzenie wyjaśniające priorytet lokalizacji:
-
dokładne dopasowanie ma najwyższy priorytet i jest przetwarzane w pierwszej kolejności; jeżeli występuje dalsze przeszukiwanie jest zakończone
-
dopasowanie prefiksu ma niższy priorytet; istnieją dwa typy przedrostków: ^~ i (none), jeśli ten schemat dopasowania używa przedrostka ^~, wyszukiwanie zatrzymuje się (podobnie jak wyżej)
-
dopasowanie do wyrażenia regularnego ma najniższy priorytet; istnieją dwa typy przedrostków: ~ i ~*; są przetwarzane w kolejności, w jakiej są zdefiniowane w pliku konfiguracyjnym
-
jeśli wyszukiwanie wyrażeń regularnych zwróciło poprawne dopasowanie, taka konstrukcja jest stosowana, w przeciwnym razie używane jest dopasowanie z wyszukiwania prefiksów
Spójrz na poniższy przykład:
location = / {
# Matches the query / only.
[ configuration A ]
}
location / {
# Matches any query, since all queries begin with /, but regular
# expressions and any longer conventional blocks will be
# matched first.
[ configuration B ]
}
location /documents/ {
# Matches any query beginning with /documents/ and continues searching,
# so regular expressions will be checked. This will be matched only if
# regular expressions don't find a match.
[ configuration C ]
}
location ^~ /images/ {
# Matches any query beginning with /images/ and halts searching,
# so regular expressions will not be checked.
[ configuration D ]
}
location ~* \.(gif|jpg|jpeg)$ {
# Matches any request ending in gif, jpg, or jpeg. However, all
# requests to the /images/ directory will be handled by
# Configuration D.
[ configuration E ]
}
W celu lepszego zrozumienia przetwarzania lokalizacji polecam następujące narzędzia:
Proces wyboru bloku lokalizacji NGINX jest następujący (szczegółowe wyjaśnienie):
1) NGINX szuka dokładnego dopasowania. Jeśli modyfikator =, np. location = foo {...}, dokładnie pasuje do identyfikatora URI żądania, ten konkretny blok lokalizacji jest wybierany od razu
- po spełnieniu warunku dopasowania ten blok jest przetwarzany
- przy spełnieniu powyższego warunku dalsze wyszukiwanie zostaje zatrzymane
2) Następnie wykonywane jest dopasowanie lokalizacji oparte na prefiksach (bez wyrażeń regularnych). Każda lokalizacja zostanie sprawdzona pod kątem identyfikatora URI żądania. Jeśli nie zostanie znaleziony dokładny (tzn. bez modyfikatora =) blok lokalizacji, NGINX będzie kontynuował wyszukiwanie z tzw. nieprecyzyjnymi prefiksami. Zaczyna od najdłuższego pasującego prefiksu dla tego identyfikatora URI, z następującym podejściem:
-
w przypadku, gdy najdłuższy pasujący prefiks ma modyfikator ^~, np.
location ^~ foo {...}, NGINX natychmiast przerwie wyszukiwanie i wybierze tę lokalizację- przetwarzanie trwa aż do znalezienia najdłuższego (najbardziej jednoznacznego) z tych dopasowań - przy spełnieniu powyższego warunku dalsze wyszukiwanie zostaje zatrzymane
-
zakładając, że najdłuższy pasujący prefiks nie używa modyfikatora ^~, dopasowanie jest tymczasowo przechowywane, a proces wyszukiwania jest kontynuowany
Nie jestem pewien co do tej kolejnośći. W oficjalnej dokumentacji nie jest to wyraźnie wskazane, a niektóre zewnętrzne przewodniki wyjaśniają to inaczej. Logiczne wydaje się sprawdzenie najpierw najdłuższego pasującego położenia prefiksu.
3) Gdy tylko zostanie wybrany i zapisany najdłuższy pasujący prefiks, NGINX kontynuuje ocenę rozróżniania wielkości liter (ang. case-sensitive regular expression), np. location ~ foo {...}, lub pomija ich rozróżnianie (ang. insensitive regular expression), np. location ~* foo {.. .}. Pierwsze wyrażenie regularne, które pasuje do identyfikatora URI, jest wybierane od razu do przetworzenia żądania
- przetwarzany jest blok pierwszego znalezionego wyrażenia regularnego (podczas analizowania pliku konfiguracyjnego od początku do końca)
- przy spełnieniu powyższego warunku dalsze wyszukiwanie zostaje zatrzymane
4) Jeśli nie zostaną znalezione odpowiednie wyrażenia regularne pasujące do identyfikatora URI żądania, poprzednio zapisana lokalizacja prefiksu (np. location foo {...}) zostanie wybrana do obsługi żądania
location /pozwala na obsługę wszystkich niepasujących nigdzie indziej lokalizacji- przetwarzany jest blok po znalezieniu najdłuższego (najbardziej jednoznacznego) z tych dopasowań
- przy spełnieniu powyższych warunków dalsze wyszukiwanie zostaje zatrzymane
Powinieneś także wiedzieć, że typy dopasowania inne niż wyrażenia regularne są w pełni deklaratywne — kolejność definicji w konfiguracji nie ma znaczenia, jednak „zwycięskie” dopasowanie wyrażeń regularnych (jeśli przetwarzanie nawet zajdzie tak daleko) jest całkowicie oparte na kolejności wprowadzenia ich w pliku konfiguracyjnym.
Aby lepiej zrozumieć, jak działa ten proces, zapoznaj się z poniższą tabelką, która pozwoli Ci zaprojektować bloki lokalizacji w przewidywalny sposób:

Na koniec, przykład trochę bardziej skomplikowanej konfiguracji:
server {
listen 80;
server_name xyz.com www.xyz.com;
location ~ ^/(media|static)/ {
root /var/www/xyz.com/static;
expires 10d;
}
location ~* ^/(media2|static2) {
root /var/www/xyz.com/static2;
expires 20d;
}
location /static3 {
root /var/www/xyz.com/static3;
}
location ^~ /static4 {
root /var/www/xyz.com/static4;
}
location = /api {
proxy_pass http://127.0.0.1:8080;
}
location / {
proxy_pass http://127.0.0.1:8080;
}
location /backend {
proxy_pass http://127.0.0.1:8080;
}
location ~ logo.xcf$ {
root /var/www/logo;
expires 48h;
}
location ~* .(png|ico|gif|xcf)$ {
root /var/www/img;
expires 24h;
}
location ~ logo.ico$ {
root /var/www/logo;
expires 96h;
}
location ~ logo.jpg$ {
root /var/www/logo;
expires 48h;
}
}
A oto niektóre z rezultatów:
| URL | LOCATIONS FOUND | FINAL MATCH |
|---|---|---|
/ |
1) prefix match for / |
/ |
/css |
1) prefix match for / |
/ |
/api |
1) exact match for /api |
/api |
/api/ |
1) prefix match for / |
/ |
/backend |
1) prefix match for /2) prefix match for /backend |
/backend |
/static |
1) prefix match for / |
/ |
/static/header.png |
1) prefix match for /2) case sensitive regex match for ^/(media\|static)/ |
^/(media\|static)/ |
/static/logo.jpg |
1) prefix match for /2) case sensitive regex match for ^/(media\|static)/ |
^/(media\|static)/ |
/media2 |
1) prefix match for /2) case insensitive regex match for ^/(media2\|static2) |
^/(media2\|static2) |
/media2/ |
1) prefix match for /2) case insensitive regex match for ^/(media2\|static2) |
^/(media2\|static2) |
/static2/logo.jpg |
1) prefix match for /2) case insensitive regex match for ^/(media2\|static2) |
^/(media2\|static2) |
/static2/logo.png |
1) prefix match for /2) case insensitive regex match for ^/(media2\|static2) |
^/(media2\|static2) |
/static3/logo.jpg |
1) prefix match for /static32) prefix match for /3) case sensitive regex match for logo.jpg$ |
logo.jpg$ |
/static3/logo.png |
1) prefix match for /static32) prefix match for /3) case insensitive regex match for .(png\|ico\|gif\|xcf)$ |
.(png\|ico\|gif\|xcf)$ |
/static4/logo.jpg |
1) priority prefix match for /static42) prefix match for / |
/static4 |
/static4/logo.png |
1) priority prefix match for /static42) prefix match for / |
/static4 |
/static5/logo.jpg |
1) prefix match for /2) case sensitive regex match for logo.jpg$ |
logo.jpg$ |
/static5/logo.png |
1) prefix match for /2) case insensitive regex match for .(png\|ico\|gif\|xcf)$ |
.(png\|ico\|gif\|xcf)$ |
/static5/logo.xcf |
1) prefix match for /2) case sensitive regex match for logo.xcf$ |
logo.xcf$ |
/static5/logo.ico |
1) prefix match for /2) case insensitive regex match for .(png\|ico\|gif\|xcf)$ |
.(png\|ico\|gif\|xcf)$ |
Fazy przetwarzania żądań #
Na tym temat moglibyśmy zakończyć jednak jest jeszcze jedna niezwykle istotna rzecz warta wspomnienia — fazy przetwarzania żądań HTTP.
Otóż idąc za oficjalną dokumentacją, każde żądanie HTTP przechodzi przez sekwencję faz gdzie w każdej fazie wykonywany jest inny rodzaj przetwarzania żądania. Fazy są przetwarzane jedna po drugiej, a odpowiednie metody obsługi faz są wywoływane, gdy żądanie dotrze do danej fazy. Poniżej znajduje się lista faz HTTP:
- NGX_HTTP_POST_READ_PHASE - pierwsza faza, w której czytany jest nagłówek żądania
- przykładowe moduły: ngx_http_realip_module
- NGX_HTTP_SERVER_REWRITE_PHASE - implementacja dyrektyw przepisywania zdefiniowanych w bloku serwera; w tej fazie m.in. zmieniany jest identyfikator URI żądania za pomocą wyrażeń regularnych (PCRE)
- przykładowe moduły: ngx_http_rewrite_module
-
NGX_HTTP_FIND_CONFIG_PHASE - zamieniana jest lokalizacja zgodnie z URI (wyszukiwanie lokalizacji)
- NGX_HTTP_REWRITE_PHASE - modyfikacja URI na poziomie lokalizacji
- przykładowe moduły: ngx_http_rewrite_module
- NGX_HTTP_POST_REWRITE_PHASE - przetwarzanie końcowe URI (żądanie zostaje przekierowane do nowej lokalizacji)
- przykładowe moduły: ngx_http_rewrite_module
- NGX_HTTP_PREACCESS_PHASE - wstępne przetwarzanie uwierzytelniania; sprawdzane są m.in. limity żądań oraz limity połączeń (ograniczenie dostępu)
- przykładowe moduły: ngx_http_limit_req_module, ngx_http_limit_conn_module, ngx_http_realip_module
- NGX_HTTP_ACCESS_PHASE - weryfikacja klienta (proces uwierzytelnienia, ograniczenie dostępu)
- przykładowe moduły: ngx_http_access_module, ngx_http_auth_basic_module
- NGX_HTTP_POST_ACCESS_PHASE - faza przetwarzania końcowego związana z ograniczaniem dostępu
- przykładowe moduły: ngx_http_access_module, ngx_http_auth_basic_module
- NGX_HTTP_PRECONTENT_PHASE - generowanie treści (odpowiedzi)
- przykładowe moduły: ngx_http_try_files_module
- NGX_HTTP_CONTENT_PHASE - przetwarzanie treści (odpowiedzi)
- przykładowe moduły: ngx_http_index_module, ngx_http_autoindex_module, ngx_http_gzip_module
- NGX_HTTP_LOG_PHASE - mechanizm logowania, tj. zapisywanie informacji do pliku z logami
- przykładowe moduły: ngx_http_log_module
Zrozumienie ich jest niezwykle istotne, ponieważ w języku NGINX kolejność pisania w pliku konfiguracyjnym może znacznie różnić się od kolejności wykonywania na ogólnej osi czasu przetwarzania, co zwykle dezorientuje wielu administratorów.
Zwykle moduły i ich polecenia rejestrują swoje wykonanie tylko w jednej z trzech faz: rewrite, access i content. Na przykład dyrektywa set działa w fazie przepisywania, a polecenie echo działa w fazie treści. Ponieważ pierwsza z wymienionych występuje zawsze przed fazą content, polecenia i dyrektywy w niej zawarte są również wykonywane wcześniej. Dlatego polecenie set zawsze jest wykonywane przed poleceniem „podłączonym” do fazy treści w ramach jednej dyrektywy location, niezależnie od kolejności ich wystąpienia w konfiguracji.
Co istotne, polecenia w różnych fazach nie mogą być wykonywane w tę i z powrotem a dwa, nie każde polecenie ma odpowiednią fazę. Przykładami są dyrektywy geo i map. Te polecenia, które nie mają wyraźnie stosowanej fazy, są deklaratywne i niezwiązane z koncepcją kolejności wykonywania. Inną ciekawą rzeczą jest to, że polecenia różnych modułów są wykonywane niezależnie od siebie, nawet jeśli wszystkie są zarejestrowane w tej samej fazie (wyjątkiem jest moduł ngx_set_misc, którego polecenia są specjalnie dostrojone za pomocą modułu ngx_rewrite, tak, aby były wykonane na samym końcu). Innymi słowy, każda faza przetwarzania jest dalej dzielona na mniejsze fazy przez moduły serwera NGINX.
Aby podejrzeć, w jakiej fazie wykonywane są konkretne polecenia, możesz wykorzystać tryb
debug(należy go włączyć podczas kompilacji).
Przygotowałem również proste wyjaśnienie, które pomoże ci zrozumieć, jakie moduły oraz dyrektywy są używane na każdym etapie:
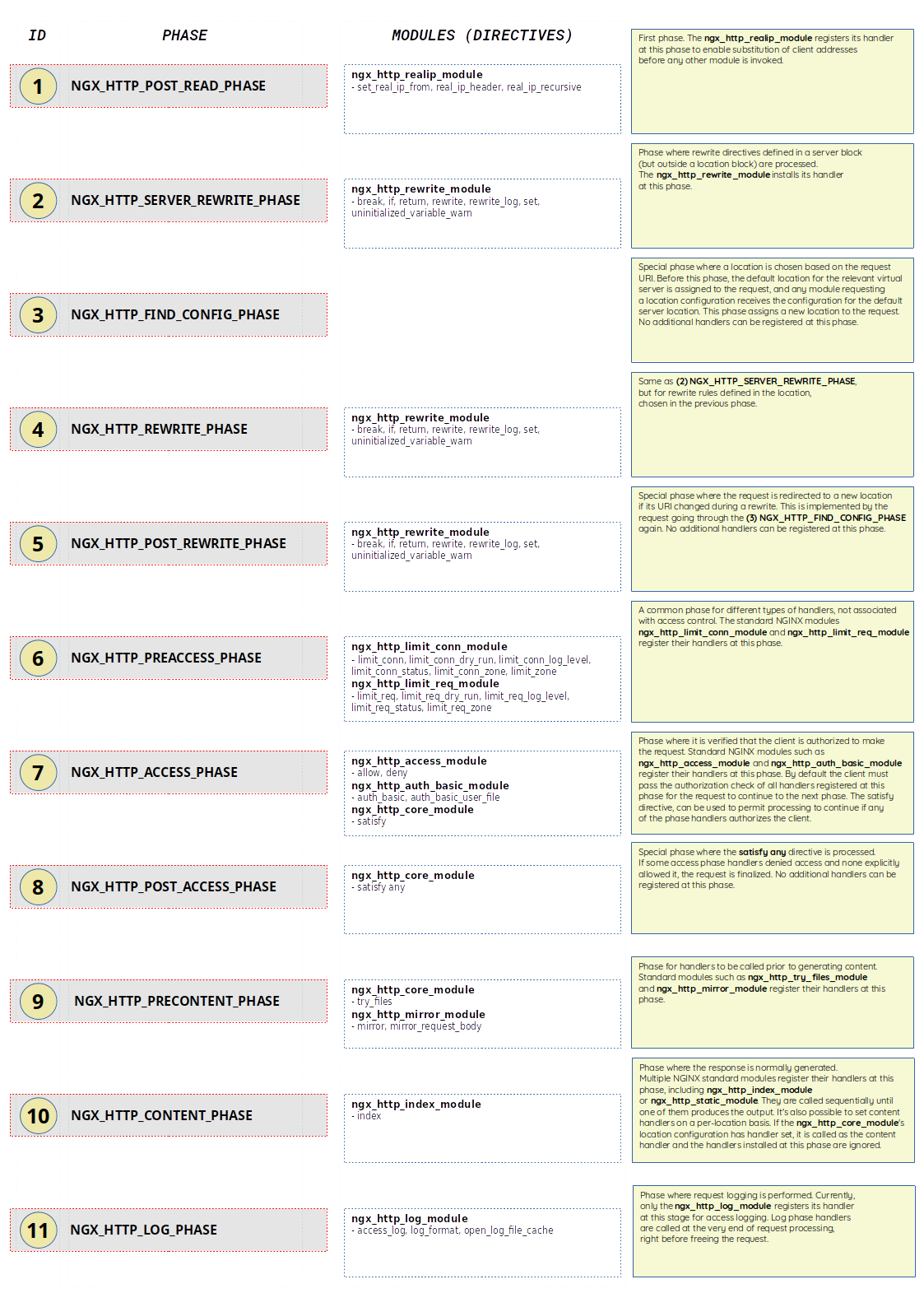
Dodatkowo każda z faz ma listę powiązanych z nią procedur obsługi. Co więcej, na każdej fazie można zarejestrować dowolną liczbę handlerów. Na przykład pisząc własny moduł w Lua możesz umieścić go w różnych fazach działania serwera, aby spełnić różne wymagania.
Polecam zapoznać się ze świetnym wyjaśnieniem dotyczącym faz przetwarzania żądań. Dodatkowo, w tym oficjalnym przewodniku także dość dokładnie opisano cały proces przejścia żądania przez każdą z faz.
Wracając jeszcze do wspomnianego przed chwilą kontekstu lokalizacji, to wszystkie polecenia ustawione w tym kontekscie są wykonywane w fazie przepisywania. W rzeczywistości prawie wszystkie polecenia implementowane przez przepisywanie są wykonywane w fazie przepisywania w określonym kontekście. Należy jednak mieć świadomość, że gdy niektóre polecenia zostaną znalezione w dyrektywie server, zostaną wykonane we wcześniejszej fazie, tj. w fazie przepisywania serwera.
Poniżej znajduje się znacznie prostszy podgląd, który pomoże zrozumieć omawiany temat:
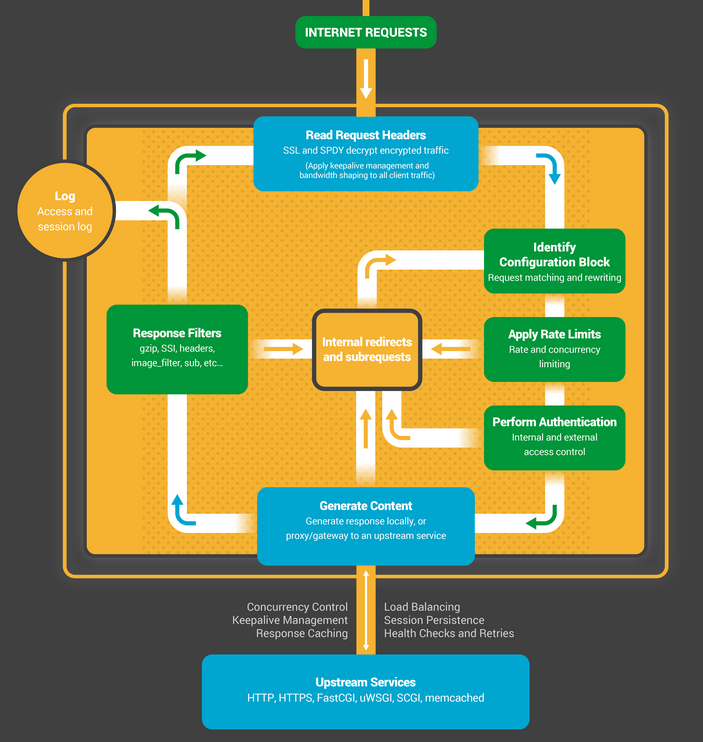
Polecam przeczytać świetne wyjaśnienie na temat faz przetwarzania żądań HTTP w NGINX i oczywiście oficjalny przewodnik dla developerów. Na koniec, koniecznie zapoznaj się z artykułem agentzh’s Nginx Tutorials (version 2020.03.19), który w świetny sposób wyjaśnia jak działają fazy przetwarzania serwera NGINX podająć przy okazji wiele pomocnych przykładów.