NGINX: Optymalizacja sesji SSL/TLS
21 Jul 2019
best-practices buffer cache http https nginx performance session ssl tickets tls
Optymalizacja sesji SSL/TLS powinna być jednym z ważniejszych kroków, które należy wykonać, w celu poprawienia ogólnych wrażeń użytkowników podczas korzystania z aplikacji internetowych. Dotyczy to zwłaszcza aplikacji wymagających pełnego uzgadniania protokołu TLS dla każdego połączenia sieciowego, które potrafi wprowadzić zauważalne opóźnienia. To właśnie opóźnienia powodują najwięcej problemów, ponieważ wydłużają czasy odpowiedzi i obniżają ogólną wydajność, a w konsekwencji wpływają na szybkość reakcji aplikacji webowej.
Poprawienie wydajności to niekończąca się podróż, ponieważ zawsze istnieje jakiś element do zmiany lub coś nowego do przetestowania. Nie ma też jednego zalecenia, ponieważ wiele zależy od rodzaju danych, częstotliwości zmian i oczekiwań klientów. W tym wpisie rozmawiać będziemy jedynie o niektórych parametrach protokołu SSL/TLS, które możemy zmodyfikować z poziomu serwera NGINX.
Zanim przeglądarka internetowa będzie mogła bezpiecznie wymieniać dane aplikacji z serwerem sieciowym, takie jak żądania i odpowiedzi protokołu HTTP, musi najpierw ustalić parametry kryptograficzne bezpiecznej sesji. Proces ten jest kluczowym i nieodłącznym elementem podczas zestawiania szyfrowanego połączenia, a co istotne, jednym z wykonywanych najdłużej (może zająć nawet 3/4 całego czasu od momentu wysłania żądania do otrzymania faktycznych danych!) podczas nawiązywania sesji między obiema stronami komunikacji.
Nie ma niestety jednoznacznych odpowiedzi, które dotyczą ustawienia odpowiednich czy optymalnych wartości parametrów sesji. Strojenie ich jest trudne, ponieważ ciężko jest uzyskać odpowiedź na pytania, jakich wartości należy użyć, w przypadku n klientów lub jakie wartości są odpowiednie dla danego środowiska. Aby jeszcze bardziej skomplikować sprawę, pamiętajmy, że obecnie najczęściej wykorzystywane protokoły, tj. TLSv1.2 i TLSv1.3 posiadają pewne różnice. Co więcej, nie ma jednego standardu i różne projekty dyktują różne ustawienia.

Faktem natomiast jest, że domyślna konfiguracja sesji SSL/TLS w NGINX nie jest optymalna. Na przykład wbudowana pamięć podręczna może być używana tylko przez jeden proces roboczy, co może powodować fragmentację pamięci, dlatego o wiele lepiej jest używać jej współdzielonej wersji. Zmiana tego ustawienia ma oczywiście wpływu bezpośrednio na klienta, oraz co istotne, jest ważnym elementem poprawiającym działanie samego serwera. Optymalizacji powinny podlegać także dodatkowe parametry tj. odpowiedzialne za rozmiar rekordów czy czas utrzymywania sesji w pamięci podręcznej.
Drugim przykładem może być stosowanie mechanizmu wznawiania sesji, w celu zmniejszenia kosztów obliczeń i podróży komunikatów w obie strony. Technika wznawiania polega na przechowywaniu oraz udostępnianiu tych samych wynegocjowanych parametrów między wieloma połączeniami, eliminując potrzebę pełnego uzgadniania dla każdego nowego połączenia. Projektanci protokołu TLS byli świadomi, że wykonanie pełnej negocjacji jest dość kosztowne, ponieważ wymaga dwóch obiegów (cztery komunikaty), a także zasobożernych operacji kryptograficznych. Wznowienie sesji jest ważnym elementem optymalizacyjnym, ponieważ skrócony uścisk dłoni pozwala uniknąć pełnego uzgadniania (które może być nawet 8x wolniejsze niż zgoda na ponowne użycie klucza poprzedniej sesji) dla większości żądań, eliminując opóźnienia i znacznie zmniejszając koszty obliczeniowe dla obu stron.
Choć wydaje się głupie, że klient i serwer, które niedawno się komunikowały, muszą wielokrotnie przechodzić przez ten pełny proces, to w niektórych przypadkach nie da się go zoptymalizować, ponieważ wiążą się z tym pewne problemy, zwłaszcza związane z bezpieczeństwem. W niektórych przypadkach zaimplementowanie mechanizmu wznawiania umożliwia wykorzystanie techniki zwanej atakiem przedłużającym (ang. Prolongation Attack), który w dużym skrócie, polega na śledzeniu użytkowników na podstawie mechanizmu (danych) wznawiania sesji TLS (spójrz na pracę Tracking Users across the Web via TLS Session Resumption [PDF]). Od razu też pojawia się pytanie, w jaki sposób skorzystać z funkcji PFS (ang. Perfect Forward Secrecy), dla której musimy zapewnić, że użyty materiał kryptograficzny związany z TLS nie będzie w żaden sposób przechowywany? Widzimy, że zaburza to ideę mechanizmu wznawiania.
W rzeczywistości, typowe serwery internetowe zamykają połączenia po kilkunastu sekundach bezczynności, ale będą pamiętać sesje (zestaw szyfrów i klucze) znacznie dłużej — prawdopodobnie przez godziny lub nawet dni.
Rozmawiając o mechanizmie wznawiania, moim zdaniem, należy zrównoważyć wydajność (nie chcemy, aby użytkownicy używali pełnego uzgadniania przy każdym połączeniu) i bezpieczeństwo (nie chcemy zbytnio narażać komunikacji TLS na szwank).
Natomiast jeśli chodzi o proces optymalizacji, to istnieją tak naprawdę dwa obszary, którym należy się szczególnie przyjrzeć:
-
nawiązanie bezpiecznego połączenia - przed nawiązaniem przez przeglądarkę bezpiecznego połączenia z witryną należy wykonać kilka kroków: potwierdzić tożsamość, wybrać algorytmy i wymienić klucze. Jest to znane jako uzgadnianie TLS i może mieć znaczący wpływ na wydajność
-
szyfrowanie danych - dane przesyłane tam i z powrotem między przeglądarką a serwerem sieciowym muszą być szyfrowane i odszyfrowane. Jeśli serwer nie zostanie poprawnie skonfigurowany, czas ładowania strony może być znacznie wolniejszy niż stosując ruch niezaszyfrowany
Należy mieć także świadomość, że optymalizacja sesji SSL/TLS nie jest jedynym elementem, ponieważ istnieją inne, równie ważne (jeśli nie ważniejsze) kroki, które poprawiają ogólną wydajność aplikacji webowej. Możemy zaliczyć do nich włączenie protokołu HTTP/2 lub QUIC+HTTP/3, zastosowanie mechanizmów pamięci podręcznej, stosowanie usługi CDN, która może uprościć wszelkie optymalizacje (zerknij do artykułu How does a CDN improve load times?), optymalizacja połączeń do bazy czy po prostu optymalizacja kodu. Kluczowe, jeśli nie najważniejsze z tego wszystkiego jest jednak dostarczanie treści w taki sposób, aby zapewnić minimalną ilości danych, które będzie musiał pobrać klient.
Oczywiście opisane w tym artykule porady nie są jedynymi zalecanymi wskazaniami dla protokołów SSL/TLS i to nie tylko jeśli chodzi o wydajność, ale także o bezpieczeństwo. Po drugie, pamiętaj też, że obsesja na punkcie wartości i skrupulatnego dostrajania parametrów opisanych w tym artykule, jest zdecydowanie czymś przesadzonym, ponieważ jak już wspomniałem, wydajność połączenia zależy od wielu czynników.
Narzut protokołu TLS #
Moim zdaniem, aplikacji nie można uznać za wydajną, dopóki nie będzie dobrze działać w oczach użytkownika. Wymaga to uwzględnienia kanału dostarczania, obejmującego sieć, szyfrowanie, optymalizację sieci WAN itp. — czyli wszystkich tych elementów, które znajdują się między aplikacją a użytkownikiem. Mierzenie czasu odpowiedzi kodu w punkcie wejścia serwera aplikacji nie tworzy pełnego obrazu bez uwzględnienia złożoności sieci i kanału dostarczania aplikacji. Tam, gdzie opóźnienia występują w dziesiątkach lub setkach milisekund, różne wąskie gardła występujące po drodze tylko potęgują problem. W tym miejscu polecam zapoznać się z rewelacyjną pracą Optimizing web servers for high throughput and low latency, w której opisano wiele różnych możliwości optymalizacji.
Ponieważ HTTPS stał się de facto standardem całej komunikacji internetowej w ciągu ostatnich kilku lat, ten dodatkowy koszt zapewnienia bezpieczeństwa sieci jest niezbędnym, ale problematycznym elementem. Uzgadnianie TLS wymaga dwóch przejść w obie strony, powodując wzrost nawet o 300 ms na każdą nową sesję HTTPS. W połączeniu z rozwiązywaniem nazw i czasem połączenia TCP może minąć znacznie ponad 500 ms, zanim będzie możliwe przesłanie pierwszego bajta danych. Według badania przeprowadzonego przez inżynierów firmy Microsoft, przedstawionego w dokumencie Seven Rules of Thumb for Web Site Experimenters, dodatkowe 250 ms opóźnienia spowodowało spadek przychodów wyszukiwarki bing o półtora procenta. Pamiętaj jednak, że są to w pewnym sensie puste wartości, a wszystko zależy od architektury środowiska i jej komponentów.
W przypadku wdrożenia protokołu HTTPS musimy niestety mieć świadomość pojawiającego się opóźnienia. Dzieje się tak, ponieważ (jak już wspomniałem) początkowe uzgadnianie TLS wymaga dwóch dodatkowych obiegów przed ustanowieniem faktycznego połączenia, w porównaniu do jednego przejścia z wykorzystaniem niezaszyfrowanego protokołu HTTP. Ze względu na różnicę między opóźnieniem a przepustowością (pamiętaj, że opóźnienie to czas potrzebny do pokonania ścieżki z jednego miejsca do drugiego, natomiast przepustowość to ilość danych, które można równolegle przenieść wzdłuż tej ścieżki) szybsze połączenia internetowe nie przyspieszą tych obiegów, a samo uzgadnianie może trwać od 250 milisekund nawet do kilku sekund. Widzimy, że ten proces, choć konieczny, może mieć wpływ na wydajność, opóźniając pobieranie krytycznych zasobów, takich jak początkowa strona HTML. Inżynierowie Dynatrace, podczas testów wydajnościowych w jednym ze swoich systemów, wykryli, że pełne uzgadnianie TLS trwa średnio 4x dłużej niż rzeczywista wymiana danych wykorzystująca szyfrowane połączenie! Musimy też wiedzieć, że uścisk dłoni protokołu TLS ma jeszcze większe znaczenie na długich dystansach.
Spójrzmy na poniższą grafikę, która w prosty sposób porównuje najnowsze wersje protokołu TLS w kontekście ilości wymienianych komunikatów podczas ustanawiania połączenia:
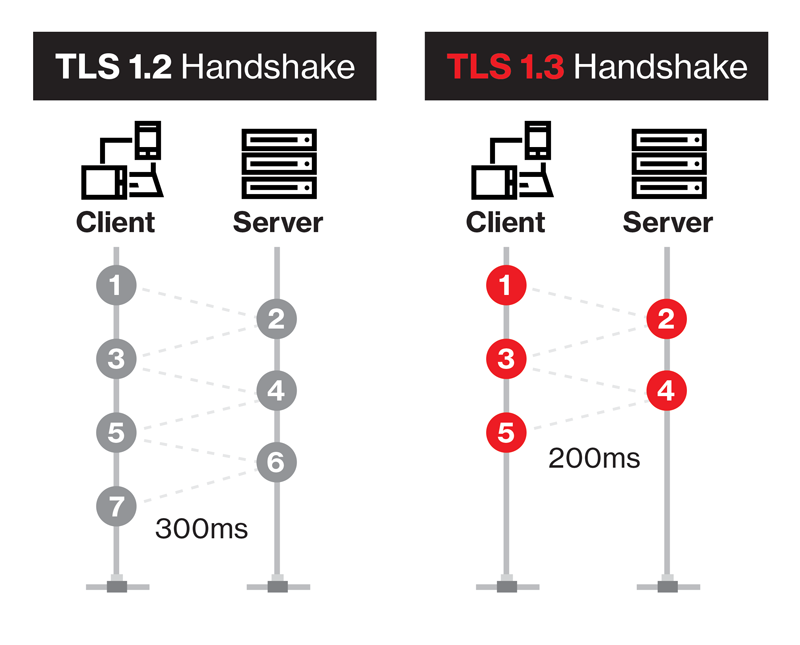
Przy czym pamiętajmy, że protokół TLSv1.3 umożliwia tzw. wznowienie zerowego czasu podróży. Więcej na ten temat poczytasz w oficjalnym drafcie Transport parameters for 0-RTT connections [IETF], a także świetnym artykule Even faster connection establishment with QUIC 0-RTT resumption. Podsumowując różnice:
-
TLSv1.2 (i starsze)
- nowe połączenie: 4 RTT (1x TCP, 2xTLS, 1x HTTP) + DNS
- wznowienie połączenia: 3 RTT (1x TCP, 1xTLS, 1x HTTP) + DNS
-
TLSv1.3
- nowe połączenie: 3 RTT (1x TCP, 1xTLS, 1x HTTP) + DNS
- wznowienie połączenia: 3 RTT (1x TCP, 1xTLS, 1x HTTP) + DNS
-
TLSv1.3 + 0-RTT
- nowe połączenie: 3 RTT (1x TCP, 1xTLS, 1x HTTP) + DNS
- wznowienie połączenia: 2 RTT (1x TCP, 1x[TLS+HTTP]) + DNS
Widzisz sam, że po przejściu na obecnie najnowszą wersję protokołu TLS wzrost wydajności może być naprawdę znaczny.
Głównym problemem związanym z wydajnością uzgadniania TLS nie jest (jak mogłoby się wydawać) to, jak długo trwa cały proces, ale kiedy ma miejsce podczas komunikacji między klientem a serwerem. Ponieważ uzgadnianie jest częścią tworzenia bezpiecznego połączenia, musi nastąpić przed wymianą jakichkolwiek danych. Wydłuża to czas, w którym przeglądarka nie może zrobić nic innego, spowalniając wydajność aplikacji internetowej. Przeglądarka czeka, dopóki nie otrzyma początkowego zasobu, tym samym nie może pobrać równolegle innych, takich jak pliki CSS lub obrazy, ponieważ nie uzyskała tej początkowej informacji, która mówi jej właśnie o innych zasobach. Dzieje się tak w przypadku każdej odwiedzanej strony internetowej: przeglądarka jest blokowana, aby uzyskać tę pierwszą odpowiedź.
Jak zapewne możesz się domyślać, uzgadnianie TLS ma wiele odmian i należy pamiętać, że dokładny narzut tego protokołu zależy od różnych czynników, a znaczący na niego wpływ będzie mieć zmienny rozmiar większości wiadomości oraz różne wzorce ruchu. Samo uzgadnianie jest procesem, który przeglądarka i serwer wykonują, aby zdecydować, w jaki sposób komunikować się ze sobą tworząc bezpieczne połączenie. Niektóre z rzeczy, które mają miejsce podczas uścisku dłoni, to:
- potwierdzenie tożsamości serwera i ewentualnie klienta
- ustalenie, jakie szyfry, podpisy i inne opcje obsługuje każda ze stron, które zostaną użyte podczas szyfrowania połączenia
- tworzenie i wymianę kluczy do późniejszego ich wykorzystania podczas szyfrowania danych
Tak naprawdę, zarówno klient, jak i serwer muszą wykonać symetryczne szyfrowanie i deszyfrowanie, analizę protokołów, obliczenie klucza prywatnego, weryfikację certyfikatu i inne obliczenia, które wydłużają całe połączenie. W istocie uzgadnianie TLS polega na wzajemnej weryfikacji klienta i serwera, uzgadnianiu wspólnego zestawu szyfrów i opcji bezpieczeństwa, a następnie kontynuowaniu konwersacji przy użyciu tych wszystkich rzeczy.
Zacznijmy jednak od poniższej grafiki, która opisuje architekturę protokołu TLS oraz to, gdzie został ulokowany w stosie TCP/IP:
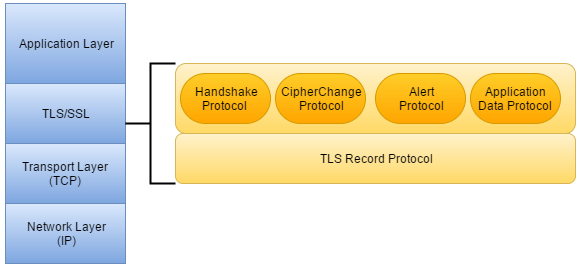
Widzimy, że protokół TLS znajduje się pomiędzy warstwą aplikacji a warstwą transportową i został zaprojektowany do pracy na niezawodnym protokole transportowym, takim jak TCP. Nie jest to jednak jedyny protokół tej warstwy, z którym współpracuje TLS — został on również dostosowany do protokołu UDP, a dokładniej protokołu DTLS (zerknij do RFC 6347 - Datagram Transport Layer Security Version 1.2), który jest w stanie zapewnić podobne gwarancje bezpieczeństwa do TCP przy jednoczesnym zachowaniu modelu dostarczania datagramów.
Korzystając z sieci opartych na protokole IP, mamy tak naprawdę jedynie dwa wyżej wymienione protokoły warstwy transportu. TLS wymaga jednak niezawodnego protokołu warstwy transportowej, ponieważ jednym z kluczowych czynników jego poprawnej pracy jest, aby wszystkie pakiety danych były odbierane w odpowiedniej kolejności i w stanie nieuszkodzonym. Na przykład protokół TLS nie miałby możliwości odzyskania danych z pakietu w celu przedstawienia ich warstwie aplikacji w przypadku jakiejkolwiek utraty lub uszkodzenia. Idąc dalej, gdyby pakiet został uszkodzony, prawdopodobnie zostałby całkowicie zniekształcony z powodu szyfrowania, szczególnie w przypadku użycia szyfrów blokowych. Zatem każdy błąd pakietu w sieci wymagałby przerwania połączenia TLS i ponownej negocjacji, aby zapewnić jego odpowiednią pracę.
Dopóki bazowy protokół transportowy zapewnia gwarancję niezawodności, dopóty sam TLS będzie działał dobrze. W samym protokole TLS nie zaimplementowano nic, co wymagałoby, aby podstawowym protokołem transportowym był TCP. Oczywiście TCP na ogół dokłada wszelkich starań, aby zapewnić niezawodność w przypadku sieci opartych na protokołach TCP/IP, stąd dobrze nadaje się do pracy w połączeniu z protokołem TLS.
Przejdźmy teraz do elementów, z jakich składa się protokół SSL/TLS. Jest on podzielony na dwie podwarstwy:
-
TCP Record - jest to dolna warstwa protokołu, która leży zaraz nad warstwą TCP. Odpowiada ona m.in. za fragmentację wiadomości do przesłania na możliwe do zarządzania bloki, szyfrowanie, deszyfrowanie, kompresję i dekompresja danych wychodzących/przychodzących, zachowanie ich integralności, a także przesyłanie danych z górnej warstwy aplikacji do dolnej warstwy transportowej i odwrotnie
-
warstwy wyższej składającej się z kilku protokołów:
-
Alert - definiuje poziomy alertów wraz z ich opisem. Służy głównie do powiadomienia drugiej strony o wystąpieniu błędu i wskazania potencjalnych problemów, które mogą zagrozić bezpieczeństwu
-
Change Cipher Spec - definiuje ponownie negocjowaną specyfikację szyfrowania (określa zmiany w strategiach szyfrowania) i klucze, które będą używane dla wszystkich wymienianych odtąd komunikatów
-
Application Data - pobiera dowolne dane z warstwy aplikacji i przesyła je przez bezpieczny kanał
-
Handshake - aby komunikować się przez bezpieczny kanał, dwie strony komunikacji muszą uzgodnić klucze kryptograficzne i algorytmy szyfrowania dla danej sesji. Cała sekwencja, która obejmuje ustawienie identyfikatora sesji, wersji protokołu TLS, negocjowanie zestawu szyfrów, uwierzytelnianie certyfikatów i wymianę kluczy kryptograficznych między stronami, nazywa się uzgadnianiem TLS
-
Przypomnijmy sobie teraz, jak wygląda proces uzgadniania (ostatni punkt z powyższej listy) dla typowego połączenia SSL/TLS. Dla uproszczenia będziemy posiłkowali się poniższym schematem:
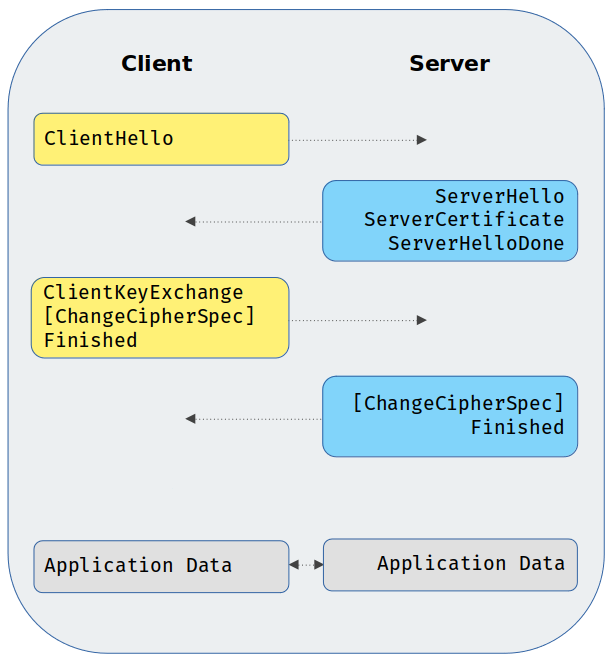
Zachęcam Cię jednak, abyś wykorzystał sniffer sieciowy i samemu zbadał cały ruch w swoim środowisku, aby zobaczyć wszystkie komunikaty, a także to, co się w nich znajduje. Omówmy teraz najbardziej istotne części głównie w kontekście ich rozmiarów (pamiętaj, że są to orientacyjne wartości):
-
ClientHello - wielkość tej wiadomości jest różna, a jej części zależą od implementacji lub konfiguracji TLS konkretnego klienta, w szczególności od liczby szyfrów oferowanych przez klienta i liczby obecnych rozszerzeń. Jako średni rozmiar początkowej wiadomości klienta możemy uznać wartość około 150 bajtów. Jeśli używane jest wznawianie sesji, należy dodać kolejne 32 bajty w polu identyfikatora sesji
-
ServerHello - jest bardzo podobny do powyższego komunikatu, z tą różnicą, że zawiera tylko jeden szyfr i jedną metodę kompresji. Ta wiadomość jest nieco bardziej statyczna niż poprzednia, jednak nadal ma zmienny rozmiar ze względu na dostępne rozszerzenia protokołu TLS. Możemy uznać, że średni rozmiar to 85 bajtów
-
ServerCertificate - ta wiadomość jest najbardziej zróżnicowana pod względem rozmiaru. Zawiera ona certyfikat serwera, a także wszystkie pośrednie certyfikaty wystawcy w łańcuchu certyfikatów (bez certyfikatu głównego). Ponieważ rozmiary certyfikatów różnią się znacznie w zależności od użytych parametrów i kluczy, możemy przyjąć średnio 1500 bajtów na certyfikat (certyfikaty z podpisem własnym mają zazwyczaj znacznie mniejszy rozmiar). Innym zmiennym czynnikiem jest długość łańcucha certyfikatów, stąd w przypadku trzech certyfikatów w łańcuchu daje to około 4.5 KB dla tej wiadomości
-
ServerHelloDone - ten komunikat wskazuje, że serwer jest gotowy i oczekuje na dane wejściowe klienta. Po otrzymaniu tego komunikatu klient sprawdza, czy serwer dostarczył ważny certyfikat, jeśli jest to wymagane, i sprawdza, czy parametry zawarte w ServerHello są akceptowalne. Rozmiar tej wiadomości zostanie pominięty, ponieważ nie ma ona żadnej zawartości
-
ClientKeyExchange - dostarcza serwerowi danych niezbędnych do wygenerowania kluczy do szyfrowania symetrycznego. Format wiadomości jest bardzo podobny do ServerKeyExchange, ponieważ zależy głównie od algorytmu wymiany kluczy wybranego przez serwer. Przyjmijmy średni rozmiar równy 50 bajtom dla tej wiadomości
-
ChangeCipherSpec - stały rozmiar o wielkości 1 bajta (technicznie nie jest to komunikat uzgadniania), występuje po obu stronach komunikacji
-
Finished - ten komunikat sygnalizuje, że negocjacja TLS została zakończona i zawiera skrót wszystkich poprzednich komunikatów uzgadniania, po którym następuje specjalny numer identyfikujący rolę serwera/klienta, klucz główny i wypełnienie. Oczywiście w zależności od tego, jaka wersja protokołu jest używana, rozmiar może się nieco różnić — dla TLSv1.2 będzie to 12 bajtów
-
Application Data - są to zaszyfrowane rekordy wymieniane po uzgodnieniu (można je odszyfrować i zdekodować otrzymując dane HTTP)
Co istotne, wymieniane dane pobrane z warstwy aplikacji (tj. Application Data) dostarczane przez protokół TLS są przesyłane w protokole rekordu — mają nagłówek TLS Record o długości do 16 KB, określający zasady podziału SSL/TLS. Dla każdego wysłanego rekordu musimy doliczyć nagłówek o rozmiarze 5 bajtów, a także nagłówek TLS Handshake o rozmiarze 4 bajtów, określający wspólne parametry kryptograficzne dla obu stron komunikacji (w tym miejscu warto zapoznać się z RFC 5246, gdzie opisane zostały oba typy protokołów). Najczęstszy przypadek można uprościć w ten sposób, że każda strzałka na powyższym schemacie jest rekordem TLS, więc mamy 4 wymienione rekordy o łącznej wielkości 20 bajtów. Każda wiadomość ma dodatkowy nagłówek (z wyjątkiem komunikatu ChangeCipherSpec), więc mamy 7 razy dodatkowy nagłówek uzgadniania, co daje łącznie 28 bajtów.
Generalnie, do każdego rekordu zostanie dodane od 20 do 40 bajtów narzutu na nagłówek, adres MAC i opcjonalne wypełnienie. Jeśli rekord zmieści się w jednym pakiecie TCP, musimy również dodać narzut IP i TCP, czyli 20-bajtowy nagłówek dla IP i 20-bajtowy nagłówek dla TCP bez dodatkowych opcji. W rezultacie każdy rekord może zająć od 60 do 100 bajtów. Dla typowej maksymalnej jednostki transmisji (MTU) o wielkości 1500 bajtów, ta struktura pakietu przekłada się na minimum 6% narzutu ramkowania.
Podsumowując nasz przykład, wygląda to tak:
150 bajtów = ClientHello
85 bajtów = ServerHello
4500 bajtów = ServerCertificate (w przypadku trzech certyfikatów w łańcuchu, 1500 bajtów na certyfikat)
50 bajtów = ClientKeyExchange
24 bajty = ClientFinishedMessage (2 x 12 bajtów dla TLSv1.2)
2 bajty = ChangeCipherSpec (2 x 1 bajt)
20 bajtów = TLS Record Protocol (4 x 5 bajtów)
28 bajtów = TLS Handshake Protocol (7 x 4 bajty)
150 + 85 + 4500 + 50 + 2 + 20 + 28 + 24 = 4859 bajtów
Całkowity narzut związany z ustanowieniem nowej sesji TLS wynosi w tym wypadku około 5 KB. Wiemy także, że dołożenie jeszcze jednego certyfikatu zwiększy rozmiar o około 1500 bajtów. Przypomnij sobie teraz mechanizm wznawiania sesji dzięki któremu, po ustanowieniu sesji TLS, można ją wznowić, pomijając niektóre z ustanowionych wcześniej wiadomości. Pozwala to znacznie zminimalizować całkowity narzut potrzebny przy ustanowieniu nowej sesji, który w przypadku wznowienia może wynieść średnio około 350 bajtów. Z drugiej strony, optymalizacja polegająca na wykorzystaniu mechanizmu wznawianiu może nie mieć aż tak drastycznego wpływu na wydajność jak się wstępnie wydaje.
Widzisz, że w przypadku protokołu SSL/TLS najbardziej zróżnicowaną (pod kątem rozmiaru) częścią są certyfikaty. Dlatego może to być pierwszy element do optymalizacji, ponieważ oprócz ich rozmiaru, znaczenie ma również ich ilość (certyfikat serwera i wszystkie pośrednie certyfikaty wystawcy w łańcuchu certyfikatów, bez certyfikatu głównego). Z racji tego, że rozmiary certyfikatów różnią się w zależności od użytych parametrów i kluczy, przyjąłbym wcześniejszą wartość 1500 bajtów na certyfikat (certyfikaty z podpisem własnym mogą mieć znacznie mniejszy rozmiar) co jak widzisz jest dosyć pokaźnym rozmiarem biorąc pod uwagę całkowity rozmiar ładunku TLS.
Jeżeli chcesz uzyskać więcej informacji na temat protokołów TLS i tego, z czego się składają, odsyłam do trzech genialnych prezentacji:
- The Illustrated TLS Connection - TLSv1.2
- The New Illustrated TLS Connection - TLSv1.3
- Traffic analysis of an SSL/TLS session
Jak już wspomniałem wcześniej, pojawia się tutaj jeszcze jedna kwestia, mianowicie całkowitego narzutu obciążenia sieci związanego z zaszyfrowanymi danymi, który może wynieść około 40 bajtów (w zależności od mechanizmów integralności danych, kompresji czy algorytmu MAC). Po drugie, w zależności od używanych zestawów szyfrów, narzut TLS w czasie wykonywania jest różny. Szyfry blokowe zwykle powodują większe obciążenie w porównaniu do szyfrów strumieniowych pod względem ruchu (ze względu na wypełnienie). Obciążenie środowiska, z racji wykorzystania procesora, jest również wyższe w porównaniu ze standardową transmisją, ponieważ w grę wchodzą operacje kryptograficzne (widoczne jest to zwłaszcza przy większych kluczach, tj. 4096-bit — warto tutaj pamiętać o kluczach ECDSA jako dodatkowej optymalizacji).
Podsumowując i dodając jeszcze kilka istotnych informacji:
- całkowity narzut związany z ustanowieniem nowej sesji TLS wynosi średnio kilka kilobajtów (w naszym przykładzie było to 5 KB), co spowoduje również przejście większej liczby ramek Ethernet przez przewód
- całkowity koszt wznowienia istniejącej sesji TLS jest znacznie mniejszy (możemy przyjąć, że jest to około 350 bajtów), ponieważ pozwala uniknąć części uzgadniania związanej z wymianą klucza publicznego, a także weryfikacji certyfikatu
- całkowity narzut zaszyfrowanych danych wynosi około 40 bajtów
- największy koszt wydajności serwera TLS związany jest z kryptografią klucza publicznego
- należy pamiętać, że asymetryczny rozmiar klucza może mieć ogromny wpływ na wydajność, jednak co istotne, im większy rozmiar klucza asymetrycznego, tym trudniej będzie atakującemu złamać wygenerowany klucz symetryczny
- w przypadku serwera NGINX, proces szyfrowania i deszyfrowania, który zużywa najwięcej procesora, zostaje wyeliminowany, unikając synchronicznych obliczeń (cały proces jest asynchroniczny, dzięki czemu możliwe jest odbieranie pozostałych żądania bez czekania na wynik obliczenia RSA)
- pamięć podręczna sesji TLS może poprawić ogólną wydajność połączenia i zaoszczędzić zasoby systemowe
- zwiększając wydajność procesora, ogólne obciążenie TLS będzie się zmniejszać
- TLS wydaje się być wyłącznie powiązany z procesorem, ponieważ wszelkie optymalizacje mające na celu zmniejszenie ruchu w sieci (zwłaszcza sieci z dużymi opóźnieniami i stratami pakietów) mają niewielki wpływ na całkowitą przepustowość serwera
- koszty procesora związane z zestawieniem połączenia TLS mają większy wpływ na przepustowość serwera niż koszty procesora związane z wymianą danych za pomocą tego protokołu
- koszty organizowania struktur danych TLS, obliczania kluczy z klucza wstępnego i wykonywania innych różnych operacji w ramach protokołu TLS pochłaniają niewielką ilość całkowitego kosztu wydajności
Przy okazji koniecznie zapoznaj się z dokumentem Performance Analysis of TLS Web Servers. Pamiętaj też, że przyjąłem wartości raczej orientacyjne i dobrze, abyś zweryfikował je z dostępnymi dokumentami RFC, np. Overview and Analysis of Overhead Caused by TLS. Chodzi jednak o uzmysłowienie sobie ile danych jest przenoszonych podczas wykorzystania protokołu TLS niż autorytatywne określenie wszystkich wartości.
Ile czasu trwa uzgadnianie? #
Możesz teraz zadać pytanie, w jaki sposób zmierzyć czas zestawiania sesji SSL/TLS i jak długo ten proces trwa? Spójrz na poniższy diagram, który pokazuje, do czego odnoszą się poszczególne czasy w porównaniu z typowym połączeniem HTTP przez TLSv1.2 (konfiguracja TLSv1.3 wymaga jednej podróży w obie strony mniej) oraz jest odzwierciedleniem, w jaki sposób biblioteka curl odnosi się do różnych etapów transferu danych dla typowego połączenia:
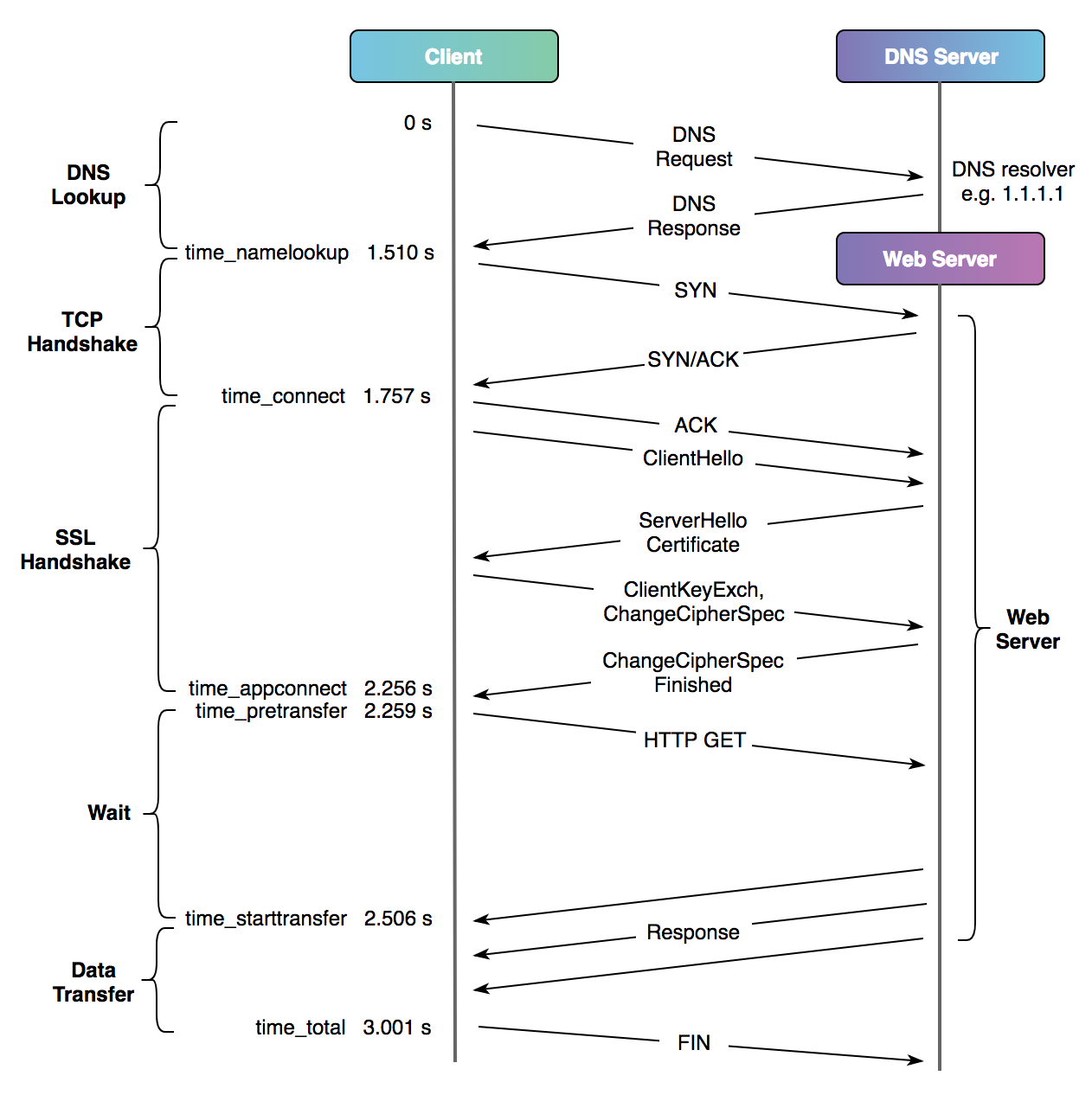
Diagram pochodzi z artykułu A Question of Timing.
Przedstawia on m.in. ile czasu serwer spędził na uzgadnianiu TLS (%{time_appconnect} - %{time_connect}). Oczywiście do wyliczenia wszystkich wartości możesz użyć przeglądarki i dostarczonych z nią narzędzi (spójrz na artykuł A Question of Timing). Poniżej znajduje się podobny diagram do powyższego, pokazujący zmierzone czasy z poziomu przeglądarki internetowej:
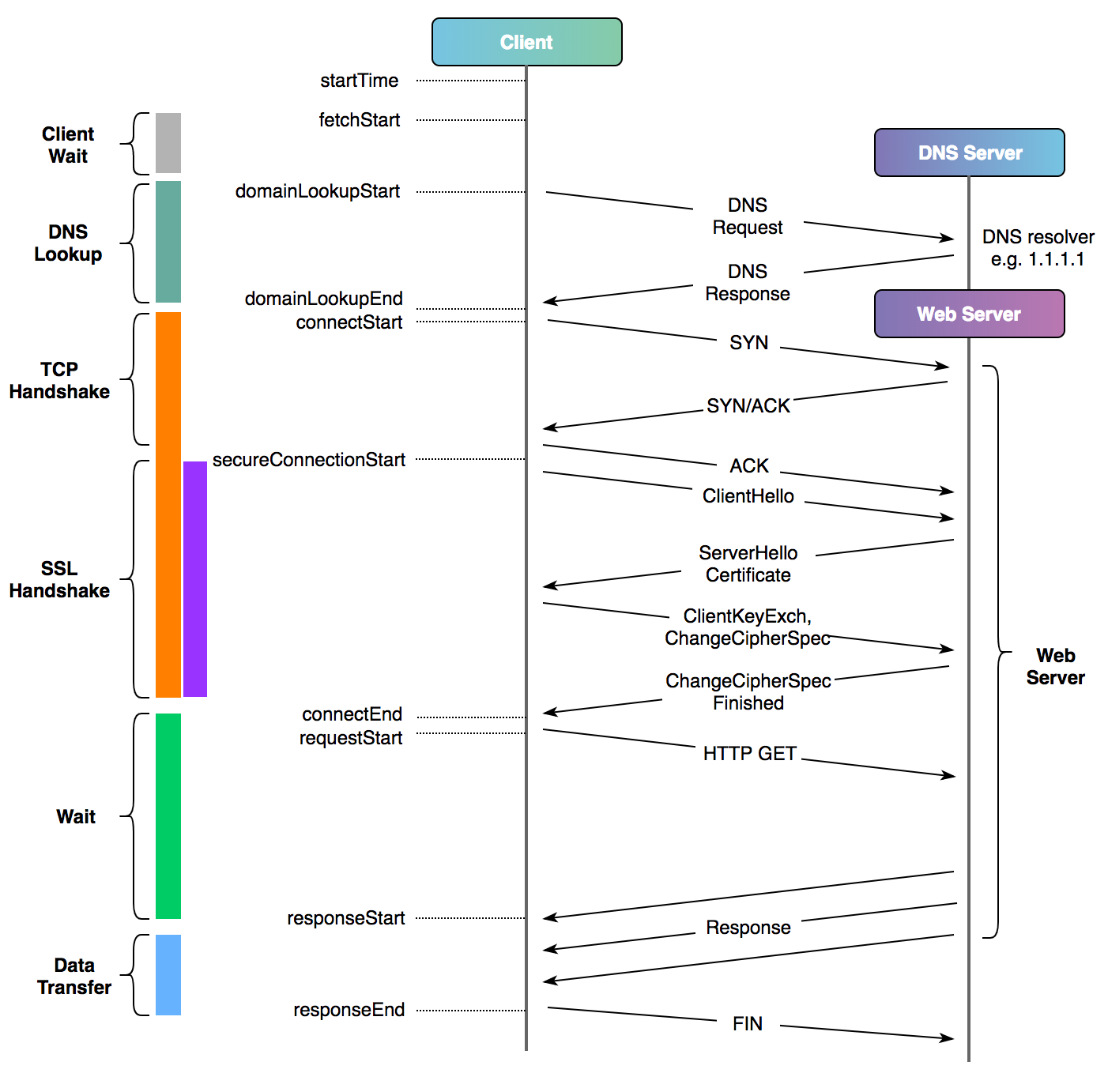
Diagram pochodzi z artykułu A Question of Timing.
Możesz też użyć prostego narzędzia o nazwie ttfb.sh, którego wynik działania prezentuje się jak poniżej:
./ttfb -v -n 5 https://badssl.com
DNS lookup: 0.078838 TLS handshake: 0.746465 TTFB including connection: 0.874749 TTFB: .128284 Total time: 0.874925
DNS lookup: 0.002692 TLS handshake: 0.649374 TTFB including connection: 0.777400 TTFB: .128026 Total time: 0.777545
DNS lookup: 0.002123 TLS handshake: 0.652230 TTFB including connection: 0.780659 TTFB: .128429 Total time: 0.780873
DNS lookup: 0.002334 TLS handshake: 0.637931 TTFB including connection: 0.766321 TTFB: .128390 Total time: 0.766513
DNS lookup: 0.002227 TLS handshake: 0.643825 TTFB including connection: 0.772996 TTFB: .129171 Total time: 0.773133
Oraz narzędzia htrace.sh uruchamiając go z parametrem --timers lub włączając opcję CURL_TIMERS w pliku konfiguracyjnym:
htrace.sh -u https://badssl.com
htrace.sh v1.1.7 (openssl 1.1.1g : ok)
URI: https://badssl.com
» request-method: GET
» user-agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0
req full_time time_total local_socket via remote_socket geo proto ver code next_hop
--- --------- ---------- ------------ --- ------------- --- ----- --- ---- --------
• 1 0.986634 0.986634 xxx.xxx.xxx.xxx:51800 xxx.xxx.xxx.xxx 104.154.89.105:443 US https 1.1 200
Request Size 209 bytes
Response Size 2741 bytes
Headers Size 284 bytes
————————————————————————————————————
[0ms]
› DNS Query
‹ DNS Response
DNS Lookup 58.77ms
[58.77ms]
› TCP SYN
› TCP ACK
TCP Handshake (RTT) 306.03ms
[364.80ms]
› TLS ClientHello
‹ TLS Finished
TLS Handshake 466.89ms
[831.70ms]
TLS › HTTP 0.12ms
[831.81ms]
› HTTP Request
‹ HTTP Response
Waiting (TTFB) 154.19ms
[986.00ms]
Data Transfer 0.63ms
————————————————————————————————————
Time Total 986.63ms
Rozmiar i typ pamięci podręcznej #
Omówmy w takim razie pierwszy z parametrów, mianowicie pamięć podręczną sesji SSL/TLS. Zastosowanie tej techniki zwiększa ogólną wydajność połączeń (zwłaszcza połączeń typu Keep-Alive). Wartość 10 MB jest dobrym punktem wyjścia (1 MB współdzielonej pamięci podręcznej może pomieścić około 4000 sesji), aby pamięć podręczna była zmieniana codziennie. Dzięki parametrowi shared pamięć dla połączeń SS/TLS jest współdzielona przez wszystkie procesy robocze (co więcej pamięć podręczna o tej samej nazwie może być używana na kilku serwerach wirtualnych). Ustawienie tego parametru jest wręcz kluczowe w przypadku dużej ilości kontekstów server {...} (wirtualnych hostów), ponieważ ich duża ilość może zwiększyć wykorzystanie pamięci.
Jak już doskonale wiemy, w przypadku protokołu HTTPS, połączenie wymaga dodatkowego uzgadniania. Dzieje się tak, ponieważ uzgadnianie TLS wymaga co najmniej jednej podróży w obie strony. Włączenie pamięci podręcznej sesji TLS zapewni szybszą wydajność HTTPS dla połączeń początkowych, a także późniejszego ładowania stron niż w przypadku protokołu HTTP.
Głównym celem pamięci podręcznej sesji SSL/TLS po stronie serwera jest zmniejszenie użycia procesora oraz zwiększenie wydajność z punktu widzenia klientów, dzięki wyeliminowaniu konieczność ciągłej renegocjacji sesji — czyli przeprowadzania nowego (i czasochłonnego) uzgadniania SSL/TLS przy każdym żądaniu (po więcej informacji zerknij do artykułu TLS Session Resumption: Full-speed and Secure).
Jeśli rozmiar pamięci podręcznej jest zbyt mały, może dojść do sytuacji, w której zabraknie miejsca na sesje dla nowych klientów — w najgorszym przypadku pamięć podręczna nie będzie działać skutecznie dla nowych sesji. W takiej sytuacji, w celu zwolnienia miejsca, NGINX spróbuje usunąć przechowywane w pamięci sesje, które nie wygasły i które są nadal w niej przechowywane (nie zawsze jednak tak się dzieje, np. ze względu na to, że różne sesje mogą zajmować różną przestrzeń adresową). Taka sytuacja może powodować poniższe alerty:
[alert] [...] could not allocate new session in SSL session shared cache "NGX_SSL_CACHE" while SSL handshaking [...]
Informacja ta mówi jedynie o tym, że NGINX nie był w stanie przydzielić nowej sesji we współdzielonej pamięci podręcznej. Nie oznacza ona błędów po stronie klienta i jednym znanym skutkiem ubocznym będzie to, że klienci, którzy ponownie wykonują połączenie, ponoszą niewielką utratę wydajności, ponieważ nie mają wznowienia sesji. Taka sytuacja może się zdarzyć, jeśli pamięć podręczna jest pełna, a NGINX nie był w stanie zwolnić wystarczającej ilości miejsca, usuwając ostatnio używaną sesję. Rozwiązaniem jest zmniejszenie limitów czasu sesji (parametr: ssl_session_timeout) lub zwiększenie rozmiaru pamięci współdzielonej, aby uniknąć przepełnienia. W ten sposób sesje powinny wygasnąć i zostać usunięte z pamięci podręcznej, zanim zostanie ona ponownie przepełniona.
Co niezwykle istotne, parametr ten jest ściśle związany z opcją odpowiedzialną za czas życia parametrów sesji. Oficjalna dokumentacja podaje przykład i tłumaczy tą zależność jak poniżej:
When you increase the timeout, the cache needs to be bigger to accommodate the larger number of cached parameters that results. For the 4-hour timeout in the following example, a 20-MB cache is appropriate [...] If the timeout length is increased, you need a larger cache to store sessions, for example, 20 MB [...]
Oczywiście nie ma róży bez kolców. Jednym z powodów, dla których nie należy używać bardzo dużej pamięci podręcznej, jest to, że większość implementacji nie usuwa z niej żadnych rekordów. Nawet wygasłe sesje mogą nadal się w niej znajdować i można je odzyskać!
Przykład konfiguracji:
# context: http, server
# default: none
ssl_session_cache shared:NGX_SSL_CACHE:10m;
Oficjalna dokumentacja: ssl_session_cache.
Czas życia parametrów sesji #
Zgodnie z RFC 5077 - Ticket Lifetime [IETF], sesje nie powinny być utrzymywane dłużej niż 24 godziny (jest to maksymalny czas dla sesji SSL/TLS). Jakiś czas temu znalazłem rekomendację, aby dyrektywa ta miała jeszcze mniejszą, wręcz bardzo niską wartość ustawioną na ok. 15 minut (co ciekawe, dokumentacja serwera NGINX ustawia wartość domyślną na 5 minut). Ma to zapobiegać nadużyciom przez reklamodawców takich jak Google i Facebook. Nigdy nie stosowałem tak niskich wartości, jednak myślę, że w jakiś sposób może to mieć sens.
Jeśli stosujemy szyfry wykorzystujące utajnianie z wyprzedzeniem, musimy upewnić się, że okres ważności parametrów sesji nie jest zbyt długi, ponieważ ewentualna kradzież zawartości pamięci podręcznej pozwala odszyfrować wszystkie sesje, których parametry są w niej zawarte. Jeśli sesje będą przechowywane przez 24h, osoba atakująca może odszyfrować maksymalnie 24 godziny komunikacji sieciowej.
W tym miejscu chciałbym zacytować wypowiedź twórcy serwisu Hardenize, a także autora świetnej książki Bulletproof SSL and TLS: Understanding and deploying SSL/TLS and PKI to secure servers and web applications.:
These days I'd probably reduce the maximum session duration to 4 hours, down from 24 hours currently in my book. But that's largely based on a gut feeling that 4 hours is enough for you to reap the performance benefits, and using a shorter lifetime is always better.
Na przykład zmiana czasu buforowania sesji z 10 minut na 24 godziny oznacza, że sesje będą zużywać 144 razy więcej w pamięci podręcznej. Myślę, że wartość 4h jest rozsądną i jedną z optymalnych wartości. Przy jej ustawieniu pomyśl jednak, jak długo dany klient będzie przeglądał strony w Twoim serwisie.
Przykład konfiguracji:
# context: http, server
# default: 5m
ssl_session_timeout 4h;
Oficjalna dokumentacja: ssl_session_timeout.
Limit czasu na zakończenie uzgadniania #
Jak doskonale wiemy, sesje SSL/TLS rozpoczynają się od wymiany wiadomości nazywanej uzgadnianiem. Uzgadnianie umożliwia wymianę wielu niezwykle istotnych informacji między klientem a serwerem do poprawnego zestawienia szyfrowanego połączenia. W przypadku serwera NGINX domyślny limit czasu do zakończenia lub przekroczenia pierwszej wymiany (niekompletnego uzgadniania protokołu) wynosi 60 sekund.
Pamiętajmy, że cały proces powinien zająć ledwie ułamek sekundy, a w niektórych specyficznych przypadkach powinien potrwać maksymalnie kilka sekund. Moim zdaniem wartość 60s jest zbyt duża, ponieważ może zwiększyć podatność na ataki polegające na wyczerpaniu połączeń serwera przez niepowodzenie zakończenia z użyciem protokołów SSL/TLS. Doprowadzi to najprawdopodobniej do większego zużycia pamięci, powolnej odpowiedź serwera i w ostateczności jego niedostępności.
Dzięki temu parametrowi serwer zamyka połączenia, których zakończenie uzgadniania protokołu SSL/TLS trwa dłużej. Bez tego limitu, słabo lub nieodpowiednio skonfigurowany serwer po prostu czekałby w nieskończoność na zakończenie uzgadniania SSL/TLS.
Z drugiej strony, w niektórych systemach wbudowanych o niższej mocy procesora, zwłaszcza przy wykorzystaniu dłuższych kluczy RSA, podczas wymiany odszyfrowanie może zająć więcej czasu. Ustawienie zbyt niskiej wartości może spowodować problemy połączenia z serwerem właśnie z powodu przekroczenia limitu czasu. Należy wtedy odpowiednio dostosować wartość, aby umożliwić korzystanie z najnowszych protokołów kryptograficznych tak często, jak to tylko możliwe (także starszym oraz działającym w mocno ograniczonych środowiskach klientom).
Uważam też, że mając ustawioną niższą wartość (np. na 10s) konieczność jej zwiększenia pojawia się raczej w przypadku bardzo wolnych klientów i sieci. Powyższy limit uzgadniania SSL/TLS w pozostałych okolicznościach wskazuje raczej na problemy w innym miejscu.
Przykład konfiguracji:
# context: stream, server
# default: 60s
ssl_handshake_timeout 30s;
Oficjalna dokumentacja: ssl_handshake_timeout.
Wznawianie sesji #
Jedną z krytycznych części uzgadniania TLS jest uwierzytelnianie tożsamości serwera. Podczas pełnego uzgadniania, klient sprawdza tożsamość serwera na podstawie kryptografii klucza publicznego. W związku z tym od serwera wymaga się przedstawienia ważnego certyfikatu zawierającego klucz publiczny potwierdzający deklarowaną tożsamość. Ponadto klient sprawdza, czy serwer może wygenerować nowy podpis z kluczem prywatnym odpowiadającym przedstawionemu certyfikatowi/kluczowi publicznemu.
Aby zmniejszyć ilość operacji kryptograficznych podczas procesu nawiązywania połączenia, można ponownie wykorzystać istniejący/stary materiał kryptograficzny. Klient może zażądać wznowienia sesji z serwerem, który wcześniej współużytkował sesję z klientem powodując skrócenie czasu i zmniejszenie ruchu sieciowego spędzanego na uzgadnianiu. Dzięki temu, w ramach wznowionego uzgadniania TLS, te kosztowne obliczeniowo operacje klucza publicznego są pomijane. Serwer jest uwierzytelniany na podstawie znajomości tajemnicy kryptograficznej związanej z oryginalną sesją TLS, co umożliwia serwerowi odszyfrowanie wznawianej części uzgadniania.
Zasada działania tego mechanizmu jest bardzo prosta. Zapisz klucz symetryczny, który został obliczony podczas pierwszego uzgadniania i używaj go bezpośrednio w kolejnych żądaniach. Ta praktyka polega na pośrednim uwierzytelnieniu tożsamości serwera, ponieważ klient nie sprawdza poprawności certyfikatu serwera i posiadania przez serwer odpowiedniego klucza prywatnego w ramach wznowionej sesji TLS.
W związku z tym synchronizacja wznawiania wymaga, aby klient ufał poprawności uwierzytelnienia serwera podczas oryginalnej sesji. Widzimy tym samym, że wznawianie sesji jest niezwykle użyteczne i może być kluczową optymalizacją, pozwalającą zaoszczędzić na kosztach, takich jak transmisja certyfikatu, a także może zmniejszyć RTT wymagany do uzgadniania TLS nawet do jednego. Niestety, w większości przypadków, a zwłaszcza w tym, bezpieczeństwo i wspomniana użyteczność są odwrotnie proporcjonalne. O tym jednak za chwilę.
TLS oferuje dwa mechanizmy wznawiania sesji: identyfikatory sesji (gdzie serwer i klient przechowują swoje własne tajne stany i kojarzą go z identyfikatorem) i bilety sesji (gdzie klient przechowuje stan serwera, zaszyfrowany przez serwer). Identyfikator sesji jest specjalnym atrybutem (indeksem w tabeli, w której serwer znajdzie wszystkie niezbędne klucze itd. dla danej sesji) generowanym podczas uzgadniania protokołu TLS. Serwer może przechowywać informacje po wynegocjowaniu identyfikatora, a przeglądarka może również zapisać identyfikator i wprowadzić go do kolejnego uzgadniania w komunikacie ClientHello. Jeśli serwer jest w stanie znaleźć pasujące informacje, może wykonać szybkie uzgadnianie.
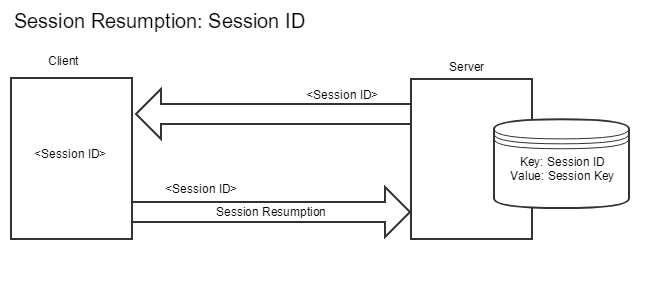
Widzisz, że dzięki identyfikatorom sesji serwer musi śledzić poprzednie sesje, które mogą być kontynuowane. Powoduje to dodatkową pracę, którą musi wykonać serwer. Mechanizm identyfikatora sesji ma jeszcze inne wady, m.in. brak synchronizacji informacji o sesjach w niektórych przypadkach czy brak odpowiednich mechanizmów kontrolowania unieważnienia, ponieważ zbyt krótki czas nie będzie skuteczny, a zbyt długi zajmie dużo zasobów serwera takich jak pamięć.
Bilety sesji, które zostały dokładniej opisane w dokumencie RFC 5077 [IETF] są w stanie rozwiązać te problemy. Mechanizm ten jest rozszerzeniem TLS (nie identyfikatorem), a dokładniej danymi sesji zaszyfrowanymi przez serwer (i tylko serwer może je odszyfrować), który przede wszystkim pomaga zmniejszyć obciążenie połączeń TLS. Wznowienie sesji z biletami działa tak długo, jak długo klient wysyła bilet sesji, a serwer ma niezbędne sekrety, aby wydobyć informacje z biletu. Serwer może jednak wprowadzić dodatkowe ograniczenia, takie jak zakodowanie adresu IP klienta w bilecie w celu sprawdzenia, czy nadal komunikuje się z tym samym klientem.
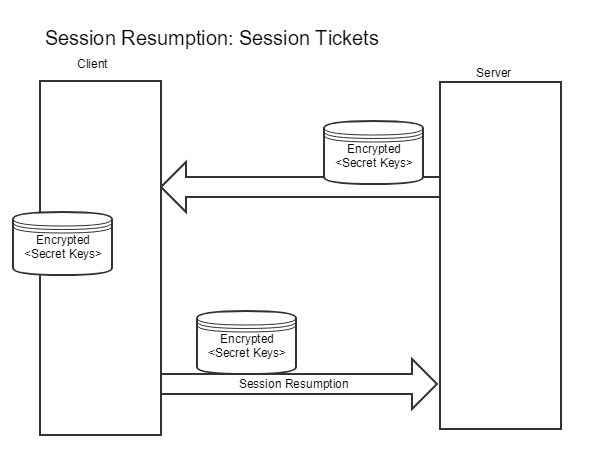
Ponieważ bilety sesji TLS są rozszerzeniem TLS, nie mają one wpływu na klientów, którzy o nich nie wiedzą. Dane połączenie TLS użyje biletu tylko wtedy, gdy klient wyraźnie zgłosi obsługę rozszerzenia w komunikacie ClientHello. W konsekwencji nawet jeśli aktywujesz bilety sesji, może być to jedynie oportunistyczna optymalizacja.
Gdy klient chce kontynuować sesję, nadal zna pre-master key, w przeciwieństwie do serwera. Tak więc klient wysyła bilet sesji do serwera i tylko serwer jest w stanie odszyfrować jego zawartość. Znajdują się tam wszelkie informacje wymagane do kontynuowania sesji, dzięki czemu serwer może wznowić sesję bez przechowywania dodatkowych informacji, a całe nadprogramowe obciążenie odbywa się po stronie klienta (przez zachowanie tajemnicy pre-master i biletu sesji). Więcej na temat biletów sesji poczytasz w świetnym artykule We need to talk about session tickets, w którym autor mówi, że tylko w przypadku użycia TLSv1.3, możemy całkowicie bezpiecznie korzystać ze wznowienia TLS.
Klient może zareklamować swoje wsparcie dla rozszerzenia biletów sesji, wysyłając puste rozszerzenie Session Ticket w wiadomości Client Hello. Serwer odpowie pustym rozszerzeniem Session Ticket w komunikacie Server Hello, jeśli je obsługuje. Jeśli jeden z nich nie obsługuje tego rozszerzenia, mogą skorzystać z mechanizmu identyfikatora sesji wbudowanego w SSL/TLS.
Jak już powiedzieliśmy, klucze sesji lub inaczej bilety sesji zawierają pełny stan sesji (w tym klucz wynegocjowany między klientem a serwerem czy wykorzystywane zestawy szyfrów), dzięki czemu zmniejszają obciążenie uścisku dłoni, który jak wiemy, jest najbardziej kosztowny w całym procesie uzgadniania. Informacje o sesji zaszyfrowane są za pomocą specjalnego klucza, który zna tylko serwer, a które to są ostatecznie zapisywane po stronie przeglądarki. Jeśli przeglądarka ustawi bilet sesji w komunikacie ClientHello, szybkie uzgadnianie może zostać zakończone, o ile serwer może pomyślnie go odszyfrować.
Główną optymalizacją jest uniknięcie konieczności utrzymywania pamięci podręcznej sesji po stronie serwera, ponieważ cały stan sesji jest zapamiętywany przez klienta, a nie przez serwer. Pamięć podręczna sesji może być kosztowna pod względem pamięci i może być trudna do współużytkowania między wieloma hostami, gdy wykorzystywane są mechanizmy równoważenia obciążenia — wszystkie serwery muszą wspólnie użytkować pamięć sesji (składającą się z identyfikatorów sesji i parametrów kryptograficznych), w przeciwnym razie jeśli klient połączy się z serwerem, który nie ma parametrów sesji, to ani klient, ani serwer nie są w stanie wykonać wznowienia.
Mechanizm wznawianie przydaje się chyba szczególnie gdy dojdzie np. do zerwania sesji. Wszystkie informacje wymagane do kontynuowania sesji są znane klientowi, więc serwer może wznowić sesję, wykorzystując wcześniejsze parametry. Gdy klient obsługuje bilety sesji, serwer zaszyfruje klucz sesji kluczem, który posiada tylko serwer, kluczem szyfrowania biletu sesji (ang. STEK - Session Ticket Encryption Key) i wyśle go do klienta. Klient przechowuje ten zaszyfrowany klucz sesji, zwany biletem, wraz z odpowiednim kluczem sesji. Serwer tym samym zapomina o kliencie, umożliwiając wdrożenia bezstanowe.
Jeżeli komunikat ChangeCipherSpec pojawia się bezpośrednio po ServerHello, oznacza to, że jest to sesja wznowiona (buforowana zarówno na kliencie, jak i na serwerze) lub wykorzystano bilet sesji. W sesjach wznowionych uwierzytelnienie certyfikatu serwera już miało miejsce, więc certyfikat(y) nie będą wymieniane.
Przy kolejnym połączeniu, klient wysyła bilet wraz z parametrami początkowymi. Jeśli serwer nadal ma klucz szyfrowania biletu sesji, odszyfruje go, wyodrębni klucz sesji i zacznie go używać. Ustanawia to wznowione połączenie i oszczędza komunikację w obie strony, pomijając kluczowe (początkowe) negocjacje. W przeciwnym razie klient i serwer powrócą do normalnego uzgadniania. Widzimy ponownie, że cała dodatkowa obsługa odbywa się po stronie klienta.
Co kluczowe i warte zapamiętania, bilety sesji zawierają klucze sesji oryginalnego połączenia, więc skompromitowany bilet sesji pozwala atakującemu odszyfrować nie tylko wznowione połączenie, ale także oryginalne połączenie (problem nasila się, gdy sesja jest regularnie wznawiana, a te same klucze sesji są ponownie pakowane w nowe bilety sesji). Niestety większość serwerów nie usuwa kluczy sesji ani biletów, zwiększając w ten sposób ryzyko wycieku danych z poprzednich (i przyszłych) połączeń. Co więcej, takie zachowanie „niszczy” tajemnicę przekazywania (ang. Forward Secrecy), która chroni poufność połączeń na wypadek, gdyby serwer został naruszony przez atakującego, nawet po upływie okresu ważności biletu sesyjnego. Wznawianie połączeń bez wykonania jakiejkolwiek wymiany kluczy (tym samym bez zaoferowania tajemnicy przekazywania) jest jednym z większych problemów (i niejedynym co zaraz zobaczysz) związanym z biletami sesji w TLSv1.2.
Niestety, moim zdaniem, niektóre implementacje pozostawiają wiele do życzenia, powodując, że jest to jeden z najsłabszych elementów protokołu TLS. Dokładniej problem opisano w świetnym artykule How to botch TLS forward secrecy a dowodem na problemy z mechanizmem i jego implementacjami niech będzie najnowsza podatność oznaczona jako CVE-2020-13777 odkryta w bibliotece GnuTLS. Szkopuł polegał na tym, że mechanizm rotacji kluczy w rzeczywistości w ogóle nie dział a zmiana, która miała pomóc w zachowaniu tajemnicy przekazywania i wprowadziła tę lukę, zwiększyła tylko złożoność. W konsekwencji możliwe było pasywne rozszyfrowanie większości połączeń od wersji TLSv1.0 do TLSv1.2 oraz przechwycenie większość połączeń wykorzystujących najnowszą wersję protokołu, tj. TLSv1.3 (więcej szczegółów tutaj: CVE-2020-13777: TLS 1.3 session resumption works without master key, allowing MITM).
W przypadku biletów sesji klucz szyfrowania biletu sesji jest słabym punktem, ponieważ może zostać skradziony i użyty do odszyfrowania biletu sesji wysłanego przez serwer (lub przez klienta przy wznowieniu sesji). Dzięki informacjom zawartym w bilecie sesji atakujący może łatwo odszyfrować faktyczną komunikację między klientem a serwerem. Należy również pamiętać, że bilety sesji są zawsze szyfrowane za pomocą AES-128-CBC i chronione integralnością za pomocą HMAC-SHA-256. Nawet jeśli używasz silniejszych algorytmów dla połączeń TLS, powiedzmy AES-256-GCM, podczas korzystania z biletów sesji bezpieczeństwo zostaje zredukowane do 128-bitowego AES.
Problem kluczy sesji dotyczy tak naprawdę ich obecnej implementacji (inżynierowie serwera NGINX zalecali ich wyłączenie ze względu na brak odpowiednich mechanizmów odpowiedzialnych za rotację kluczy), a nie tego, że sam mechanizm jest niebezpieczny czy w jakiś sposób podatny (co nie do końca jest prawdą). Po pierwsze, włączając go, nie zapewnisz poufności przekazywania i spowodujesz, że PFS będzie bezużyteczny, ponieważ przy korzystaniu z mechanizmu biletów sesji, wszystkie klucze szyfrowania będą ostatecznie szyfrowane tylko jednym kluczem szyfrowania, tj. kluczem biletu sesji. Dlatego jeśli PFS jest silnym wymaganiem, musisz upewnić się, że czas życia identyfikatorów lub biletów sesji nie jest zbyt długi. Ponadto należy okresowo zmieniać klucz dla biletów sesji. Moim zdaniem, bilety sesji nie powinny być w ogóle wykorzystywane z jeszcze jednego powodu: dla wersji TLSv1.2 i niższych, ujawnia się ich największa wada — są one wysyłane w czystej postaci na początku pierwotnego połączenia.
Na poniższym zrzucie widać, że wiadomość NewSessionTicket jest wysyłana z serwera do klienta przed wiadomością ChangeCipherSpec:
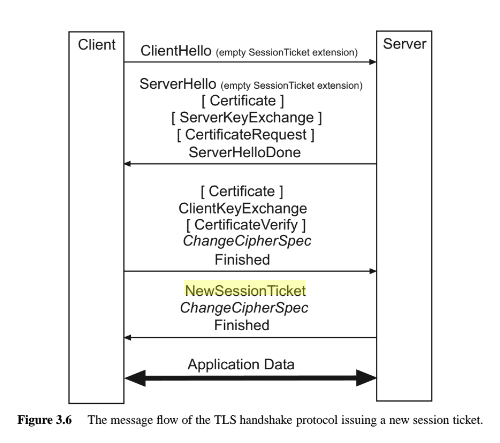
Ogólnie rzecz biorąc, funkcja wznawiania sesji TLS przyspiesza ponowne połączenia klientów, ponieważ nie ma potrzeby wykonywania pełnego uzgadniania protokołu TLS. Zamiast tego do weryfikacji autentyczności połączenia używana jest wartość znana z poprzedniej sesji. Jeśli serwer nie rotuje lub nie odnawia poprawnie swoich sekretów, to jak już wspomniałem, wznowienie sesji niszczy poufność przekazywania.
W najnowszej wersji protokołu TLS identyfikatory sesji i bilety sesji zostały zastąpione innym mechanizmem. Jak już wiemy, w przypadku protokołów do TLSv1.2 istnieją dwa sposoby wznowienia połączenia, właśnie za pomocą identyfikatorów sesji i biletów sesji. Oba mechanizmy są przestarzałe w TLSv1.3 i zostały połączone w celu utworzenia nowego trybu zwanego wznowieniem PSK (klucz wstępny). Pomysł polega na tym, że po ustanowieniu sesji klient i serwer mogą uzyskać wspólny sekret zwany „głównym sekretem wznowienia”. Może on być przechowywany na serwerze z identyfikatorem (styl identyfikatora sesji) lub zaszyfrowane kluczem znanym tylko serwerowi (styl biletu sesji). Ten bilet sesji jest wysyłany do klienta i wykorzystany podczas wznawiania połączenia.
Mówiąc bardziej technicznie, w TLSv1.3 stnieją dwa nowe mechanizmy wznawiania sesji, psk_ke i psk_dhe_ke. Pierwszy z nich zapewnia taką samą implementację, a tym samym bezpieczeństwo, co wznawianie sesji w aktualnych standardach TLS (do wersji TLSv1.2). Drugi czyni go bardziej bezpiecznym poprzez włączenie dodatkowego współdzielonego klucza (EC)DHE (PSK) wyprowadzonego z klucza głównego podczas nawiązania pierwszego połączenia. Więcej do poczytania na ten temat znajdziesz w artykule The future of session resumption - Forward secure PSK key agreement in TLS 1.3.
Wznowienie sesji w przypadku protokołu TLSv1.2 można zaimplementować za pomocą identyfikatorów sesji lub biletów sesji. Protokół TLSv1.3 porzuca obie koncepcje zastępując je trybem klucza wstępnego (PSK), który po wstępnym uzgadnianiu, jest wysyłany przez serwer (zależy tylko od niego) do klienta. Klient jedynie przechowuje tożsamość PSK wraz z własnymi kluczami sesji. W kolejnym uzgadnianiu klient przekazuje tę tożsamość, a serwer, w zależności od zawartości, odszyfrowuje bilet i wykorzystuje zawarte w nim klucze sesji oraz stany połączeń wymagane do wznowienia sesji lub używa zawartego klucza wyszukiwania, aby znaleźć klucze sesji i stany połączeń we własnej bazie danych.
Inny problem z obecnymi implementacjami to usuwanie informacji o sesjach. Uważam, że jedynym sposobem na prawdziwe usunięcie danych sesyjnych jest zastąpienie ich nową sesją — czyli odpowiednia rotacja w celu ich zniszczenia. Idealną praktyką jest generowanie losowych kluczy biletów sesji oraz ich częsta wymiana. Ciekawostka: na przykład Twitter rotuje klucze co 12h, zaś stare usuwa co 36h, natomiast Mozilla zaleca regenerowanie kluczy co 24h. W ramach poszerzenia swojej wiedzy polecam także zapoznać się z niezwykle interesującą pracą Measuring the Security Harm of TLS Crypto Shortcut [PDF], która opisuje zastosowane skróty bezpieczeństwa w implementacjach TLS w celu ograniczenia kosztów obliczeń kryptograficznych i podróży zaszyfrowanych danych w obie strony. Warto wiedzieć, że TLSv1.3 rozwiązuje (łagodzi) w pewien sposób problem rotacji, zaprzęgając do tego klucze Diffie-Hellman (więcej informacji uzyskasz w artykule How to botch TLS forward secrecy). Koniecznie zapoznaj się także ze świetnym opisem dotyczącym implementacji sesji po stronie serwerów TLS.
Jeśli zdecydujesz się na włączenie biletów sesji, NGINX powinien wygenerować losowy klucz podczas uruchamiania i trzymać go w pamięci (ponadto odpowiednio nim zarządzać czego tak naprawdę nie robi). W ramach alternatywy, bilety sesji mogą być szyfrowane i deszyfrowane za pomocą tajnego klucza określonego jako plik za pomocą dyrektywy ssl_session_ticket_key — musi on zawierać 80 bajtów (do szyfrowania używany jest AES256) lub 48 bajtów (do szyfrowania używany jest AES128) losowych danych. Dyrektywa ta jest konieczna, jeśli ten sam klucz ma być współdzielony między wieloma wirtualnymi serwerami.
W starszych wersjach serwera NGINX istniała podatność (CVE-2014-3616), która w przypadku wykorzystania pamięci współdzielonej lub współdzielonego klucza sesji dla wielu wirtualnych hostów, pozwalała na ponowne wykorzystanie danych z buforowanej sesji (dla niepowiązanego z nimi kontekstu), co pozwalało napastnikom na przeprowadzanie ataków polegających na dezorientacji serwera obsługującego wirtualne hosty (ang. Virtual Host Confusion). Główną ideą tych ataków jest to, że gdy np. dwa serwery obsługują różne domeny, ale mają ten sam certyfikat (obejmujący oba), osoba atakująca może przejąć połączenie HTTPS przeznaczone dla jednego z tych wirtualnych hostów i przekierować je na inny lub kontrolując DNS może przekierować pierwszą domenę na drugi serwer. Więcej na ten temat poczytasz w pracy TLS Redirection (and Virtual Host Confusion).
W tym przypadku musisz pamiętać, aby odpowiednio „obracać” kluczem tak, by zapewnić mechanizm automatycznego odnawiania, np. restartując serwer co jakiś czas, co jednak nie zawsze rozwiązuje problem i nie jest bliskie prawdziwego rozwiązania. Co więcej, należy rozważyć przeniesienie tych kluczy do pamięci (wykorzystując np. tmpfs), jednak moim zdaniem rodzi to zbyt wiele komplikacji związanych z zarządzaniem. Niezależnie od tego, przed jego ustawieniem, polecam zapoznać się z RFC 4086 - Randomness Requirements for Security. Pamiętajmy także, że po zamianie, stary plik klucza powinien być całkowicie zniszczony.
Vincent Bernat napisał świetne narzędzie do testowania mechanizmu wznawiania sesji z wykorzystaniem ticket’ów.
Jeśli twoje serwery mają wystarczającą moc, możesz rozważyć całkowite wyłączenie identyfikatorów sesji i biletów sesji. Według mnie jest to nadal zalecane rozwiązanie, aby zapewnić tajemnicę przekazywania, ponieważ większość używanych serwerów HTTP (Apache, NGINX) nie obsługuje odpowiedniej rotacji tych parametrów. Co więcej, SSL Configuration Generator Mozilli, przedstawia wszystkie konfiguracje z wyłączonymi biletami sesji. Z drugiej strony, pamiętajmy, że koszt wydajności związany z niewykorzystaniem wznawiania sesji TLS jest znaczny. Na koniec polecam zapoznać się z ciekawych artykułem You like HTTPS. We like HTTPS. Except when a quirk of TLS can smash someone’s web privacy, który opisuje problemy z prywatnością (śledzeniem użytkowników) w kontekście wykorzystania mechanizmów wznawiania.
Przykład konfiguracji:
# context: http, server
# default: on
ssl_session_tickets off;
Oficjalna dokumentacja: ssl_session_tickets.
Rozmiar bufora danych #
Parametr ten odpowiada za kontrolę rozmiaru rekordu (rozmiaru bufora) przesyłanych danych za pomocą protokołu TLS i nie ma żadnego związku z buforowaniem sesji. Klient może odszyfrować dane dopiero po otrzymaniu pełnego rekordu, zaś jego rozmiar może mieć znaczący wpływ na wydajność aplikacji w czasie ładowania strony. Długość sesji może się różnić w zależności od wynegocjowanego rozmiaru klucza, różnych negocjowanych rozszerzeń TLS i tak dalej. Jest to jeden z tych parametrów, dla którego spotkać można różne wartości i wyciągnąć wniosek, że idealny rozmiar nie istnieje. Spowodowane jest to pewną niejednoznacznością oraz problemami występującymi w sieci, która wykorzystuje protokół TCP.
Aby dostosować wartość tego parametru, należy pamiętać m.in. o rezerwacji miejsca na różne opcje TCP (znaczniki czasu, skalowanie okna czy opcje selektywnego potwierdzania, tj. SACK), które mogą zajmować do 40 bajtów. Uwzględnić należy także rozmiar rekordów TLS (pamiętaj, że uścisk dłoni jest pełen małych pakietów), który zmienia się w zależności od wynegocjowanego szyfru między klientem a serwerem (średnio od 20 do 60 bajtów jako narzut protokołu TLS). Istotne jest także to, że przeglądarka (klient) może korzystać z danych dopiero po całkowitym otrzymaniu rekordu TLS, stąd wartość tego parametru powinna być mniej więcej taka, jak rozmiar segmentu TCP.
Tym samym można przyjąć: 1500 bajtów (MTU) - 40 bajtów (IP) - 20 bajtów (TCP) - 60-100 bajtów (narzut TLS) ~= 1300 bajtów.
Ciekawostka: jeżeli sprawdzisz rekordy zwracane przez serwery Google, zobaczysz, że zawierają one ok. 1300 bajtów danych.
Pamiętajmy, że protokół TCP dokłada wszelkich starań, aby dostarczyć dane i wykorzystuje do tego kilka metod, aby to osiągnąć. Na przykład, najpierw potwierdza wszystkie pakiety TCP i ponownie wysyła wszystkie niezatwierdzone pakiety. Dodatkowo działa całkiem nieźle w sieci i uruchamia się powoli, rozwijając się do pełnej pojemności w procesie znanym jako powolny start TCP (ang. TCP Slow Start), delikatnie wyczuwając zapotrzebowanie sieci i sprawdzając, czy nie ma zatorów prowadzących do zgubionych (niezatwierdzonych) pakietów. Aby zoptymalizować opóźnienie uzgadniania, po stronie klienta można skorzystać z mechanizmu szybkiego otwierania protokołu TCP (ang. TCP Fast Open), który został opisany w RFC 7413 [IETF]. W takim przypadku początkowe uzgadnianie TCP jest eliminowane, zmniejszając uzgadnianie protokołu TLSv1.2 w obie strony do 2, a uzgadnianie protokołu TLSv1.3 w jedną podróż w obie strony.
Co równie istotne, spakowanie każdego rekordu TLS do dedykowanego pakietu powoduje dodatkowe obciążenie związane z tworzeniem ramek i prawdopodobnie zajdzie potrzeba ustawienia większych rozmiarów rekordów (większy rozmiar rekordu optymalizuje przepustowość), jeśli przesyłasz strumieniowo większe (i mniej wrażliwe na opóźnienia) dane. Gdzie pojawiają się ograniczenia? W przypadku typowego serwera HTTP wysyła on dane do warstwy TLS, która z kolei tworzy rekord o danym rozmiarze (dla NGINX jest to 16 KB), a następnie przekazuje go do stosu TCP. Jednak im większy rozmiar rekordu TLS, tym większe prawdopodobieństwo, że możemy ponieść dodatkowy koszt z powodu retransmisji TCP lub „przepełnienia” okna TCP (ang. TCP Congestion Window), co może spowodować buforowanie danych po stronie klienta.
Rozwiązanie jest w miarę proste i polega na wysyłaniu mniejszych rekordów tak, aby pasowały do jednego segmentu TCP. Jeśli okno przeciążenia TCP jest małe, tj. podczas powolnego startu sesji lub jeśli wysyłamy interaktywne dane, które powinny zostać przetworzone jak najszybciej (czyli większość ruchu HTTP), wówczas mały rozmiar rekordu pomaga zmniejszyć kosztowne opóźnienie związane z opóźnieniami innych warstw buforowania.
W dokumentacji serwera NGINX znajduje się następujące zalecenie:
By default, the buffer size is 16k, which corresponds to minimal overhead when sending big responses. To minimize Time To First Byte it may be beneficial to use smaller values, for example: ssl_buffer_size 4k;
Myślę jednak, że w przypadku stałego rozmiaru, optymalną wartością jest wartość 1400 bajtów (lub bardzo zbliżona). 1400 bajtów (tak naprawdę powinno być nawet nieco niższe zgodnie z wcześniej zaprezentowanym równaniem) jest zalecanym ustawieniem dla ruchu interaktywnego, w którym głównie chodzi o uniknięcie niepotrzebnych opóźnień spowodowanych utratą/fluktuacją fragmentów rekordu TLS.
Spójrzmy także na poniższą rekomendację (wydaje mi się, że autorami są Leif Hedstrom, Thomas Jackson oraz Brian Geffon, niestety nie mogę znaleźć jej źródła):
- mniejszy rozmiar rekordu TLS = MTU/MSS (1500) - TCP (20 bytes) - IP (40 bytes) = 1440 bytes
- większy rozmiar rekordu TLS = maksymalny rozmiar wynosi 16,383 (2^14 - 1) bytes
Przykład konfiguracji:
# context: http, server
# default: 16k
ssl_buffer_size 1400;
Oficjalna dokumentacja: ssl_buffer_size.
TLS Dynamic Record Sizing #
Na koniec pomówmy jeszcze o jednej bardzo istotnej kwestii, mianowicie o dynamicznym rozmiarze rekordu TLS, który może mieć (niekiedy znaczący, innym razem bardzo delikatny) wpływ na wydajność połączenia, pozwalając najskuteczniej współdziałać z protokołami warstw niższych, takimi jak TCP. W najgorszym wypadku, który niestety jest obecnie dosyć częstą sytuacją występującą w sieci, nieoptymalny rozmiar rekordu może opóźnić przetwarzanie otrzymanych danych. Na przykład, w sieciach komórkowych może to przełożyć się na setki milisekund niepotrzebnego opóźnienia.
Omawiany chwilę temu stały rozmiar bufora ma niestety pewne wady i są one ściśle związane z warstwową budową sieci. Rekord TLS zwykle ma rozmiar 16 KB, co może powodować problemy, gdy implementacje próbują dopasować rekord TLS o takim rozmiarze do ładunków protokołu warstwy znajdującej się niżej. Niestety, segmenty TCP i rekordy TLS najczęściej nie są tego samego rozmiaru. Dzieje się tak, ponieważ protokół TLS dzieli przesyłane dane na rekordy o ustalonym (maksymalnym) rozmiarze (w NGINX odpowiada za to parametr ssl_buffer_size), a następnie przekazuje te rekordy do protokołu TCP, który występuje w warstwie niżej. TCP natychmiast dzieli te rekordy na segmenty, które są następnie przesyłane. Ostatecznie segmenty te są wysyłane w pakietach IP, które przemierzają sieci lokalne i Internet.
Aby zapobiec zatorom w sieci i zapewnić niezawodne dostarczanie danych, TCP wyśle tylko ograniczoną liczbę segmentów przed oczekiwaniem na potwierdzenie ich odebrania przez drugą stronę komunikacji. Ponadto protokół TCP gwarantuje, że segmenty są dostarczane do aplikacji stąd jeśli pakiet zagubi się gdzieś między nadawcą a odbiorcą, najprawdopodobniej reszta segmentów zostanie zatrzymana w buforze, czekając na przesłanie brakującego segmentu, zanim bufor zostanie zwolniony do aplikacji.
Jednak w przypadku protokołu TLS mamy dodatkową warstwę buforowania ze względu na kontrole integralności. Gdy TCP dostarczy pakiety do warstwy TLS, która jest nad nim, musimy najpierw zgromadzić cały rekord, a następnie zweryfikować jego sumę kontrolną MAC i tylko wtedy, gdy się to powiedzie, możemy zwolnić dane do aplikacji, która jest w warstwie wyżej. W rezultacie, jeśli serwer emituje dane w porcjach po 16 KB, odbiorca musi również odczytywać dane o takim rozmiarze.
Innymi słowy, nawet jeśli odbiorca ma 15 kilobajtów rekordu w buforze i czeka na ostatni pakiet, aby ukończyć 16 kilobajtowy rekord, aplikacja nie może go odczytać, dopóki cały rekord nie zostanie odebrany i nie zostanie obliczona i zweryfikowana suma kontrolna - w tym leży główny problem jeśli chodzi o opóźnienia.
Jak już pewnie zauważyłeś, cierpią na tym najbardziej protokoły znajdujące nad protokołem TCP, tj. HTTP oraz TLS, ponieważ wraz ze wzrostem współczynnika utraty pakietów działają one coraz gorzej. Protokół HTTP/2 rozwiązuje po części problem poprzez multipleksowanie, jednak sumarycznie i tak to nic nie daje, ponieważ używa TCP jako transportu, więc wszystkie jego strumienie mogą być blokowane, gdy utracony zostanie pojedynczy pakiet TCP. Taka sytuacja jest określona jako blokowanie na początku linii (ang. TCP head of line blocking), której chyba idealnym rozwiązaniem byłoby uruchomienie HTTP/2 przez UDP. Sytuacja pogarsza się, im gorszej jakości sieć jest wykorzystywana (utrata choćby 2% pakietów, świadczy o bardzo niskiej, wręcz tragicznej jakości sieci). Jeden utracony pakiet w strumieniu TCP powoduje, że wszystkie strumienie czekają, aż pakiet zostanie ponownie przesłany i odebrany. Widzimy tym samym, że nakładanie się warstw TLS na TCP może powodować opóźnienia w dostarczaniu wiadomości.
Dla TLS oznacza to, że duży rekord podzielony na wiele segmentów TCP może napotkać nieoczekiwane opóźnienia. TLS może obsłużyć tylko pełne rekordy, dlatego brak segmentu TCP opóźnia cały rekord TLS i w konsekwencji całą komunikację. W przypadku parametru
ssl_buffer_sizei jednoczesnym wykorzystaniu protokołu HTTP/2 warto rozważyć modyfikację dyrektywyhttp2_chunk_size, która ustawia maksymalny rozmiar fragmentów, na które jest pocięte ciało odpowiedzi (myślę, że powinna ona być dostosowywana w zależności od wartości rekordu TLS tak, aby fragment HTTP2 zmieścił się w rekordzie TLS). Zbyt niska wartość spowoduje wyższe koszty ogólne, zaś zbyt wysoka, utrudni ustalanie priorytetów z powodu head of line blocking.
Statyczny rozmiar rekordu wprowadza kompromis między opóźnieniem a przepustowością - mniejsze rekordy są dobre dla opóźnienia, ale szkodzą przepustowości i obciążeniu procesora. Małe rekordy powodują nadmierne obciążenia, duże rekordy powodują zwiększone opóźnienia — nie ma jednej wartości dla optymalnego rozmiaru rekordu. Zamiast tego w przypadku aplikacji internetowych najlepszą strategią jest dynamiczne dostosowywanie jego rozmiaru (tak, aby uzyskać najlepszą wydajność) w zależności od stanu połączenia TCP.
Dynamiczne rozmiary rekordów skalowane w zależności od stanu połączenia TLS, eliminują tak naprawdę trzy istotne problemy:
- minimalizuje koszty ogólne procesora (po stronie klienta i serwera) w przypadku mniejszych rekordów
- dostarczamy najlepszy pierwszy bajt danych (TTFB) wysłanych przez serwer w przypadku rekordu wielkości pakietu
- w większości przypadków pozwala zredukować dodatkowe obiegi dla TTTFB (ang. TLS Time to first byte)
Ogólnie rzecz biorąc, ma to na celu optymalizację przyrostowego dostarczania małych plików, jednak sprawdza się także w przypadku dużych pobrań, w których priorytetem jest ogólna przepustowość.
W idealnym scenariuszu sytuacja powinna wyglądać tak:
- nowe połączenia domyślnie mają mały rozmiar rekordu
- każdy rekord mieści się w pakiecie TCP
- pakiety są opróżniane (wysyłane) na granicach rekordów
- serwer śledzi liczbę zapisanych bajtów od czasu resetu i znacznik czasu ostatniego zapisu
- jeśli zapisano pewien próg danych (zastosowana strategia polega zasadniczo na użyciu małych rekordów TLS, które pasują do jednego segmentu TCP dla pierwszych ~1MB danych), to zwiększ rozmiar rekordu do 16 KB
- jeśli znacznik czasu ostatniego zapisu został przekroczony, zresetuj licznik wysłanych danych
W celu rozwiązania tych problemów, inżynierowie Cloudflare stworzyli poprawkę domyślnego mechanizmu, która dodaje obsługę dynamicznego rozmiaru rekordów TLS i wprowadza inteligentniejszą strategię zarządzania tym mechanizmem z poziomu serwera NGINX (dostępna jest ona np. we FreeBSD jako jedna z opcji do wyboru podczas kompilacji).
Krótko mówiąc, umożliwia ona, aby zamiast statycznego rozmiaru bufora ustalonego z poziomu ssl_buffer_size (ustalony rozmiar rekordu TLS z domyślną wartością 16 KB), początkowe żądania zmieściły się w najmniejszej możliwej liczbie segmentów TCP, a następnie były zwiększane w zależności od obciążenia sieci. Rozpoczynanie od małego rozmiaru rekordu pomaga dopasować rozmiar rekordu do segmentów wysyłanych przez TCP na początku połączenia. Po uruchomieniu połączenia rozmiar rekordu można odpowiednio dostosować do panujących warunków w sieci.
Gdy połączenie jest nowe, najlepszą strategią jest zmniejszenie rozmiaru rekordu podczas wysyłania nowej serii danych. W takim przypadku, jeśli okno przeciążenia TCP jest niskie lub gdy połączenie było bezczynne przez pewien czas, każdy pakiet TCP powinien przenosić dokładnie jeden rekord TLS, a rekord TLS powinien zajmować pełny maksymalny segment (ang. MSS - Maximum Segment Size), równy rozmiarowi ramki Ethernetowej, tj. 1460 bajtów, przydzielany przez TCP. Gdy okno przeciążenia połączenia jest duże i jeśli przesyłamy duży strumień (np. strumieniowanie wideo), rozmiar rekordu TLS można zwiększyć, tak aby obejmował wiele segmentów TCP (do 16 KB), w celu zmniejszenia ramkowania i obciążenie procesora klienta oraz serwera.
Zasada działania tej modyfikacji jest następująca: każde połączenie rozpoczyna się od małych rekordów (ssl_dyn_rec_size_lo o domyślnej wartości 1369 bajtów). Dlaczego małych? Chodzi o to, aby początkowe rekordy pasowały do jednego segmentu TCP oraz by nie były blokowane (problem TCP head of line blocking) z powodu powolnego startu TCP. Po określonej liczbie rekordów (ssl_dyn_rec_threshold o domyślnej wartości 40) rozpoczyna się zwiększanie ich rozmiaru (aby zmniejszyć obciążenie nagłówka; co więcej jesteśmy w stanie uniknąć blokowania HoL pierwszego bajtu). Wniosek z tego taki, że po 41 rekordach, czyli przesłaniu 54 KB (41 x 1369 bajtów = 56 129 bajtów) rozpoczyna się wysyłanie rekordów o wartość odpowiednio zmodyfikowanej do wartości 4229 bajtów (ssl_dyn_rec_size_hi), czyli trzykrotnie (do 3 pakietów TCP). Następnie po kolejnych 40 rekordach, czyli przesłaniu 165 KB (40 x 4229 = 169 160 bajtów), wartość jest ponownie zwiększana tym razem do maksymalnego rozmiaru bufora (ssl_buffer_size), czyli jego domyślnej wartości 16384 bajtów.
Powyższe można zobrazować tak: zacznij od małej wielkości rekordu, aby zoptymalizować dostarczanie małych/interaktywnych danych (większość ruchu HTTP). Następnie, jeśli przesyłany jest duży plik, zwiększ rozmiar rekordu do 16 KB i kontynuuj korzystanie z niego, dopóki połączenie nie przestanie działać. Po wznowieniu komunikacji zacznij ponownie od małego rozmiaru rekordu.
Co więcej, jeśli połączenie pozostaje bezczynne przez czas dłuższy niż ten określony za pomocą zmiennej ssl_dyn_rec_timeout (domyślnie 1s), rozmiar rekordu TLS jest zmniejszony do ssl_dyn_rec_size_lo i cała logika jest powtarzana (rozpoczyna się ponownie od małych rekordów). Jeśli wartość ssl_dyn_red_timeout jest ustawiona na 0, wówczas dynamiczne rozmiary rekordów TLS są wyłączone (całym mechanizmem możemy sterować również za pomocą ssl_dyn_rec_enable gdzie wartość off go wyłącza, a on włącza) i zamiast tego zostanie użyty stały rozmiar określony za pomocą ssl_buffer_size.
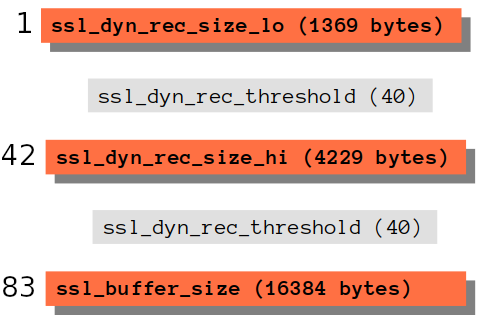
Domyślna wartość rozmiaru początkowych rekordów, tj. 1369 bajtów została zaprojektowana, aby zmieścić cały rekord w jednym segmencie TCP (TLS + IPv6 w jednym segmencie TCP dla małych rekordów i 3 segmentach dla dużych rekordów): 1500 bajtów (MTU) - 20 bajtów (TCP) - 40 bajtów (IP) - 10 bajtów (znaczniki czasu) - 61 (maksymalne obciążenie/narzut TLS) = 1369 bajtów. Narzut TLS zmienia się w zależności od wybranego szyfru (zerknij na drafty: Overview and Analysis of Overhead Caused by TLS - 3.2. Traffic Overhead [IETF] oraz Record Size Limit Extension for Transport Layer Security (TLS) [IETF]), jednak każdy rekord doda od 20 do 40 bajtów narzutu dla nagłówka, MAC czy opcjonalnego wypełnienia. Moim zdaniem, jest tutaj pewna wada, mianowicie wartości ssl_dyn_rec_size_lo/ssl_dyn_rec_size_hi powinny być automatycznie dostosowywane na podstawie używanego szyfru, ponieważ różne szyfry mają różne maksymalne rozmiary rekordów TLS (GCM/CHACHA-POLY np. ma tylko 29 bajtów narzutu co stanowi ok. połowę z 61 bajtów z powyższego obliczenia).
Koniecznie zapoznaj się z dokumentem Overview and Analysis of Overhead Caused by TLS [IETF], w którym opisano, z czego dokładnie składa się pojawiający narzut i jaki mają na niego wpływ różne typy szyfrów dla protokołu TLS.
Zwiększenie rozmiaru rekordu do jego maksymalnego rozmiaru (16 KB) niekoniecznie jest dobrym pomysłem, jednak należy też pamiętać, że im mniejszy rekord, tym wyższe koszty ramkowania. Jeśli rekord obejmuje wiele pakietów TCP, wówczas warstwa TLS musi poczekać, aż wszystkie pakiety TCP dotrą do miejsca docelowego, zanim będzie mogła odszyfrować dane. Jeśli którykolwiek z tych pakietów TCP zostanie zgubiony, nastąpi zmiana ich kolejności lub będzie dławiony z powodu kontroli przeciążenia, poszczególne fragmenty rekordu TLS będą musiały zostać buforowane przed dekodowaniem, co spowoduje dodatkowe opóźnienie. W praktyce opóźnienia te mogą powodować znaczne wąskie gardła dla przeglądarki, która woli pobierać dane w sposób strumieniowy.
Co istotne, poprawka jest w pełni konfigurowalna z poziomu kontekstu http {...} serwera NGINX. Odpowiadają za to następujące dyrektywy zdefiniowane w pliku src/http/modules/ngx_http_ssl_module.c:
{ ngx_string("ssl_dyn_rec_enable"),
NGX_HTTP_MAIN_CONF|NGX_HTTP_SRV_CONF|NGX_CONF_FLAG,
ngx_conf_set_flag_slot,
NGX_HTTP_SRV_CONF_OFFSET,
offsetof(ngx_http_ssl_srv_conf_t, dyn_rec_enable),
NULL },
{ ngx_string("ssl_dyn_rec_timeout"),
NGX_HTTP_MAIN_CONF|NGX_HTTP_SRV_CONF|NGX_CONF_FLAG,
ngx_conf_set_msec_slot,
NGX_HTTP_SRV_CONF_OFFSET,
offsetof(ngx_http_ssl_srv_conf_t, dyn_rec_timeout),
NULL },
{ ngx_string("ssl_dyn_rec_size_lo"),
NGX_HTTP_MAIN_CONF|NGX_HTTP_SRV_CONF|NGX_CONF_FLAG,
ngx_conf_set_size_slot,
NGX_HTTP_SRV_CONF_OFFSET,
offsetof(ngx_http_ssl_srv_conf_t, dyn_rec_size_lo),
NULL },
{ ngx_string("ssl_dyn_rec_size_hi"),
NGX_HTTP_MAIN_CONF|NGX_HTTP_SRV_CONF|NGX_CONF_FLAG,
ngx_conf_set_size_slot,
NGX_HTTP_SRV_CONF_OFFSET,
offsetof(ngx_http_ssl_srv_conf_t, dyn_rec_size_hi),
NULL },
{ ngx_string("ssl_dyn_rec_threshold"),
NGX_HTTP_MAIN_CONF|NGX_HTTP_SRV_CONF|NGX_CONF_FLAG,
ngx_conf_set_num_slot,
NGX_HTTP_SRV_CONF_OFFSET,
offsetof(ngx_http_ssl_srv_conf_t, dyn_rec_threshold),
NULL },
Poniżej znajdują się domyślne wartości każdego z parametrów:
ssl_dyn_rec_enable off;ssl_dyn_rec_timeout 1000;(ms) = 1sssl_dyn_rec_size_lo 1369;(bytes) = ~1KBssl_dyn_rec_size_hi 4229;(bytes) = ~4KBssl_dyn_rec_threshold 40;
Poprawkę można pobrać z oficjalnego repozytorium oraz zaaplikować ręcznie, w tym celu należy wykonać:
git clone https://github.com/nginx/nginx
cd nginx/
patch -p1 < nginx__dynamic_tls_records.patch
Ogólny wniosek jest taki, że lepiej nie używać ustalonego rozmiaru rekordu TLS, ale dostosować jego rozmiar w trakcie połączenia (zwiększać w przypadku braku zatorów w sieci i zmniejszać w przypadku przeciążenia). Głównym celem jest zminimalizowanie prawdopodobieństwa buforowania w warstwie aplikacji z powodu utraconych pakietów, zmian kolejności pakietów oraz retransmisji. Wszystko to zapewnia najlepszą wydajność dla ruchu interaktywnego (jednak korzyści mogą się różnić w zależności od wielu czynników).
W celu pełnego zrozumienia opisywanego problemu polecam przeczytać książkę High Performance Browser Networking (autor: Ilya Grigorik) oraz w szczególności rozdział Optimizing for TLS - Optimize TLS Record Size a także artykuł tego samego autora Optimizing TLS Record Size & Buffering Latency.
Warto jeszcze pamiętać o ew. dostrojeniu parametrów jądra i przeprowadzeniu testów po wprowadzeniu poprawki, w tym testów porównujących wydajność połączenia wykorzystującego dynamiczną oraz stałą wartość rozmiaru rekordu (ustawianą za pomocą parametru ssl_buffer_size tj. zalecaną 4 kilobajty).
O czym jeszcze warto wiedzieć? #
Inną kwestią, o której nie możemy zapomnieć podczas dostrajania parametrów SSL/TLS, jest wersja protokołu HTTP. Pamiętajmy, że HTTP/2 używa jednego połączenia przy komunikacji z serwerem, zamiast jednego połączenia na żądanie zasobu, znacznie poprawiając efektywność komunikacji HTTPS (dzięki tylko jednemu kosztownemu uzgadnianiu TLS). Co więcej, dzięki multipleksowaniu maksymalizujemy wykorzystanie pojedynczego połączenia — oznacza to znacznie mniejszą potrzebę czasochłonnej konfiguracji połączenia, co jest szczególnie korzystne w przypadku TLS, ponieważ tworzenie połączeń TLS jest szczególnie wymagające czasowo. Jeżeli mamy możliwość implementacji HTTP/3, warto rozważyć jego wdrożenie. Przy okazji zerknij na artykuł Comparing HTTP/3 vs. HTTP/2 Performance oraz genialną pracę Performance testing HTTP/1.1 vs HTTP/2 vs HTTP/2 + Server Push for REST APIs.
Wiemy już, że w przypadku protokołu HTTPS należy dodać dwa kolejne RTT, aby negocjować wszystkie wymagane parametry połączenia. Wiemy także, że pełne uzgadnianie protokołu TLSv1.2 wymaga do ukończenia dwóch podróży w obie strony, a w połączeniu z negocjacjami TCP SYN i SYN-ACK rozciąga się do trzech pełnych połączeń w obie strony. Chociaż protokół TLSv1.3 redukuje to do dwóch obiegów w przypadku TCP, nadal powoduje znaczne opóźnienie, co sprawia, że protokół jest nieodpowiedni dla niektórych aplikacji. W przypadku ograniczenia konfiguracji jedynie do protokołu TLSv1.2 (czyli najczęściej wykorzystywanej wersji) i sesji, które nie zostały wznowione, można jeszcze bardziej zmniejszyć liczbę rund do jednej, korzystając z rozszerzenia TLS False Start (patrz: Transport Layer Security (TLS) - Enable TLS False Start).
Ciekawostka: Serwer NGINX w wersji <1.5.6 miał pewien feler, otóż zastosowanie certyfikatów o rozmiarze przekraczającym 4 KB wiązało się z dodatkową podróżą w obie strony, zamieniając uzgadnianie w obie strony w trzy transakcje (patrz: NGINX Changelog — Feature: optimization of SSL handshakes when using long certificate chains). Co gorsza, w niektórych specyficznych przypadkach dochodziło do przekroczenia krawędzi w stosie TCP, co powodowało, że klient potwierdzał kilka pierwszych pakietów z serwera, a następnie czekał, zanim wyzwolone zostanie opóźnione potwierdzenie ACK dla ostatniego segmentu.
Oczywiście kluczowa wydaje się tutaj optymalizacja opóźnień, ponieważ idąc za 7 Tips for Faster HTTP/2 Performance, w przypadku stron internetowych o mieszanej treści wymienianych przez połączenia z typowymi opóźnieniami w Internecie, protokół HTTP/2 działa lepiej niż HTTP/1.x i HTTPS. Poniżej znajdują się wyniki podzielone na trzy grupy w zależności od typowego czasu połączenia w obie strony (RTT):
- bardzo niskie RTT (0 - 20 ms) - praktycznie nie ma różnicy między opisywanymi protokołami
- typowe RTT (30 - 250 ms) występujące przy połączeniach internetowych - protokół HTTP/2 jest szybszy niż HTTP/1.x i oba są szybsze niż HTTPS
- wysokie RTT (300 ms i więcej) - HTTP/1.x jest szybsze niż HTTP/2, które jest szybsze niż HTTPS
W kontekście wersji protokołu HTTP pojawia się jeszcze jeden ciekawy problem, tj. pierwsze 14 KB danych, które odbiera przeglądarka. Autorem wyjaśnienia jest Barry Pollard, autor świetnej książki HTTP/2 in Action. Dokładne przedstawienie znajduje się w artykule Critical Resources and the First 14 KB - A Review i mimo tego, że nie jest on ściśle związanych z protokołem TLS, to warto się z nim zapoznać.
Pamiętajmy, że TLS wymaga, aby klienci odpowiadali podczas uzgadniania, co oznacza, że mogą również potwierdzać niektóre z wcześniej wysłanych pakietów TCP w tym samym czasie, zwiększając rozmiar okna przeciążenia (oraz opisany przez autora powyższego artgykułu limit 10 pakietów). Widzisz, że pole do optymalizacji jest tak naprawdę na każdej warstwie i dla każdego protokołu.
Jeszcze inną optymalizacją może być alternatywne podejście do protokołu OCSP w celu sprawdzania stanu odwołania certyfikatów. Włączenie mechanizmu OCSP Stapling pozwala przenieść drugie żądanie sieciowe z przeglądarki internetowej na serwer. W przeciwieństwie do „czystego” OCSP w mechanizmie OCSP Stapling przeglądarka użytkownika nie kontaktuje się z wystawcą certyfikatu, ale robi to w regularnych odstępach czasu przez serwer aplikacji.
Dzięki takiemu rozwiązaniu będzie on okresowo komunikował się z urzędem certyfikacji, odbierając odpowiedź OCSP, a następnie odsyłając je, gdy przeglądarka internetowa rozpocznie połączenie za pomocą protokołu HTTPS. Dlaczego jest to istotne? W przypadku urządzeń mobilnych i sieci komórkowych sprawdzanie, czy certyfikat został odwołany, może spowodować wzrost narzutu połączenia nawet o 30% (patrz: Rethinking SSL for Mobile Apps), a niektórych sytuacjach jeszcze więcej.
Niestety, ta kontrola nie jest wykonywana równolegle. W większości przeglądarek do czasu zakończenia sprawdzania unieważnienia przeglądarka nie rozpocznie pobierania żadnych dodatkowych treści. Innymi słowy, sprawdzenie OCSP blokuje dostarczanie treści i nieodłącznie wydłuża żądanie o znaczną ilość czasu. Widzimy, że zaimplementowanie mechanizmu OCSP Stapling eliminuje potrzebę kontaktowania się klientów z CA, zmniejszając opóźnienia. Więcej o wydajności tego rozwiązania poczytasz w artykule The impact of SSL certificate revocation on web performance.
Na koniec należy wspomnieć o parametrze TTFB (ang. Time to first byte), który możemy traktować jako czas od wysłania przez klienta żądania HTTP do pierwszego bajta odebranych przez niego danych. Mówiąc prościej, jest to miara tego, jak długo przeglądarka musi czekać, zanim otrzyma swój pierwszy bajt danych z serwera. Im dłużej trwa pobranie tych danych, tym dłużej trwa renderowanie strony. Jednak parametr ten nie zawsze zależy od serwera. Przykładem mogą być zasoby, które przekazywane są przez serwery CDN — czas potrzebny na ich odebranie może zostać wliczony do TTFB. Z drugiej strony, wysoki TTFB oznacza najczęściej po prostu wolne czasy odpowiedzi z serwera, a nie problemy z samym dostarczeniem żądanych przez klienta treści (za to odpowiadają raczej inne opóźnienia).
Według Understanding Resource Timing - Slow Time to First Byte TTFB jest czasem spędzonym na oczekiwaniu na pierwszą odpowiedź, znanym również jako czas do pierwszego bajtu. W tym czasie oprócz czasu spędzonego na oczekiwaniu na dostarczenie odpowiedzi przez serwer jest rejestrowane opóźnienie w obie strony do serwera. W celu sprawdzenia opóźnień możemy wykorzystać narzędzia online takie jak Site24, Sucuri LoadTimeTester, GTmetrix czy bytecheck.
Zgodnie z powyższym dokumentem, aby rozwiązać problem wysokiego TTFB, najpierw powinniśmy zredukować połączenia sieciowe między klientem a serwerem (a przyczyn może być wiele, np. niezoptymalizowane reguły firewall’a czy problemy z tabelami routingu). W tym wypadku najlepiej jest uruchomić aplikację lokalnie i sprawdzić, czy nadal istnieje duży TTFB. Jeśli tak, aplikacja musi zostać zoptymalizowana. Może to oznaczać optymalizację zapytań do bazy danych, implementację pamięci podręcznej dla określonych części treści lub modyfikację konfiguracji serwera HTTP. Natomiast jeśli TTFB lokalnie jest niskie, problem najprawdopodobniej stanowią sieci między klientem a serwerem.
Po drugie, wiele artykułów opisuje TTFB jako niezwykle ważny element optymalizacyjny. Nie neguję tego w żaden sposób, jednak spójrz na poniższy wykres pokazujący wszystkie czasy i opóźnienia:
Widzimy, że parametr TTFB nie jest w tym konkretnym przypadku problemem, a główne pole do optymalizacji powinno dotyczyć właśnie protokołów SSL/TLS. W tym miejscu polecam bardzo ciekawy artykuł Stop worrying about Time To First Byte (TTFB).
Pamiętajmy też, że między klientami a serwerami jest wiele punktów, a każdy z nich ma własne ograniczenia połączeń i może powodować problemy. Najprostszą metodą przetestowania zmniejszenia tego jest umieszczenie aplikacji na innym hoście i sprawdzenie, czy TTFB się poprawi. Drugim parametrem, który nas interesuje, zwłaszcza w kontekście optymalizacji, jest parametr TLS TTFB (ang. TLS Time to first byte), który został dokładnie opisany w świetnym artykule Optimizing NGINX TLS Time To First Byte (TTTFB).
Nie zapominajmy oczywiście o jednym z najważniejszych elementów, tj. samej aplikacji, ponieważ najprawdopodobniej najwięcej możliwości do optymalizacji będzie właśnie po jej stronie. Na przykład, jeśli użytkownik wejdzie na stronę, spowoduje to jej wyrenderowanie, zbudowanie widgetów, pobranie wszystkich informacji o niej, tj. routingu, listy przekierowań, zawartość strony, itd. Na czas wyrenderowania wpływa kilka głównych czynników:
- szybkość interpretacji samego języka
- budowy danej aplikacji i jej złożoności
- szybkości maszyn i baz danych
- integracje i oczekiwanie na zewnętrzne serwisy
- wielkość pobieranych danych z bazy
- wielkość zasobów
Na koniec można zastanowić się nad optymalizacją protokołu TCP, w tym regulacji okna przeciążenia, szybkiego otwieranie TCP, obsługi ponownego użycia czy wyborze optymalnego algorytmu kontroli przeciążenia (z doświadczenia wiem jednak, że protokoły warstwy transportu są najmniejszym problemem w przypadku problemów z wydajnością).