NGINX: Obsługa połączeń, zdarzenia oraz procesy
27 Jan 2019
best-practices epoll events http kqueue nginx processes
NGINX obsługuje różne metody przetwarzania połączeń, które zależą od używanej platformy/systemu. Zwykle nie ma potrzeby jawnego podawania metody przetwarzania żądań, ponieważ NGINX domyślnie zastosuje optymalną metodę dostępną w systemie, w którym jest uruchomiony.
Zasadniczo istnieją cztery typy multipleksowania zdarzeń:
- select - jest anachronizmem i nie jest zalecany, jednak jest instalowany na wszystkich platformach jako fallback
- poll - jest anachronizmem i nie jest zalecany
A także najbardziej wydajne implementacje nieblokującego wejścia/wyjścia:
- epoll - zalecane, jeśli używasz GNU/Linux; jest to wydajna metoda przetwarzania połączeń dostępna w systemie Linux od wersji 2.6
- kqueue - zalecane, jeśli używasz BSD (technicznie przewyższa
epoll); jest to wydajna metoda przetwarzania połączeń dostępna w FreeBSD 4.1+, OpenBSD 2.9+ i NetBSD 2.0+
Metodę select można włączyć lub wyłączyć za pomocą parametru konfiguracyjnego --with-select_module lub --without-select_module. Podobnie poll można włączyć lub wyłączyć za pomocą parametru konfiguracyjnego --with-poll_module lub --without-poll_module.
Jeżeli chcesz wskazać jawnie jedną z powyższych, wykorzystaj dyrektywę use:
use epoll;
Polecam zapoznać się ze świetnymi materiałami na temat dostępnych metod przetwarzania:
- Kqueue: A generic and scalable event notification facility [PDF]
- poll vs select vs event-based
- select/poll/epoll: practical difference for system architects
- Scalable Event Multiplexing: epoll vs. kqueue
- Async IO on Linux: select, poll, and epoll
- A brief history of select(2)
- Select is fundamentally broken
- Epoll is fundamentally broken
- I/O Multiplexing using epoll and kqueue System Calls
- Benchmarking BSD and Linux
- The C10K problem
Zobacz także test (z wykorzystaniem biblioteki libevent) porównujący każdą z metod:
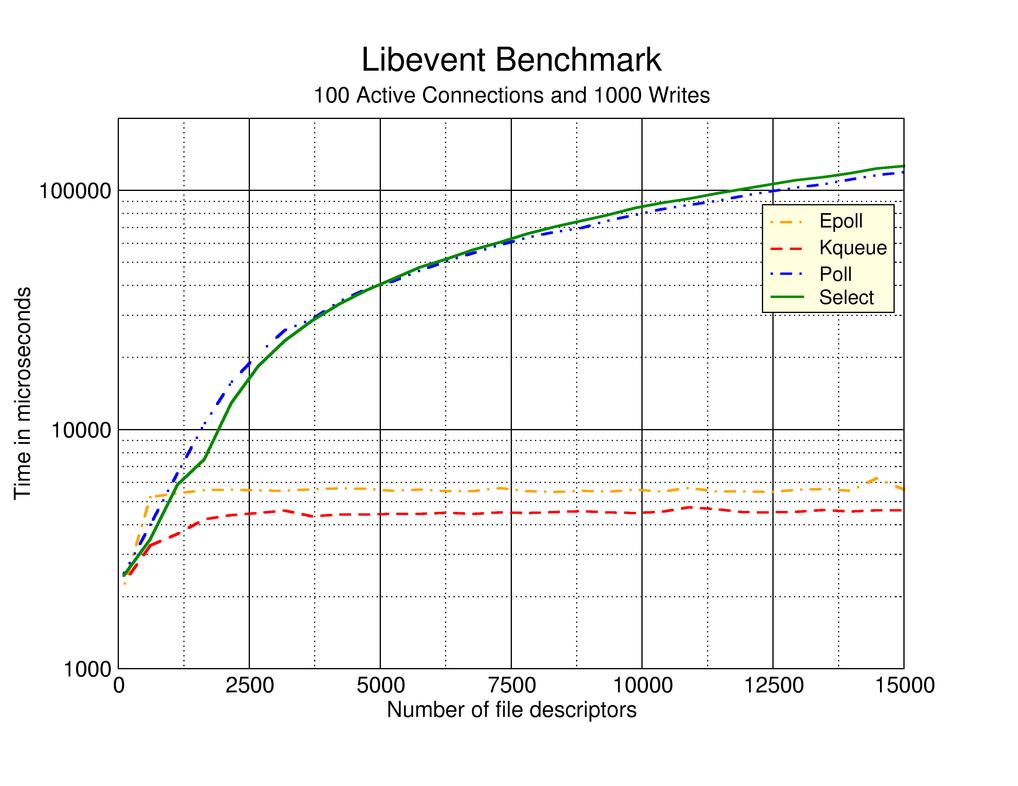
Jest to jedna z odpowiedzi, dlaczego warto uruchamiać produkcyjnie serwer NGINX na systemach BSD. Polecam obejrzeć Why did Netflix use NGINX and FreeBSD to build their own CDN?, a także zapoznać się ze świetnym artykułem opisującym wydajność serwera NGINX w systemie FreeBSD.
Jedynym skutkiem ubocznym wykorzystania metod epoll lub kqueue jest otwarte gniazdo i bufor z następną porcją danych. Jednak w porównaniu z dwoma pierwszymi metodami, można obsłużyć dużo więcej równoczesnych połączeń przede wszystkim ze względu na radykalnie niższy koszt samego procesu nawiązywania połączenia.
Rodzaje połączeń #
NGINX oznacza połączenia w następujący sposób (następujące informacje o stanie są dostarczane przez moduł ngx_http_stub_status_module):
- Active connections - bieżąca liczba aktywnych (otwartych) połączeń od klientów, w tym połączeń oczekujących i połączeń z backendami
- accepts - całkowita liczba zaakceptowanych połączeń od klientów
- handled - całkowita liczba obsługiwanych połączeń. Zasadniczo wartość parametru jest taka sama jak dla accepts, chyba że zostaną osiągnięte pewne limity zasobów (na przykład limit zdefiniowany za pomocą dyrektywy
worker_connections) - requests - łączna liczba żądań od klientów
- Reading - bieżąca liczba połączeń, w których NGINX odczytuje nagłówek żądania
- Writing - bieżąca liczba połączeń, w których NGINX zapisuje odpowiedź z powrotem do klienta (odczytuje treść żądania, przetwarza żądanie lub zapisuje odpowiedź do klienta)
- Waiting - bieżąca liczba bezczynnych połączeń klienta oczekujących na żądanie, tj. połączenia nadal otwarte w oczekiwaniu na nowe żądanie lub wygaśnięcie podtrzymania aktywności (w rzeczywistości Active connections - (Reading + Writing))
Połączenia oczekujące (Waiting) to w rzeczywistości połączenia podtrzymujące, które wykorzystują mechanizm Keep-Alive. Zwykle nie stanowią problemu. Jednak jeśli chcesz obniżyć ich liczbę, zmniejsz wartość dyrektywy keepalive_timeout.
Pamiętaj jednak, że ustawienie tej wartości zbyt wysoko spowoduje marnowanie zasobów (głównie pamięci), ponieważ połączenie pozostanie otwarte, nawet jeśli nie będzie żadnego ruchu, znacząco wpływając na wydajność. Myślę, że optymalna wartość powinna być jak najbliższa średniej czasu odpowiedzi. Możesz także stopniowo zmniejszać limit czasu (75s -> 50s, a potem 25s …) i zobaczyć, jak zachowuje się serwer.
Warto wspomnieć jeszcze o jednej rzeczy. Jeżeli chodzi o połączenia w stanie Writing, to ich zwiększona wartość może wskazywać na jeden z następujących problemów:
- zawieszone lub z zamykane procesy robocze — jest to możliwe lecz mało prawdopodobne, ponieważ spowodowałoby to również wzrost innych wartości, w szczególności połączeń w stanie Waiting
- wyciek z gniazda (ang. socket leaking) - zwykle są spowodowane połączaniami w stanie oczekiwania na przesłanie pakietu FIN kończącego połączenie (gniazdo w stanie CLOSE_WAIT). W celu szerszej diagnozy, sprawdź co zwraca polecenie
netstatbez filtragrep -v CLOSE_WAIT. Socket leak jest zgłaszany przez NGINX podczas płynnego zamykania procesu roboczego (na przykład po ponownym załadowaniu konfiguracji). Jeśli są jakieś wycieki, NGINX zapisze informację open socket … left in connection … do dziennika błędów
Co więcej, zaleca się wykonanie dodatkowych czynności:
- uaktualnij NGINX do najnowszej stabilnej/produkcyjnej wersji, bez żadnych dodatkowych modułów, i sprawdź, czy możesz wygenerować problem ponownie
- spróbuj wyłączyć protokół HTTP/2 i sprawdź, czy to rozwiązało problem
- sprawdź, czy NGINX nadal raportuje błąd open socket … left in connection … (informujący o przeciekach gniazda) po ponownym załadowaniu konfiguracji
Architektura zdarzeń #
Thread Pools in NGINX Boost Performance 9x! - polecam przeczytać ten artykuł będący świetnym wyjaśnieniem na temat wątków i ogólnie na temat obsługi połączeń przez serwer NGINX. Dobrym źródłem wiedzy na ten temat jest również Inside NGINX: How We Designed for Performance & Scale.
NGINX wykorzystuje architekturę sterowaną zdarzeniami, która w dużym stopniu opiera się na nieblokującym wejściu/wyjściu. Jedną z zalet operacji nieblokujących i asynchronicznych jest to, że można zmaksymalizować wykorzystanie pojedynczego procesora, a także pamięci, ponieważ wątek może kontynuować pracę równolegle. Efektem jest to, że nawet wraz ze wzrostem obciążenia, nadal możliwe jest wydajnie zarządzanie pamięcią i procesorem.
Istnieje bardzo dobre i do tego krótkie podsumowanie opisujące nieblokujące I/O. Polecam również: asynchronous vs non-blocking.
Standardowe operacje wejścia/wyjścia, np. read() i write() powodują zablokowanie wątku wykonującego daną operację do czasu jej zakończenia. Musimy wiedzieć, że operacje wejścia i wyjścia (I/O) mogą być bardzo powolne w porównaniu do przetwarzania danych. Bardziej wydajną metodą jest asynchroniczne wejście/wyjście (ang. asynchronous I/O), które pozwala na zarządzanie żądaniami wejścia/wyjścia w oderwaniu od wątków wykonywania. Podczas pracy, proces jest powiadamiany o zakończeniu operacji I/O a nie czeka, aż operacja się zakończy.
Zerknij na ten prosty diagram:
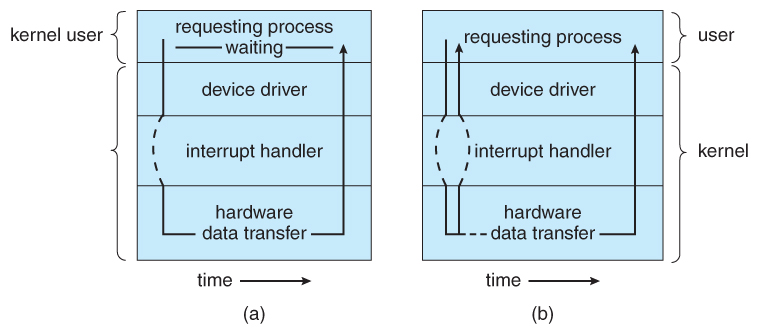
Opisuje on dwie metody wywołań. Pierwsza (a) związana z blokowaniem wywołań systemowych, które są wykonywane aż do momentu ich zakończenia. Druga (b) związana z nieblokującym wejściem/wyjściem, która umożliwia zarządzanie przez jeden wątek wieloma żądaniami I/O naraz i precyzyjną kontrolę nad rozpoczęciem i zakończeniem żądania wejścia/wyjścia.
Spójrz, co mówi na ten temat oficjalna dokumentacja:
It’s well known that NGINX uses an asynchronous, event‑driven approach to handling connections. This means that instead of creating another dedicated process or thread for each request (like servers with a traditional architecture), it handles multiple connections and requests in one worker process. To achieve this, NGINX works with sockets in a non‑blocking mode and uses efficient methods such as epoll and kqueue. Because the number of full‑weight processes is small (usually only one per CPU core) and constant, much less memory is consumed and CPU cycles aren’t wasted on task switching. The advantages of such an approach are well‑known through the example of NGINX itself. It successfully handles millions of simultaneous requests and scales very well.
Do obsługi wielu wątków/procesów operujących na współdzielonych danych (z poziomu NGINX obsługiwanych w jednym procesie roboczym) NGINX wykorzystuje wzorzec o nazwie reactor design pattern. Zasadniczo jest on jednowątkowy, ale może powoływać kilka procesów w celu wykorzystania wielu rdzeni.
Co ciekawe, NGINX nie jest aplikacją jednowątkową. To każdy proces roboczy jest jednowątkowy i może obsługiwać tysiące równoczesnych połączeń. Workery są wykorzystywane do uzyskania równoległości żądań w wielu rdzeniach. Gdy żądanie zostanie zablokowane, dany worker będzie pracował nad innym żądaniem.
NGINX nie tworzy nowego procesu/wątku dla każdego połączenia/żądania, ale uruchamia kilka wątków roboczych podczas uruchamiania. Robi to asynchronicznie za pomocą jednego wątku (wykorzystuje pętlę zdarzeń z asynchronicznym we/wy), zamiast programowania wielowątkowego.
W ten sposób operacje wejścia/wyjścia i operacje sieciowe nie stanowią wąskiego gardła (pamiętaj, że Twój procesor spędziłby dużo czasu, na przykład obsługując sieć). Wynika to z faktu, o czym już wspomniałem, że NGINX używa tylko jednego wątku do obsługi wszystkich żądań. Gdy żądania docierają do serwera, są one obsługiwane pojedynczo. Jednak gdy obsługiwany kod wymaga innej czynności, wysyła wywołanie zwrotne do innej kolejki, a główny wątek będzie nadal działał, a nie czekał.
Spójrz na porównanie obu mechanizmów:

Nieblokujące I/O jest jednym z powodów, dzięki któremu NGINX doskonale radzi sobie z bardzo dużą liczbą żądań.
Wiele procesów #
Jak już wspomniałem, NGINX używa tylko asynchronicznych operacji I/O, co sprawia, że blokowanie nie jest problemem. Tak naprawdę jedynym powodem, dla którego NGINX powołuje wiele procesów, jest możliwość pełnego wykorzystania systemów wielordzeniowych, wieloprocesorowych i hiperwątkowości. NGINX wymaga tylko wystarczającej liczby procesów roboczych, aby w pełni skorzystać z symetrycznego przetwarzania wieloprocesorowego (SMP). Jednak radzi sobie świetnie, gdy uruchomiony jest jeden proces roboczy (patrz: Why does one NGINX worker take all the load?).
Z oficjalnej dokumentacji:
The NGINX configuration recommended in most cases - running one worker process per CPU core - makes the most efficient use of hardware resources.
NGINX wykorzystuje niestandardową pętlę zdarzeń, która została zaprojektowana specjalnie dla niego — wszystkie połączenia są przetwarzane w wysoce wydajnej pętli uruchomionej w ograniczonej liczbie procesów jednowątkowych zwanych workerami. Procesy robocze przyjmują nowe żądania ze wspólnego gniazda (listen) i wykonują pętlę. W NGINX nie ma specjalnych mechanizmów dystrybucji połączeń do procesów roboczych — ta praca jest wykonywana przez mechanizmy jądra systemu operacyjnego, które powiadamiają workery.
Po uruchomieniu serwera NGINX tworzony jest początkowy zestaw gniazd. Procesy robocze stale akceptują, czytają i zapisują dane w gniazdach podczas przetwarzania żądań i odpowiedzi HTTP.
Jak widzisz, wszystko opiera się na multipleksowaniu zdarzeń i wykorzystaniu takich mechanizmów jak epoll() lub kqueue(). W ramach każdego procesu roboczego NGINX może obsłużyć wiele tysięcy równoczesnych połączeń i żądań na sekundę.
Zobacz prezentację Nginx Internals poruszającą wiele tematów związanych z wewnętrznymi elementami serwera NGINX.
Podsumowując, NGINX nie tworzy procesu ani wątku na połączenie (jak Apache), więc użycie pamięci jest bardzo konserwatywne i niezwykle wydajne w zdecydowanej większości przypadków. NGINX jest znacznie szybszy, zużywa mniej pamięci niż Apache i działa bardzo dobrze pod naprawdę dużym obciążeniem. Jest również bardzo przyjazny dla procesora, ponieważ nie ma ciągłego tworzenia i niszczenia procesów lub wątków.