Co jeśli kill -9 nie działa?
02 Jul 2017
kernel kill processes signals system
Wysyłanie sygnałów do procesów wykorzystując polecenie kill nie jest nowym tematem dla większości administratorów systemów i każdy na pewno wiele razy komunikował się w ten sposób zwłaszcza z nieposłusznymi procesami. W tym wpisie chciałbym poruszyć jednak ciekawych problem: a co jeśli kill -9 nie działa? Czy w ogóle istnieje możliwość, aby nie działał?

Obsługa sygnałów #
Sygnały są jedną z ważniejszych funkcji, z jakimi spotykamy się podczas omawiania tajników systemów operacyjnych. Poznanie ich działania jest ważne, ponieważ odgrywają ogromną rolę w zarządzaniu procesami. Ogólnie mówiąc, dzięki sygnałom jesteśmy w stanie komunikować się z procesami. Sygnał jest podstawowym mechanizmem służącym do powiadamiania procesów o wystąpieniu zdarzenia i możemy go traktować jako przerwę w działaniu programu, ponieważ w większości przypadków zakłóca on normalny przebieg jego wykonywania, a jego przybycie jest często nieprzewidywalne.
Jednym z poleceń, które pozwala na przesyłanie sygnałów do procesów pracujących w systemie operacyjnym jest polecenie
kill. Podobnymi poleceniami sąpkillorazkillall.
Wniosek z tego taki, że sygnały są pewną formą komunikacji międzyprocesowej. Możesz o nich pomyśleć jak o przerwaniach sprzętowych, jednak implementowanych przez system operacyjny. Przerwaniach, czyli czymś, co zatrzymuje wykonanie programu i tymczasowo przełącza się na procedurę obsługi sygnału. Co bardzo istotne (i jest to już w pewnym sensie odpowiedź na zadane w tytule postu pytanie) sygnały mogą być wysyłane synchronicznie jak i asynchronicznie do procesu lub do określonego wątku w tym samym procesie w celu powiadomienia go o jakimś zdarzeniu.
Standard POSIX definiuje 20 sygnałów. Definicje sygnałów dostępnych w jądrze Linux znajdują się w pliku signal.h. Dobra dokumentacja znajduje się także na stronie manuala:
man 7 signal.
Sygnał może być wysyłany z jądra do procesu, z procesu do procesu (do samego siebie) lub z procesu do innego procesu. Sygnał zwykle ostrzega proces o pewnym zdarzeniu, takim jak błąd segmentacji lub naciśnięcie klawisza Ctrl-C przez użytkownika. Każde ze zdarzeń ma swój własny numer sygnału, do którego zwykle odnosi się stała symboliczna, np. SIGTERM, który akurat oznacza prośbę o poprawne zamknięcie procesu.
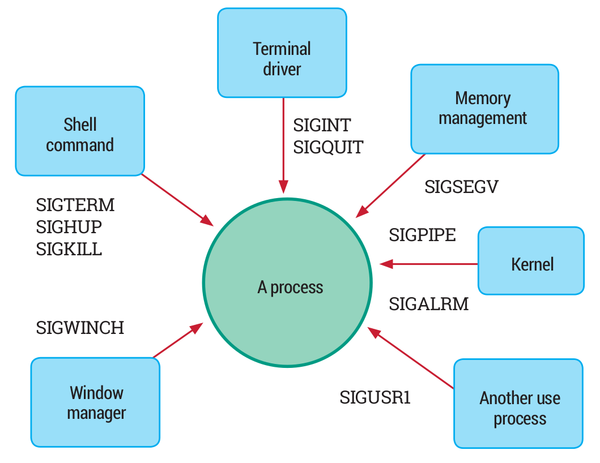
Poniżej znajduję się przykłady wykorzystania polecenia kill (domyślnie wysyłanym sygnałem jest SIGTERM):
# programowe (poprawne) zakończenie procesu: SIGTERM (15)
kill -15 <pid> <pid>
# zakończenie (wymuszone unicestwienie) procesu: SIGKILL (9)
kill -9 <pid>
# zakończenie procesu bez utraty danych: SIGSTOP (19)
kill --signal SIGSTOP <pid>
Jak już wspomniałem chwilę wcześniej, istnieją dwa rodzaje powiadomień. W tej chwili opiszę je w dużym skrócie, a bardziej szczegółowo zostaną opisane w następnym rozdziale:
-
powiadomienia asynchroniczne (ang. asynchronous notifications) - kiedy użytkownik wysłał sygnał przerwania do procesu, np. naciskając klawisz przerwania (zwykle Ctrl-C) na terminalu lub za pomocą komendy takiej jak
kill -
powiadomienia synchroniczne (ang. synchronous notifications) - kiedy jądro wysłało sygnał do procesu, np. gdy proces uzyskuje dostęp do lokalizacji pamięci pod nieprawidłowym adresem
Czyli już wiemy, że sygnał może zostać wygenerowany albo przez jądro wewnętrznie, albo zewnętrznie, np. przy pomocy użytkownika. Ogólnie rzecz biorąc, implementacja sygnału jest bardzo złożona i specyficzna dla konkretnego jądra. Poniższy opis potraktuj jako ogólne wprowadzenie.
Proces może otrzymać sygnał w wielu sytuacjach. Na przykład:
- z przestrzeni użytkownika z innego procesu, np. za pomocą polecenia takiego jak
kill - z przestrzeni użytkownika, gdy użytkownik przerywa program z klawiatury, kiedy wysyłany jest sygnał SIGINT
- po zakończeniu procesu potomnego, kiedy wysyłany jest sygnał SIGCHLD
- gdy program zachowuje się nieprawidłowo, dostarczany jest jeden z następujących sygnałów: SIGILL, SIGFPE, SIGSEGV
- kiedy wystąpił wyjątek sprzętowy i musi on zostać zgłoszony do procesu, np. odwołanie się do części pamięci, która jest niedostępna dla procesu
- kiedy pewne zdarzenia wystąpiły poza kontrolą procesu, ale mają na niego wpływ, np. kiedy dane wejściowe stały się dostępne w deskryptorze pliku lub kiedy przekroczono limit czasu procesora
Gdy procesor napotka wyjątek, zapisuje flagi i wskaźniki bieżącej instrukcji w stosie, przenosząc się następnie pod określony adres. W systemie z jądrem Linux ten adres zawsze wskazuje na jądro, w którym znajduje się moduł obsługi wyjątków. Procesor kończy swoją pracę i to jądro przejmuje kontrolę. Niezależnie jednak od sposobu wygenerowania wyjątku, kontekst procesu zostaje zapisany na stosie i następuje przejście do modułu obsługi wyjątków jądra.
Moduł obsługi wyjątków po otrzymaniu sygnału decyduje, który wątek powinien otrzymać sygnał. Następnie jądro, aby wysłać sygnał, ustawia wartość wskazującą na typ sygnału, np. SIGHUP. W tym momencie tworzona jest odpowiednia struktura danych, która zawiera informacje o sygnale. Kiedy sygnał jest wysyłany do procesu, jądro wyszukuje blok sterowania procesem i sprawdza tablicę akcji sygnału w celu zlokalizowania odpowiedniej procedury, która ma zostać wysłana do procesu.
Proces działający w przestrzeni użytkownika może reagować na dostarczenie sygnału na dwa sposoby:
- zignoruj sygnał
- wykonaj asynchronicznie określoną procedurę
Procedura obsługi sygnału to specjalnie dostosowana funkcja, która wykonuje odpowiednie zadania w odpowiedzi na dostarczenie sygnału. Widzisz, że proces może też zignorować sygnał (po cichu odrzucić), jednak istnieją dwa wyjątki od tej reguły. Nigdy nie może być ignorowany sygnał SIGSTOP powodujący zatrzymanie wykonywanego procesu, jak również SIGKILL powodujący zabicie procesu. Jest to sposób na pozostawienie administratorowi kontroli nad systemem.
Obsługiwane sygnały powodują wykonanie funkcji obsługi sygnału dostarczonej przez użytkownika. Program przeskakuje do tej funkcji, gdy tylko sygnał zostanie odebrany, a sterowanie programem zostanie wznowione na podstawie wcześniej przerwanych instrukcji.
Każdy sygnał oprócz dwóch wymienionych powyżej, może być obsługiwany przez proces samodzielnie za pomocą funkcji obsługi sygnału (ang. signal handler), która będzie wykonywana zawsze po nadejściu sygnału danego typu. Proces może również pozostawić obsługę sygnału dla jądra, które wykonuje wtedy akcję domyślną — najczęściej jest nią zakończenie wykonywania procesu z ewentualnym zrzutem zawartości pamięci. Może to być również zatrzymanie procesu (SIGSTOP), ale sygnał może być również domyślnie ignorowany (jest odrzucany przez jądro i nie ma wpływu na proces).
Jeśli proces nie określi jednego z tych sposobów obsługi sygnału, jądro wykonuje operację domyślną na podstawie numeru sygnału. Pięć możliwych domyślnych działań to:
- zignoruj sygnał
- zakończ proces
- zapisz kontekst wykonania i zawartość przestrzeni adresowej do pliku, po czym zakończ proces
- zawieś proces
- wznów wykonywanie procesu, jeśli został zatrzymany
Każdy sygnał ma bieżącą dyspozycję, która określa, jak zachowuje się proces po dostarczeniu sygnału. Poniżej znajduje się lista dyspozycji (opcji) z przykładowymi sygnałami dla każdej z nich:
Ign Default action is to ignore the signal
- SIGCHLD: Child stopped or terminated
Term Default action is to terminate the process
- SIGTERM: Termination signal
- SIGHUP: Hangup detected on controlling terminal or death of controlling process
- SIGKILL: Kill signal
Core Default action is to terminate the process and dump core
- SIGABRT: Abort signal from abort(3)
- SIGQUIT: Quit from keyboard
Stop Default action is to stop the process
- SIGSTOP: Stop process
Cont Default action is to continue the process if it is currently stopped
- SIGCONT: Continue if stopped
Sygnał może być zignorowany, co oznacza, że jest odrzucany przez jądro i nie ma wpływu na proces (proces tak naprawdę pozostaje nieświadomy, że zdarzenie w ogóle miało miejsce). Sygnał może także spowodować zakończenie działania procesu, np. przez nieprawidłowe zakończenie procesu, w przeciwieństwie do normalnego zakończenia procesu, które występuje, gdy program kończy się za pomocą exit(). Przy kończeniu działania procesu może zostać wykonany zrzut pamięci do pliku pomocny przy dalszej analizie ew. problemów. Za pomocą odpowiednich sygnałów działanie procesu może zostać także zawieszone lub wznowione.
Co ciekawe, po wygenerowaniu sygnału z powodu jakiegoś zdarzenia nie jest on bezpośrednio dostarczany do procesu i pozostaje w stanie pośrednim zwanym stanem oczekującym. Jest to wymagane w scenariuszach, gdy np. procesor nie jest dostępny dla procesu. W takiej sytuacji oczekujący sygnał jest dostarczany, gdy tylko proces zostanie zaplanowany do następnego uruchomienia.
Jeśli proces jest aktualnie wykonywany (jest w kolejce TASK_RUNNING) to nie może zareagować natychmiast po otrzymaniu sygnału, ale dopiero gdy będzie wykonywany po raz kolejny. Jest to spowodowane faktem, że funkcja odpowiedzialna m.in. za obsłużenie sygnałów jest wywoływana w momencie zakończenia dowolnej z funkcji systemowych.
Należy także wiedzieć, że sygnał może zostać wysłany do określonego procesu z określonym identyfikatorem (pid > 0) lub do każdego procesu w tej samej grupie procesów (pid = 0).
Sygnały synchroniczne i asynchroniczne #
Z natury nie ma sygnałów synchronicznych i asynchronicznych, ale niektóre sygnały są dostarczane asynchronicznie, a inne mogą być dostarczane synchronicznie lub asynchronicznie. Dostarczanie jest zawsze takie samo: procedura obsługi sygnału wywoływana jest w trybie użytkownika, jeśli jest ustawiona. Jeśli nie jest ustawiona, używane jest zachowanie domyślne, czyli proces kończy swoje działanie, z wyjątkiem niektórych sygnałów, które mogą być zignorowane lub zatrzymywane.
Co to jednak znaczy, że powiadomienie jest asynchroniczne? Oznacza to, że jądro może potrzebować trochę czasu, aby dostarczyć sygnał. Zwykle dostarczenie sygnału zajmuje najwyżej kilka mikrosekund. Jeśli na przykład coś zablokowało sygnał, będzie on w kolejce, dopóki nie zostanie odblokowany. Tak naprawdę wszystkie sygnały, w tym SIGKILL, są dostarczane asynchronicznie.
Sygnały są uważane za dostarczane asynchronicznie, jeśli ich przybycie spowodowane jest przyczyną zewnętrzną (najczęściej są związane z innymi procesami) i odnoszą się do bieżącego kontekstu wykonania. Mogą być na przykład wywołane przez polecenie kill lub przez przerwanie z urządzenia zewnętrznego. Wywołanie z programu w celu podniesienia sygnału zablokuje program, dopóki połączenie nie powróci. W takim przypadku z punktu widzenia procesu istnieje czas pomiędzy wysyłaniem a dostarczaniem: proces może wykonywać w tym czasie wiele rzeczy.
Natomiast sygnały dostarczane synchronicznie pojawiają się, gdy wykryta zostanie wewnętrzna przyczyna, dla której należy wysłać sygnał — czyli praktycznie natychmiast. Oznacza to też, że proces/wątek wykonuje pewną instrukcję, a wykonanie to spowodowało przerwanie przez błąd, np. błąd segmentacji. W takim przypadku jest to aktualnie wykonywany kod (instrukcja), który jest źródłem usterki, następnie sygnał jest momentalnie emitowany, a na koniec dostarczany. W tym przypadku, z punktu widzenia procesu, nic nie dzieje się pomiędzy emisją a dostawą. Jednak za każdym razem, gdy występuje przerwanie synchroniczne, oznacza to coś złego w procesie.
Myślę, że ciekawe porównanie znajduje się też tutaj (jest zaczerpnięte z książki The Linux Programming Interface: A Linux and UNIX System Programming Handbook):
Signal delivery is typically asynchronous, meaning that the point at which the signal interrupts execution of the process is unpredictable. In some cases (e.g., hardware-generated signals), signals are delivered synchronously, meaning that delivery occurs predictably and reproducibly at a certain point in the execution of a program.
A co jeśli kill -9 nie działa? #
Tak naprawdę kill -9 (SIGKILL) działa zawsze, pod warunkiem, że istnieją warunki i możliwość (pozwolenie) na zabicie procesu. Jednak zabicie procesu w taki sposób nie gwarantuje natychmiastowej reakcji, a dzieje się tak z powodu:
- dostarczania asynchronicznego, które może wprowadzić pewne opóźnienie
- pewnego opóźnienia związanego ze stanem, w jakim znajduje się proces, np. jeśli proces jest aktualnie „na procesorze”
- zadań będących w stanie nieprzerwanego uśpienia, których co do zasady nie można zakończyć
- procesów, które pozostają w pamięci i są „martwe” (zombie)
Jeżeli zostanie spełniony jeden z tych punktów, polecenie kill -9 nie zadziała lub zadziała, ale nie od razu. Z drugiej strony, pewnym potwierdzeniem tego, że SIGKILL (zawsze) działa, jest to, że zwykle procesy nie mogą blokować tego sygnału. Wyjątkiem jest oczywiście jądro, które blokuje wszystkie sygnały, oraz procesy, które wykonują instrukcje w jego imieniu, np. gdy generują wywołania systemowe.
Czasami możemy odnieść wrażenie, że wywołanie systemowe blokowane jest w nieskończoność. Może się tak dziać w przypadku jakiegoś błędu, co skutecznie uniemożliwi zakończenie procesu. Jednak tak naprawdę zostanie on zakończony, jeśli kiedykolwiek zakończy się wywołanie systemowe.
Proces zablokowany w wywołaniu systemowym znajduje się w stanie nieprzerwanego uśpienia i jest umieszczany w kolejce TASK_UNINTERRUPTABLE (D). Procesy w tym stanie generalnie nie mogą zostać zabite przez odpowiedni sygnał, ponieważ ich nie obsługują. Spotkałem się jednak z różnymi definicjami na ten temat, dlatego myślę, że procesy będące w tym stanie nie mogą zostać zabite natychmiast lub w niektórych przypadkach w ogóle. Klasycznym przypadkiem długiego nieprzerwanego uśpienia są procesy, które próbują uzyskać dostęp do plików sieciowych, np. wykorzystując protokół NFS.
Zabicie procesu, który znajduje się w trybie nieprzerwanego uśpienia może się nie powieść, jeśli wywołanie systemowe nigdy z niego nie wyjdzie.
Innym typem procesów, których nie można zabić (ponieważ są już „martwe”), są procesy zombie (przy okazji polecam przeczytać Alternative way to kill a zombie process oraz How to kill a defunct process with parent 1). Są one niczym więcej niż wpisem w tabeli procesów, przechowywanym tak, aby proces macierzysty mógł zostać powiadomiony o jego zamknięciu. Stanie się to jednak dopiero, gdy proces nadrzędny potwierdzi zamknięcie takiego procesu lub sam zostanie zamknięty. Tak naprawdę, jedyną rzeczą, którą zużywają procesy zombie, są wpisy w tabeli procesów (identyfikatory).
Jeśli takie procesy gromadzą się w bardzo szybkim tempie, na przykład, jeśli niewłaściwie zaprogramowane oprogramowanie serwera tworzy procesy zombie pod obciążeniem, to cała pula dostępnych PID ostatecznie zostanie przypisana do procesów zombie, uniemożliwiając uruchomienie innych procesów.
Poprawne zamykanie procesów #
Można powiedzieć, że kill -9 jest wyjątkowy, ponieważ program go nie otrzymuje — jest on kierowany prosto do jądra, które następnie może zamknąć proces przy pierwszej możliwej okazji. Oczywiście alternatywnym i bardziej przyjaznym rozwiązaniem jest wysłanie sygnału SIGTERM (15), który informuje proces o jego zakończeniu. Chodzi o to, aby dać procesowi szansę na posprzątanie po sobie (zwolnienie zasobów), tak aby np. nie zostawił tymczasowych plików i nie uszkodził tych, na których pracował, pozamykał otwarte połączenia czy poinformował procesy potomne, że kończy pracę.
Jeżeli proces nie odpowiada, wtedy z pomocą powinien przyjść omawiany SIGKILL. Jednak w przypadku tego sygnału, musimy pamiętać, że wymusza on w sposób bezkompromisowy zakończenie procesu, co w konsekwencji prowadzi do tego, że nie można wykonać czyszczenia i zwolnienia zasobów.
Chociaż SIGKILL jest zdefiniowany w tym samym pliku nagłówka sygnału co SIGTERM, proces nie może go zignorować (nigdy nie ma możliwości uchwycenia sygnału i działania na nim). W rzeczywistości proces nie jest nawet informowany o sygnale SIGKILL, ponieważ sygnał trafia bezpośrednio do jądra.
Użycie kill -9 ogólnie nie jest zalecane. Przytoczę tutaj pewien świetny cytat, który dokładnie pokazuje, o co chodzi:
Don't use kill -9. Don't bring out the combine harvester just to tidy up the flower pot.
Po więcej informacji odsyłam do artykułu Useless use of kill -9. Najbardziej zalecanym sposobem poinformowania procesu o jego zakończeniu jest wysłanie sygnału SIGTERM. Gdy proces otrzyma powiadomienie, może się zdarzyć kilka różnych rzeczy:
- proces może nie zareagować na ten sygnał
- proces może zostać natychmiast zatrzymany
- proces może się zatrzymać po krótkim opóźnieniu po oczyszczeniu zasobów
- proces może działać w nieskończoność
- może robić coś zupełnie innego
Natomiast jedynym przewidywalnym rozwiązaniem pozbycia się „niezabijalnych” procesów jest ponowne uruchomienie systemu. Jeśli kill -9 nie zabije procesu, oznacza to, że utknął on gdzieś w jądrze. Możemy oczywiście próbować dowiedzieć się, co jest tego powodem, np. za pomocą takich narzędzi jak strace, ltrace czy gdb, jednak co do zasady nie możemy nic zrobić. Powodem tego jest to, że taki proces na coś czeka (np. sieć lub dyski), a logika niezbędna do czystego zatrzymania takiego procesu po prostu nie istnieje. Procesy zombie i procesy zatrzymane w nieprzerwanym śnie nie mogą być zatrzymane przez jądro. Wymagane jest ponowne uruchomienie serwera, aby usunąć te procesy z systemu.
Jeżeli restart systemu nie może zostać wykonany, można podjąć próby pozbycia się takich procesów w następujący sposób:
- zatrzymanie działania jego rodzica (który „trzyma” problematyczny proces)
- wysłanie sygnału SIGPWR w celu zasymulowania awarii zasilania
Nigdy jednak tego nie robiłem i nie wiem, czy oba rozwiązania pozwalają rozwiązać problem (co nie zmienia faktu, że są ciekawe).
Dodatkowe zasoby #
- Understanding the Linux Kernel, Third Edition
- Linux System Programming: Talking Directly To The Kernel And C Library
- The Linux Programming Interface: A Linux and UNIX System Programming Handbook
- Linux Device Drivers, 3rd Edition
- POSIX signals
- All about Linux signals
- The Linux Signals Handling Model
- The Linux Kernel: Signals & Interrupts [PDF]
- The GNU C Library