Interfejs loopback i różnica między 127.0.0.1 a localhost
25 Jul 2019
localhost loopback network sockets system tcp-ip
W tym wpisie chciałbym wyjaśnić różnicę między tymi dwoma oznaczeniami. Wydawać by się mogło, że jest ona minimalna, a nawet kosmetyczna, no i faktycznie tak jest. Myślę, że może to być ciekawa dyskusja także na temat tego, jak system operacyjny powinien rozwiązywać nazwę lokalnego hosta, i czy w ogóle powinien oraz, której nazwy używać w plikach konfiguracyjnych usług uruchamianych na serwerze zwłaszcza do komunikacji wewnętrznej (i czy w ogóle umieszczać).
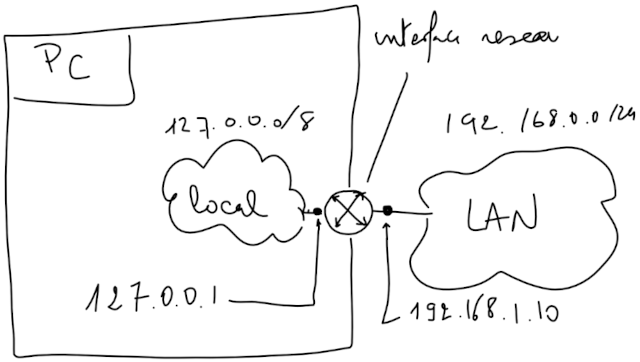
Czym jest interfejs loopback? #
Przed rozpoczęciem rozważań, warto wspomnieć, że oba terminy odnoszą się do specjalnego typu wirtualnego interfejsu, tzw. loopback. Interfejs ten jest częścią stosu TCP/IP i emuluje prawdziwy interfejs, stąd jest interfejsem wirtualnym traktowanym jako fikcyjne urządzenie (ang. dummy device) i zapewnia wymianę danych wewnątrz jednego hosta celem utrzymania ruchu w warstwie interfejsu. Mimo tego, że jest to pseudourządzenie, to stos sieciowy nadal wykonuje na nim wiele „standardowych” operacji.
Wykorzystując ten interfejs, dane wysłane przez protokół TCP/IP na adres tego interfejsu powinny zapętlić się z powrotem w hoście — a mówią najprościej, zakręcić ruch już na tym interfejsie (tak, jakbyś miał kartę sieciową z dwoma gniazdami i spiął je jednym kablem) bez przekazania go gdziekolwiek dalej (czyli wysłać go do samego siebie). Czyli cokolwiek, co do niego wyślesz, zostanie odebrane przez ten interfejs.
Wynikiem takiego zachowania jest odrobinę inna specyfika komunikacji, tj. komunikacja może odbywać się tylko na tym samym hoście. Proces, który nasłuchuje na połączeniach lokalnych, odbierze tylko połączenia lokalne na tym gnieździe. W obu przypadkach przejdzie tylko przez jądro, ponieważ do dowolnego adresu IP hosta można dotrzeć bez dotykania karty sieciowej.
Urządzenie loopback jest specjalnym wirtualnym interfejsem sieciowym, za pomocą którego urządzenie komunikuje się same ze sobą. Nie reprezentuje on żadnego rzeczywistego sprzętu, ale istnieje, więc aplikacje działające np. na serwerze mogą zawsze łączyć się z usługami na tym samym serwerze.
Zaletą interfejsu pętli zwrotnej jest też to, że nie jest on przypisany do żadnego interfejsu fizycznego, więc nie jest wrażliwy na flapowanie czy błędy pojawiające się na interfejsach fizycznych. Dlatego świetnie nadaje się do testowania, czy to lokalnego, czy to zdalnego. Na przykład sprawdza się podczas testowania protokołów routingu, dzięki czemu nie trzeba wpinać fizycznych sieci, wystarczy dodać odpowiedni loopback i sprawdzić jak trasa się rozpropaguje. Dzięki niemu można także założyć pętlę zdalną w celu przetestowania konkretnych odcinków transmisji.
Kolejną ciekawą cechą jest to, że jest on zawsze aktywny i dostępny, o ile trasa do tego interfejsu (adresu IP przypisanego do niego) jest dostępna w tabeli routingu (połączenia TCP/IP mają przypisaną trasę przez interfejs pętli zwrotnej) oraz dopóki samo urządzenie będzie włączone. Tak naprawdę będzie działał jeśli nie zostanie ręcznie zdezaktywowane przez administratora.
Dobrą dokumentacją są także źródła kernela a dokładniej plik dev.c:
The loopback device is special if any other network devices is present in a network namespace the loopback device must be present. Since we now dynamically allocate and free the loopback device ensure this invariant is maintained by keeping the loopback device as the first device on the list of network devices. Ensuring the loopback devices is the first device that appears and the last network device that disappears.
Oczywiście ten interfejs ma swój specjalny kawałek kodu, który znajduje się w pliku loopback.c, więc jeśli chcesz dowiedzieć się szczegółów technicznych, warto tam zajrzeć.
Inną ciekawostką jest, że przy wyborze stosu sieciowego (np. podczas kompilacji jądra), oczekuje się, iż urządzenie sprzężenia zwrotnego zawsze będzie istniało. Druga sprawa, także istotna wspomnienia, to to, że interfejs pętli zwrotnej ma podniesioną wartość MTU do 64K. Ma to na celu zwiększenie wydajności dla transferów lokalnych, ponieważ pozwala stosowi TCP budować większe ramki i znacznie zmniejsza obciążenie samego stosu. Z drugiej strony można mieć pewne wątpliwości co do tej wartości, ponieważ może dochodzić do marnowania buforów oraz pamięci (jednak myślę, że mimo wszystko jest to wartość optymalna dla tego typu interfejsu).
Adresacja dla interfejsu loopback #
Dobrze, a co z adresacją? No właśnie, ten typ interfejsu ma przydzielony blok adresów 127.0.0.0/8, który to został opisany w RFC 3330 [IETF]. Biorąc pod uwagę działanie interfejsu pętli zwrotnej, jeżeli wystąpi odwołanie do tej puli, to zawsze odnosi się ona do hosta lokalnego. Zwykle jest to realizowane za pomocą adresu 127.0.0.1/32, ale żadne adresy w tym bloku nie są rutowalne i nigdy nie powinny pojawiać się w żadnej sieci w dowolnym miejscu (na żadnym interfejsie sprzętowym podłączonym do kabla sieciowego). W przeciwnym razie mogą być na przykład zinterpretowane jako martians packets i odrzucone.
Dzięki takiemu zachowaniu możliwe jest spingowanie każdego adresu z tej puli:
ping 127.0.0.10 -c 1
PING 127.0.0.10 (127.0.0.10) 56(84) bytes of data.
64 bytes from 127.0.0.10: icmp_seq=1 ttl=64 time=0.045 ms
--- 127.0.0.10 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.045/0.045/0.045/0.000 ms
Niektóre systemy operacyjne, jak te z jądrem Linux, mogą traktować wszystkie adresy 127.0.0.1 - 127.255.255.255 tak samo, natomiast inne mogą działać tylko z adresem 127.0.0.1 (jak systemy BSD) i wymagają przynajmniej powiązania interfejsu z adresem docelowym, aby ping zakończył się powodzeniem.
Skąd takie zachowanie? Wynika to z tego, że adresy IP rozpoczynające się od 127 to adresy pętli zwrotnych, których można użyć do pingowania lokalnego (własnego) urządzenia, ponieważ cały ten zakres zarezerwowany jest dla interfejsu pętli zwrotnej, zgodnie z definicją zawartą w RFC 1700 [IETF]. Ważne wspomnienia jest też to, że chociaż 127/8 jest zastrzeżone, inny dokument, tj. RFC 5735 - 3. Global and Other Specialized Address Blocks (podobnie zresztą jak wspomniane RFC 3330), nie zabrania jawnie używania pozostałych adresów z tej puli i określa, że jest to zazwyczaj realizowane przy użyciu 127.0.0.1/32 (co nie oznacza „nie używaj innych adresów”):
127.0.0.0/8 - This block is assigned for use as the Internet host loopback address. A datagram sent by a higher-level protocol to an address anywhere within this block loops back inside the host. This is ordinarily implemented using only 127.0.0.1/32 for loopback. As described in [RFC 1122], Section 3.2.1.3, addresses within the entire 127.0.0.0/8 block do not legitimately appear on any network anywhere.
Do czego jednak może to być przydatne? 127/8 może być wykorzystywana do wielu rzeczy, np. do symulowania dużej liczby urządzeń (dużej sieci) bez użycia maszyn wirtualnych czy do uruchomienia większej ilości usług na tych samych portach (serwery HTTP działające na porcie 80), dzięki czemu pozwala na uruchomienie większej ilości usług, niż pozwalają na to domyślne limity (tj. równe maksymalnej ilości portów).
Standardy sieciowe IPv4 rezerwują cały blok adresu 127.0.0.0/8 na potrzeby sprzężenia zwrotnego. Oznacza to, że każdy pakiet wysłany na jeden z 16 777 214 adresów (od 127.0.0.1 do 127.255.255.254) trafia na interfejs loopback. IPv6 ma tylko jeden adres, tj. ::1.
W takim razie, czy adres 127.0.0.1 jest tym samym co 127.0.0.2? Nie. Według RFC 5735 może tak być, ale nie musi. Jest to zachowanie zdefiniowane w ramach implementacji danego systemu operacyjnego. Oba są oczywiście adresami lokalnymi powiązanymi z interfejsem loopback, jednak nie są takie same. Możesz użyć każdego adresu, aby powiązać inną usługę z tym samym portem, np. 20 000 serwerów HTTP na porcie 80, dostępne tylko z komputera lokalnego (oczywiście jeśli nie zabraknie pamięci lub innych zasobów). Istotne i w większości niezależne od implementacji, jest jednak to, że cały zakres jest zarezerwowany i nie może być kierowany przez sieć.
Pojawia się jeszcze inne pytanie warte rozważenia, otóż, dlaczego akurat wybór padł na adres 127.0.0.1, a nie inny? Nie znalazłem niestety jasnego wyjaśnienia takiego wyboru. Adres ten jest pierwszym adresem w ostatniej sieci klasy, A więc bardzo prawdopodobne, że to mogło być powodem. Istnieje wprawdzie wzmianka, jednak nie tłumaczy wprost o takim, a nie innym wyborze, która znajduje się w RFC 990 - Network Numbers:
The address zero is to be interpreted as meaning "this", as in "this network". [...] The class A network number 127 is assigned the "loopback" function, that is, a datagram sent by a higher level protocol to a network 127 address should loop back inside the host. No datagram "sent" to a network 127 address should ever appear on any network anywhere.
Przejdźmy dalej. Skoro wspomniałem wcześniej o pliku hosts to teraz warto powiedzieć o nim trochę więcej. Ma on najwyższy priorytet (tak naprawdę kolejność rozwiązywania nazw zdefiniowana jest w pliku nsswitch.conf), co oznacza, że jest on preferowany przed jakimkolwiek innym systemem nazw. Jednak jako pojedynczy plik nie skaluje się dobrze, ponieważ jego rozmiar bardzo szybko staje się zbyt duży i trudny w utrzymaniu. Właśnie dlatego opracowano hierarchiczny rozproszony system nazw, który pozwala każdemu hostowi efektywnie znaleźć adres numeryczny innego hosta. Oczywiście plik hosts jest nadal używany. Jego głównym dzisiejszym zastosowaniem jest ominięcie rozpoznawania nazw za pomocą DNS. Jeśli sieć lokalna jest wystarczająco duża lub po prostu dzieli się na różne podsieci, lub z jakiegokolwiek innego przydatnego powodu, DNS jest preferowany.
Adres, który otrzymujesz w wyniku rozwiązania nazwy localhost zależy od konfiguracji DNS i jest domyślnie odwzorowany na 127.0.0.1. To mapowanie najczęściej odbywa się z poziomu specjalnego pliku, tj.
/etc/hostsw systemach UNIX.
Wróćmy jednak do głównego tematu. W przypadku IPv4 interfejsowi pętli zwrotnej są przypisywane wszystkie adresy IP w bloku adresu 127.0.0.1/8. Oznacza to, że od 127.0.0.1 do 127.0.0.254 wszystkie reprezentują lokalny komputer. Jednak w większości przypadków konieczne jest użycie tylko jednego adresu, czyli 127.0.0.1. Ten adres IP ma przypisaną fikcyjną nazwę hosta localhost, która jest zastrzeżona i przeznaczona tylko dla niego.
Idąc za tym:
- 127.0.0.1 to adres IPv4 do urządzenia (komputera) lokalnego
- localhost to nazwa wyszukiwana w celu znalezienia adresów lokalnego urządzenia
Mając przydzielony standardowy adres 127.0.0.1/32 użycie polecenia ping spowoduje, że maszyna zacznie pingować samą siebie.
Na koniec tego rozdziału, w ramach ciekawowstki, spójrz na to:
ping 127.1 -c 1
PING 127.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.031 ms
--- 127.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.031/0.031/0.031/0.000 ms
Dlaczego tak się dzieje? Jest to znana właściwość związana z funkcją inet_aton(), która przekształca oktety na adres binarny — czyli pozwala na zapisanie adresu IP na kilka sposobów, zwłaszcza na pominięcie zer. Podana notacja została natomiast opisana w drafcie Textual Representation of IPv4 and IPv6 Addresses.
Jest to tak naprawdę mało znany szczegół parsowania adresu IPv4. Jeśli w adresie podano mniej niż cztery części, ostatnia część jest traktowana jako liczba całkowita o takiej liczbie bajtów, ile potrzeba do wypełnienia adresu do czterech bajtów. Zatem:
- 127.1 jest taki sam jak 127.0.0.1
- 127.1.1 jest taki sam jak 127.1.0.1
Co więcej, poniższy zapis jest także prawidłowy (w systemie z jądrem Linux):
ping 0 -c 1
PING 0 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.026 ms
--- 0 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.026/0.026/0.026/0.000 ms
Jednak wykonanie tej samej komendy w systemie FreeBSD powoduje przekierowania ruchu na 0.0.0.0, czyli tzw. routing zerowy (ang. null-route).
Czy istnienie interfejsu loopback jest wymagane? #
Tak, ponieważ posiadanie włączonego i skonfigurowanego interfejsu pętli zwrotnej niesie wiele korzyści:
-
umożliwia posiadanie adresu IP i jest niezależny od interfejsów fizycznych
-
ten typ interfejsów świetnie nadaje się do celów diagnostycznych, przy rozwiązywaniu problemów oraz do testowania usług uruchomionych na serwerze
-
interfejs sprzężenia zwrotnego służy do identyfikacji urządzenia mimo tego, że do ustalenia, czy urządzenie jest włączone, można użyć dowolnego adresu interfejsu, preferowanym sposobem jest adres sprzężenia zwrotnego
-
można go użyć do powiązania adresu IP pętli zwrotnej z przypisaną nazwą hosta, dzięki czemu serwer jest zawsze dostępny za pośrednictwem swojej nazwy DNS
-
adres sprzężenia zwrotnego jest używany przez protokoły, takie jak OSPF, do określania właściwości specyficznych dla protokołu, urządzenia lub sieci
-
interfejs ten jest często wymagany podczas komunikowania się usług na serwerze, także w celu zwiększenie bezpieczeństwa. Pamiętajmy, że wystawianie usług na adresach IP interfejsów innych niż loopback nie jest zalecane i może być niebezpieczne bez zachowania odpowiednich środków ostrożności
127.0.0.1 vs localhost #
Szukając za różnicami, znalazłem informację, że localhost oznacza lokalne połączenie przez gniazdo, podczas gdy 127.0.0.1 wykorzystuje do tego celu TCP/IP. Faktem jest, że gniazda są nieco szybsze niż korzystanie z protokołów TCP/IP (ze względu na mniejszy narzut). Można wyciągnąć z tego wniosek, że jeśli zdecydujesz się na użycie gniazd, dobrym pomysłem może okazać się powiązanie gniazda z localhost, ponieważ na większości platform odnosi się to do kilku warstw kodu sieciowego i będzie nieco szybsze.
Nie mogę zgodzić się z pierwszym zdaniem (jednak możliwe, że albo czegoś nie zrozumiałem, albo za mało szukałem). Wykonajmy dwa testowe pingi i podepnijmy się pod nie narzędziem strace. Oto wyniki (dosyć mocno obcięte), pierwszy przy wykorzystaniu 127.0.0.1:
execve("/bin/ping", ["ping", "-c", "1", "127.0.0.1"], [/* 24 vars */]) = 0
getsockname(4, {sa_family=AF_INET, sin_port=htons(47968), sin_addr=inet_addr("127.0.0.1")}, [16]) = 0
real 0m0.024s
user 0m0.005s
sys 0m0.018s
Drugi, wykorzystujący localhost:
execve("/bin/ping", ["ping", "-c", "1", "localhost"], [/* 24 vars */]) = 0
socket(AF_LOCAL, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, 0) = 4
connect(4, {sa_family=AF_LOCAL, sun_path="/var/run/nscd/socket"}, 110) = -1 ENOENT (No such file or directory)
open("/etc/nsswitch.conf", O_RDONLY|O_CLOEXEC) = 4
stat("/etc/resolv.conf", {st_mode=S_IFREG|0644, st_size=95, ...}) = 0
open("/etc/host.conf", O_RDONLY|O_CLOEXEC) = 4
open("/etc/resolv.conf", O_RDONLY|O_CLOEXEC) = 4
open("/etc/hosts", O_RDONLY|O_CLOEXEC) = 4
socket(AF_INET, SOCK_DGRAM|SOCK_CLOEXEC, IPPROTO_IP) = 4
connect(4, {sa_family=AF_INET, sin_port=htons(0), sin_addr=inet_addr("127.0.0.1")}, 16) = 0
getsockname(4, {sa_family=AF_INET, sin_port=htons(43294), sin_addr=inet_addr("127.0.0.1")}, [16]) = 0
stat("/etc/resolv.conf", {st_mode=S_IFREG|0644, st_size=95, ...}) = 0
open("/etc/hosts", O_RDONLY|O_CLOEXEC) = 4
read(4, "127.0.0.1 localhost localhost."..., 4096) = 494
write(1, "64 bytes from localhost (127.0.0"..., 6964 bytes from localhost (127.0.0.1): icmp_seq=1 ttl=64 time=0.078 ms
) = 69
real 0m0.042s
user 0m0.002s
sys 0m0.022s
Widzimy, że w drugim przypadku nazwa rozwiązywana jest na adres IP, stąd także do komunikacji wykorzystany zostanie stos protokołów TCP/IP, a nie mechanizm gniazd. Poza tym, w przypadku niektórych usług, tj. Postgres, jeśli wskażemy połączenie z wykorzystaniem localhost, zostanie użyty interfejs loopback TCP/IP:
time PGOPTIONS="-c log_min_duration_statement=0 \
-c client_min_messages=log" psql -h localhost <<END
\timing
SELECT 1;
END
W przeciwnym razie, jeśli nie określisz niczego, użyte zostaną gniazda domeny UNIX:
time PGOPTIONS="-c log_min_duration_statement=0 \
-c client_min_messages=log" psql <<END
\timing
SELECT 1;
END
Można zauważyć, że użycie localhost jest bardziej zasobochłonne, ponieważ trzeba rozwiązać tę nazwę w celu uzyskania adresu IP — stąd nazwa ta nie jest żadnym specjalnym odwzorowaniem gniazd. W przeciwnym razie nie zostałoby utworzone żadne połączenie TCP, więc nie trzeba by rozpoznawać nazwy hosta. W tym miejscu warto się zatrzymać i rozwinąć temat bardziej.
Gniazda UNIX vs TCP/IP #
Gniazda domeny UNIX (ang. UNIX domain sockets) są formą komunikacji międzyprocesowej (IPC, ang. Inter-process communication), czyli zapewniają mechanizmy komunikacji między procesami (dwukierunkową komunikację punkt-punkt) i umożliwiają dwukierunkową wymianę danych. Używają systemu plików jako przestrzeni nazw adresów, co oznacza, że możliwe jest użycie standardowych uprawnień do plików do kontrolowania dostępu do komunikacji z nimi. Ma to ogromną zaletę, ponieważ dzięki temu można w prosty sposób (na poziomie uprawnień systemu plików) ograniczyć połączenia do demona wykorzystującego takie gniazdo (natomiast gniazdami TCP można sterować tylko na poziomie filtru pakietów). Co ciekawe, cały faktyczny transfer danych odbywa się całkowicie w pamięci.
Pliki gniazd są plikami specjalnymi, w tym sensie, że istnieją w systemie plików jak zwykłe pliki (stąd mają i-węzeł i metadane oraz związane z nim uprawnienia), ale będą odczytywane i zapisywane za pomocą funkcji
recv()isend()zamiastread()iwrite(). Dlatego podczas wiązania i łączenia się z takim gniazdem będziemy używać ścieżek plików zamiast adresów IP i portów.
Ponadto musimy wiedzieć, że ten typ gniazd wykonuje się w obrębie tego samego systemu i bez dodatkowego przełączania kontekstu. Wątek wysyłający zapisuje strumień lub datagramy bezpośrednio w buforze gniazda odbiorczego. Nie są też obliczane żadne sumy kontrolne, nie są wstawiane nagłówki, nie jest też przeprowadzane trasowanie itd. Pomijamy też potrzebę dostrojenia wielu specyficznych dla TCP parametrów jądra, co eliminuje wiele potencjalnych wąskich gardeł, które należy rozwiązać, stosując odpowiednie ustawienia konfiguracji i testy porównawcze.
Aby wyświetlić procesy wykorzystujące ten typ gniazda, możesz użyć poniższego polecenia:
netstat -a -p --unix
Inaczej wygląda sprawa w przypadku gniazd TCP/IP, które umożliwiają połączenia z usługą zdalną. W wyniku komunikacji między procesami w sieci rosną jednak wymagania co do zapewnienia dodatkowego bezpieczeństwa (np. na poziomie firewalla). Oczywiście nadal można używać gniazd TCP/IP do komunikowania się z procesami uruchomionymi na tym samym komputerze (za pomocą interfejsu pętli zwrotnej), jednak komunikacja wykorzystująca takie gniazda zawsze wymaga dwóch przełączeń kontekstu, aby dostać się do gniazda zdalnego. Ponadto pamiętajmy o całym narzucie TCP, tj. potwierdzaniu ACK, kontroli przepływu czy enkapsulacji i dekapsulacji z sąsiednich warstw stosu.
Co więcej, w celu dostarczenia danych do systemu lokalnego podejmowane są decyzje związane z dostarczaniem na podstawie tablicy routingu. Jeżeli przesyłamy naprawdę duże ilości danych, są one obejmowane tymi samymi mechanizmami jak w przypadku komunikacji zdalnej, tj. muszą one zostać podzielone na datagramy równe wielkości MTU (ang. Maximum Transmission Unit). Gniazda TCP/IP mają natomiast tę zaletę, że zapewniają natychmiastową przenośność i niezależność od lokalizacji.
Pamiętajmy jednak, że interfejs sprzężenia zwrotnego to wciąż TCP, co oznacza, że nadal istnieje narzut specyficzny dla tego protokołu (kontrola przeciążenia, kontrola przepływu czy zarządzanie strumieniem, tj. pilnowanie kolejności pakietów IP, retransmisja itp.). Gniazda domen UNIX nie spełniają żadnej z powyższych funkcji, ponieważ zostały zaprojektowane od podstaw do uruchamiania lokalnego, co oznacza brak problemów z przeciążeniem, brak różnic prędkości między serwerem/klientem wymagającymi kontroli przepływu, czy brak zagubionych po drodze pakietów.
Podsumowując, jeśli korzystasz z gniazd domeny UNIX, nie będzie potrzeby przejścia przez wszystkie wymagane protokoły sieciowe. Gniazda są identyfikowane wyłącznie przez i-węzły na dysku twardym.
Co z wydajnością? #
W zależności od platformy ten drugi typ gniazd może osiągnąć około 50% większą przepustowość niż interfejs loopback. Co ciekawe, typowe opóźnienie w sieci 1 Gbit/s wynosi około 200 us, podczas gdy opóźnienie w przypadku gniazda domeny Unix może wynieść jedynie 30 us. W rzeczywistości zależy to od sieci i wykorzystywanego sprzętu. Jeżeli rozmawiamy o wydajności obu technik, musimy pamiętać, że oprócz samej komunikacji, system także dodaje trochę swoich opóźnień (z powodu planowania wątków, pamięci podręcznej procesora, itp.). Opóźnienia wywołane przez system są znacznie większe w środowisku zwirtualizowanym niż na komputerze fizycznym.
Spójrz także na poniższy zrzut przedstawiający testy porównawcze przepustowości każdego z rozwiązań:
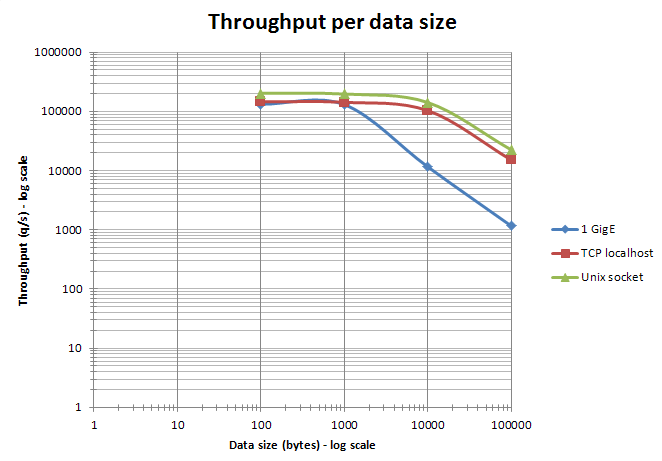
Świetne wyjaśnienie znajduje się w artykule How fast are Unix domain sockets?. Zerknij tam koniecznie jeśli chcesz przeprowadzić własne testy porównawcze. Ponadto polecam zajrzeć do artykułów Need to Connect to a Local MySQL Server? Use Unix Domain Socket! oraz Postgres Blog: Timing a Query, w których pokazano więcej pomiarów obu typów połączeń.
Z drugiej strony pamiętajmy, że większość współczesnych jąder ma zoptymalizowane ścieżki (ang. short-circuit) dla lokalnych połączeń TCP, dzięki czemu narzut dodatkowego protokołu (spadek wydajności) nie powinien być aż tak znaczący. Jednak podczas niektórych testów jest wyraźny. Pamiętajmy, że gniazda UNIX są w rzeczywistości dość prostą rzeczą. Urządzenie sprzężenia zwrotnego (tj. interfejs loopback) jest znacznie bardziej skomplikowane, dlatego moim zdaniem narzut jest oczywisty.
Wracając do tematu tego artykułu, czyli co jest lepsze, można to wyjaśnić za pomocą najistotniejszej moim zdaniem różnicy między nimi (głównie jeśli chodzi o wydajność). Przy używaniu localhost wciąż trzeba tę nazwę gdzieś faktycznie sprawdzić (rozwiązać). Dlatego jeśli użyjesz tego powyższego nazewnictwa, oprogramowanie na twoim serwerze po prostu zamieni je bezpośrednio na adres IP i użyje go, w przeciwnym razie, nazwa będzie musiała zostać rozwiązana.
Częstym powodem wykorzystania notacji numerycznej, jest brak pewności, że nazwa domenowa faktycznie rozwiąże się na lokalny adres interfejsu pętli zwrotnej. Dlatego twórcy aplikacji na stałe koduję adres 127.0.0.1 aby być pewnym uzyskania adresu lokalnego.
I tak, nazwa ta może być rozwiązana za pomocą serwera DNS. Jednak lepszym, ze względu na szybkość i bezpieczeństwo, pomysłem jest rozwiązanie jej wewnętrznie (najczęściej z poziomu pliku /etc/hosts centralnego resolwera). Zapobiega to także nadmiernemu użyciu zewnętrznych serwerów DNS, ponieważ znaczna większość żądań jest generowana dla interfejsu pętli zwrotnej, tj. podczas komunikacji wewnętrznej.
Dodatkowe zasoby #
- Let ‘localhost’ be localhost [IETF]
- Understanding the Loopback Interface
- The Loopback Interface
- The Linux Kernel, Chapter 10: Networks
- UNIX System Calls and Subroutines using C - IPC:Sockets
- An Introductory 4.4BSD Interprocess Communication Tutorial [PDF]
- An Advanced 4.4BSD Interprocess Communication Tutorial [PDF]
- Programmation Systèmes Cours 9 — UNIX Domain Sockets