NGINX: sendfile, tcp_nodelay i tcp_nopush
18 Feb 2019
best-practices http nginx performance sendfile tcp tcp_nodelay tcp_nopush
Większość artykułów dotyczących optymalizacji wydajności serwera NGINX zaleca użycie opcji sendfile, tcp_nodelay i tcp_nopush. Niestety, niektóre z nich nie mówią o tym, jak działają, jaki mają wpływ na siebie oraz w jaki sposób ich stosowanie (bądź nie) może wpłynąć na wydajność i działanie samego NGINX-a.
W tym artykule poruszę kwestię wydajności w nawiązaniu do tych trzech parametrów oraz konsekwencje ich stosowania, a także wyjaśnię praktyczne aspekty ich użycia.
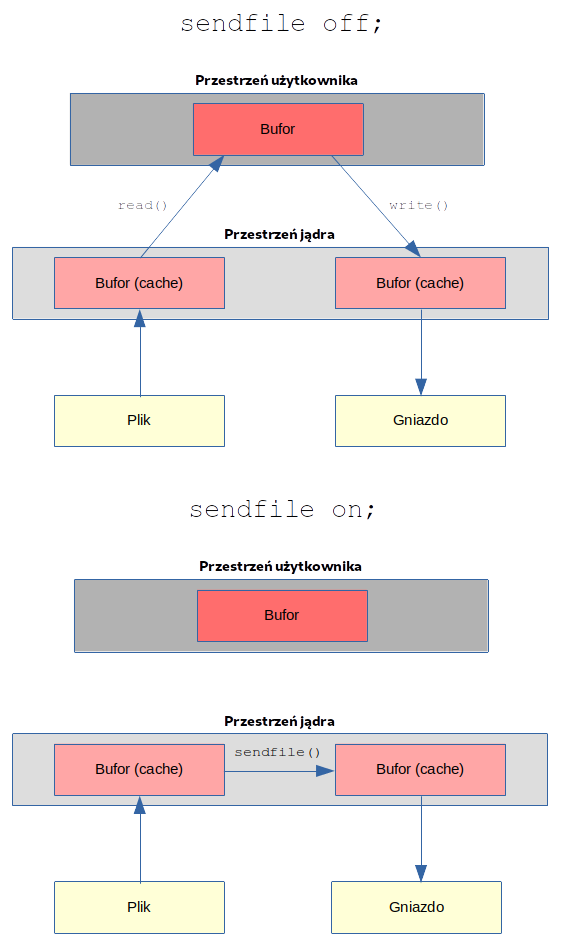
sendfile #
Domyślnie NGINX obsługuje samą transmisję pliku i kopiuje go do bufora przed wysłaniem. Włączenie funkcji sendfile eliminuje etap kopiowania danych do bufora i umożliwia bezpośrednie kopiowanie danych z jednego deskryptora pliku do drugiego.
Jądro robi to poprzez implementację bufora potoków jako zestawu wskaźników do stron pamięci jądra. Tworzy „kopie” stron w buforze, tworząc nowe wskaźniki (dla bufora wyjściowego). Co więcej, kopiowane są tylko wskaźniki, a nie strony bufora.
Zwykle, gdy plik musi zostać wysłany, wykonywane są następujące funkcje:
malloc()- przydziela lokalny bufor do przechowywania danych obiektówread()- pobiera i kopiuje obiekt do lokalnego bufora, np.read(file, tmp_buf, len);write()- kopiuje obiekt z bufora lokalnego do bufora gniazda, np.write(socket, tmp_buf, len);
Jeżeli myślisz, że wywołania tych funkcji nie są kosztowne, zerknij na artykuł Zero Copy I: User-Mode Perspective — jest już leciwy, bo z 2003 roku jednak bardzo ciekawie opisuje problem i wyjaśnia możliwe rozwiązania.
Gdy plik jest przesyłany przez proces (komunikacja międzyprocesowa), jądro najpierw buforuje dane, a następnie wysyła dane do buforów procesu. Z kolei proces wysyła dane do miejsca docelowego.
NGINX stosuje rozwiązanie, które wykorzystuje wywołanie systemowe sendfile do wykonania „zerowego przepływu” (ang. zero-copy) danych z dysku do gniazda i zapisuje przełączanie kontekstu z przestrzeni użytkownika podczas odczytu/zapisu. Parametr sendfile informuje, w jaki sposób NGINX buforuje lub odczytuje plik (próbując „wpychać” zawartość bezpośrednio do gniazda sieciowego lub najpierw buforować jej zawartość).
Ta metoda jest ulepszoną metodą przesyłania danych, w której dane są kopiowane między deskryptorami plików w przestrzeni jądra systemu operacyjnego, to znaczy bez przesyłania danych do buforów aplikacji poprzez umożliwienie aplikacjom przestrzeni użytkownika uniknięcie dodatkowych instrukcji kopiowania. Nie są wymagane żadne dodatkowe bufory ani kopie danych, a dane nigdy nie opuszczają przestrzeni adresowej pamięci jądra.
Wywołanie sendfile jest mocno powiązane z wielkością ładunku (ang. payload) HTTP i zazwyczaj wzrost wydajności jest stały niezależnie od rozmiaru. Pozwala on na poprawienie wydajności serwera NGINX jednak zazwyczaj nieznacznie — współczynnik 1.1 względem standardowej obsługi bez tego wywołania systemowego.
Moim zdaniem włączenie tego naprawdę nie zrobi żadnej różnicy, chyba że NGINX odczyta coś, co można zmapować w przestrzeni pamięci wirtualnej jak plik (tzn. dane znajdują się w pamięci podręcznej).
Przed zastosowaniem tego parametru powinieneś zapoznać się z dokumentem Optimizing TLS for High–Bandwidth Applications in FreeBSD [PDF]. Polecam także świetny artykuł Nginx Tutorial #2: Performance, który wspomina m.in. o tej funkcji:
This involves two context switches (read, write) which make a second copy of the same object unnecessary. As you may see, it is not the optimal way. Thankfully, there is another system call that improves sending files, and it's called (surprise, surprise!): sendfile(2). This call retrieves an object to the file cache, and passes the pointers (without copying the whole object) straight to the socket descriptor. Netflix states that using sendfile(2) increased the network throughput from 6Gbps to 30Gbps.
Domyślnie, serwer NGINX wyłącza użycie sendfile (chociaż w nowszych konfiguracjach spotkałem się, że parametr ten jest włączony):
# Włącza użycie sendfile:
# - moja rekomendacja
# - w kontekstach: http, server, location, if
sendfile on;
# Wyłącza użycie sendfile:
# - zachowanie domyślne
sendfile off;
Jeżeli zdecydujesz się na włączenie tego parametru, zapoznaj się także z dyrektywą sendfile_max_chunk. Dokumentacja NGINX mówi:
When set to a non-zero value, limits the amount of data that can be transferred in a single `sendfile()` call. Without the limit, one fast connection may seize the worker process entirely.
Dla szybkiego połączenia lokalnego funkcja sendfile() (w systemie Linux) może wysyłać dziesiątki megabajtów na jeden proces blokujący inne połączenia. Parametr sendfile_max_chunk pozwala ograniczyć maksymalny rozmiar jednej operacji sendfile().
sendfile on;
sendfile_max_chunk 512k;
Dzięki temu NGINX może skrócić maksymalny czas spędzony na blokowaniu wywołań sendfile(), ponieważ nie będzie próbował wysłać całego pliku na raz, ale zrobi to we fragmentach.
tcp_nodelay #
Polecam zapoznać się z dwoma świetnymi dokumentami The Caveats of TCP_NODELAY oraz Rethinking the TCP Nagle Algorithm [PDF]. Opisują parametry dotyczące TCP_NODELAY i TCP_NOPUSH.
Parametr tcp_nodelay służy do zarządzania algorytmem Nagle, który jest jednym z mechanizmów poprawy wydajności protokołu TCP poprzez zmniejszenie liczby małych pakietów wysyłanych przez sieć. Jeśli ustawisz parametr tcp_nodelay on;, NGINX doda opcję TCP_NODELAY podczas otwierania nowego gniazda w celu wyłączenia tego algorytmu.
Zgodnie z dokumentacją, ta opcja wpływa tylko na połączenia wykorzystujące mechanizm KeepAlive. W przeciwnym razie występują opóźnienia 100 ms, gdy NGINX wysyła odpowiedź w ostatnim niekompletnym pakiecie TCP. Dodatkowo jest włączony dla połączeń SSL/TLS, dla niebuforowanego proxy i dla WebSocket proxy.
Powinieneś pomyśleć o włączeniu algorytmu Nagle (tcp_nodelay off;), ale tak naprawdę zależy to od określonego obciążenia i dominujących wzorców ruchu w sieci. tcp_nodelay on; jest bardziej rozsądny dla współczesnych sieci, ponieważ całe opóźnienie TCP związane było z terminalami.
Zazwyczaj sieci LAN mają mniej problemów z przeciążeniem ruchu w porównaniu do sieci WAN. Algorytm Nagle jest najbardziej skuteczny, jeśli ruch TCP/IP jest generowany sporadycznie przez dane wejściowe użytkownika, a nie przez aplikacje korzystające zwłaszcza z protokołów zorientowanych na strumień. Użycie TCP_NODELAY oznacza także, że to aplikacja staje się odpowiedzialna za buforowanie, ponieważ algorytm Nagle jest jedynie obroną przed nieostrożnymi aplikacjami i nie przyniesie korzyści (oraz nie ma tak naprawdę wpływu) aplikacji, która jest starannie napisana (tj. odpowiednio dba o buforowanie).
Więc dla mnie przepis jest prosty. Jeżeli obserwujesz masowe wysyłanie lub nieinteraktywny typ ruchu (w tym np. duże treści HTTP), nie ma potrzeby używania algorytmu Nagle’a. Spójrz, co na temat tego algorytmu mówi sam autor:
If you're doing bulk file transfers, you never hit that problem. If you're sending enough data to fill up outgoing buffers, there's no delay. If you send all the data and close the TCP connection, there's no delay after the last packet. If you do send, reply, send, reply, there's no delay. If you do bulk sends, there's no delay. If you do send, send, reply, there's a delay.
The real problem is ACK delays. The 200ms "ACK delay" timer is a bad idea that someone at Berkeley stuck into BSD around 1985 because they didn't really understand the problem. A delayed ACK is a bet that there will be a reply from the application level within 200ms. TCP continues to use delayed ACKs even if it's losing that bet every time.
Co szczególnie istotne, jeśli masz do czynienia z nieinteraktywnym rodzajem ruchu lub transferami masowymi, takimi jak streaming video, włączenie TCP_NODELAY w celu wyłączenia algorytmu Nagle może być przydatne (jest to domyślne zachowanie NGINX). Pamiętaj także, że jeśli ta opcja nie jest ustawiona, jądro nie wyśle pakietu TCP natychmiast po zakończeniu wywołania, np. send() — zamiast tego poczeka około 0,01 sekundy przed wysłaniem.
Możesz jednak zadać pytanie, co z ruchem HTTP (a także TLS), w którym w większości przesyłane są małe porcje interaktywnego ruchu? Niezwykle ciekawa dyskusja była prowadzona na forum Mozilla pod tematem set TCP_NODELAY for all SocketTransport sockets (not just SSL). Moim zdaniem, ustawienie opcji TCP_NODELAY gniazda sieciowego powinno przyspieszyć dostarczenie ostatniej porcji treści odpowiedzi HTTP.
Myślę, że idealną sytuacją powinno być ustawienie TCP_NODELAY po zapisaniu ostatniego bajtu odpowiedzi HTTP. Z drugiej strony, jeśli NGINX nie wysyła małych porcji danych ani nie wysyła ponownie wszystkich danych otrzymanych w innym gnieździe, dobrze, aby bezwarunkowo ustawiał opcję TCP_NODELAY, aby zminimalizować opóźnienie, ale także zminimalizować ilość pakietów na sekundę. Pamiętajmy jednak, że NGINX ustawia tę opcję tylko wtedy, gdy połączenie zostanie przełączone w stan podtrzymania połączenia. W przeciwnym razie wysyła opóźnienie 100 ms w ostatnim niekompletnym pakiecie TCP — stąd uważam, że zarządza tym mechanizmem bardzo rozsądnie.
Włączenie algorytmu Nagle’a może (ale nie musi) opóźnić przetwarzanie żądań. Wszystko zależy od specyfiki danej sieci i środowiska, dlatego dobrym pomysłem jest przeprowadzenie niezależnych testów w celu dokonania odpowiedniego wyboru.
Na koniec zacytuję dokumentację Linuksa dotyczącą programowania gniazd:
TCP_NODELAY is for a specific purpose; to disable the Nagle buffering algorithm. It should only be set for applications that send frequent small bursts of information without getting an immediate response, where timely delivery of data is required (the canonical example is mouse movements).
A jeżeli masz nadal wątpliwości co do ustawienia, zacytuję eksperta (Ilya Grigorik) w dziedzinie wydajności web aplikacji:
I'd recommend going with the default value ("on"). Most HTTP flows are short and bursty, which means you'll hit the keepalive case quite often and you don't want to buffer interactive traffic. Cases where it may make sense to have it enabled? If you're serving large, non-interactive downloads and are trying to optimize for throughput + you're already hitting some NIC throughput limits.
Domyślnie NGINX włącza opcję TCP_NODELAY:
# Włącza tcp_nodelay:
# - wyłączenie algorytmu Nagle'a
# - moja rekomendacja
# - zachowanie domyślne
# - w kontekstach: http, server, location
tcp_nodelay on;
# Wyłącza tcp_nodelay:
# - włączenie algorytmu Nagle'a
tcp_nodelay off;
tcp_nopush #
Ta opcja jest dostępna tylko wtedy, gdy używasz sendfile (NGINX używa tcp_nopush dla żądań obsługiwanych przez sendfile). Powoduje, że NGINX próbuje wysłać swoją odpowiedź HTTP w jednym pakiecie, zamiast używać ramek częściowych. Jest to przydatne do dodawania nagłówków przed wywołaniem sendfile lub do optymalizacji przepustowości.
Zwykle używanie
tcp_nopushwraz z parametremsendfilejest bardzo dobrym rozwiązaniem. Są jednak przypadki, w których może spowolnić działania innych mechanizmów (szczególnie systemów pamięci podręcznej), dlatego po włączeniu tego parametru przetestuj i sprawdź, czy jest on faktycznie przydatny i nie ma impaktu na działanie serwera.
Parametr tcp_nopush włącza TCP_CORK (a dokładniej opcję gniazda TCP_NOPUSH we FreeBSD lub opcję gniazda TCP_CORK w systemie Linux), który agresywnie gromadzi dane i każe TCP czekać na usunięcie zatoru przez aplikację przed wysłaniem jakichkolwiek pakietów.
Jeżeli opcje TCP_NOPUSH/TCP_CORK (pamiętaj, że się różnią!) są włączone w gnieździe, proces nie wyśle danych, dopóki bufor nie zapełni się do ustalonego limitu. Dzięki temu pozwala aplikacji na kontrolę budowania pakietu, np. spakuje pakiet z pełną odpowiedzią HTTP. Aby przeczytać więcej na ten temat i zapoznać się ze szczegółami tej opcji oraz implementacji, polecam artykuł TCP_CORK: More than you ever wanted to know.
Mechanizm TCP_CORK blokuje dane, dopóki pakiet nie dotrze do granicy rozmiaru pakietu, co dla standardowego rozmiaru MTU daje: 1440 - (40 lub 60 bajtów nagłówka IP).
Spójrz na fragment kodu jądra Linux, które w miarę dokładnie opisuje działanie tego mechanizmu:
/* Return false, if packet can be sent now without violation Nagle's rules:
* 1. It is full sized. (provided by caller in %partial bool)
* 2. Or it contains FIN. (already checked by caller)
* 3. Or TCP_CORK is not set, and TCP_NODELAY is set.
* 4. Or TCP_CORK is not set, and all sent packets are ACKed.
* With Minshall's modification: all sent small packets are ACKed.
*/
static bool tcp_nagle_check(bool partial, const struct tcp_sock *tp,
int nonagle)
{
return partial &&
((nonagle & TCP_NAGLE_CORK) ||
(!nonagle && tp->packets_out && tcp_minshall_check(tp)));
}
Studiując działanie tego parametru, znalazłem informację, że tcp_nopush jest przeciwieństwem tcp_nodelay. Nie zgadzam się z tym, ponieważ, jak rozumiem, pierwszy agreguje dane bufora do jego pełnego wypełnienia, podczas gdy algorytm Nagle agreguje dane podczas oczekiwania na zwrotne potwierdzenie ACK, które ta ostatnia opcja wyłącza.
Może się wydawać, że tcp_nopush i tcp_nodelay wykluczają się wzajemnie, ale jeśli wszystkie dyrektywy są włączone, NGINX zarządza nimi bardzo mądrze:
- upewnia się, że paczki są pełne przed wysłaniem ich do klienta
- dla ostatniego pakietu
tcp_nopushzostanie usunięty, umożliwiając TCP wysłanie go natychmiast, bez opóźnienia 200 ms
Pamiętajmy też (spójrz na Tony Finch notes - ten gość opracował łatkę na jądro dla FreeBSD, która sprawia, że TCP_NOPUSH działa jak TCP_CORK) o innych istotnych rzeczach:
- w Linuksie
sendfile()zależy od opcji gniazda TCP_CORK, aby uniknąć niepożądanych granic pakietów - FreeBSD ma podobną opcję o nazwie TCP_NOPUSH
- gdy TCP_CORK jest wyłączony, wszelkie buforowane dane są wysyłane natychmiast, ale nie jest tak w przypadku TCP_NOPUSH
Domyślnie NGINX wyłącza opcję TCP_NOPUSH:
# Włącza tcp_nopush:
# - moja rekomendacja
# - w kontekstach: http, server, location
tcp_nopush on;
# Wyłącza tcp_nopush:
# - zachowanie domyślne
tcp_nopush off;
Wszystko razem czy jednak nie? #
Istnieje wiele opinii na ten temat. Moim zdaniem rozsądne jest włączenie wszystkich parametrów. Zacytuję jednak ciekawy komentarz Mixing sendfile, tcp_nodelay and tcp_nopush illogical?, który powinien rozwiać wszelkie wątpliwości:
When set indicates to always queue non-full frames. Later the user clears this option and we transmit any pending partial frames in the queue. This is meant to be used alongside sendfile() to get properly filled frames when the user (for example) must write out headers with a write() call first and then use sendfile to send out the data parts. TCP_CORK can be set together with TCP_NODELAY and it is stronger than TCP_NODELAY.
Podsumowując:
tcp_nodelay on;ogólnie jest w sprzeczności ztcp_nopush on;ponieważ wzajemnie się wykluczają- NGINX ma specjalne zachowanie, które przy ustawieniu
sendfile on;, używa TCP_NOPUSH do wszystkiego oprócz ostatniego pakietu - a następnie wyłącza TCP_NOPUSH i włącza TCP_NODELAY, aby uniknąć 200 ms opóźnienia ACK
Tak więc najważniejsze zmiany w konfiguracji związane z tymi parametrami to:
sendfile on;
tcp_nopush on; # dzięki temu tcp_nodelay nie ma tak naprawdę znaczenia